[CS229] 10: Advice for applying machine learning techniques
Tag: python, machine learning
2018-11-17
10: Advice for applying machine learning techniques
- 算法debug:
- 更多的训练样本 =》fix high variance(underfit)
- 减少特征数量 =》fix high variance
- 获得额外的特征 =》fix high bias(overfit)
- 增加高维(组合)特征 =》fix high bias
- 增大 lambda =》fix high bias
- 减小 lambda =》fix high variance
- 机器学习诊断:
- 算法在什么样问题是work的或者不work的
- 需要耗时构建
- 指导提高模型的性能
- 模型评估:
- 训练集效果好(错误低),但是不能很好的在新数据集上。可能存在过拟合,低维(二维)可以直接画,但是对于多维数据不合适。
- 分训练集和测试集,训练集构造模型,在测试集上预测,评估模型效果。
- 模型选择:
- 对于不同的模型,构建训练集+验证集+测试集,前两者用于构建模型,测试集计算错误评估效果
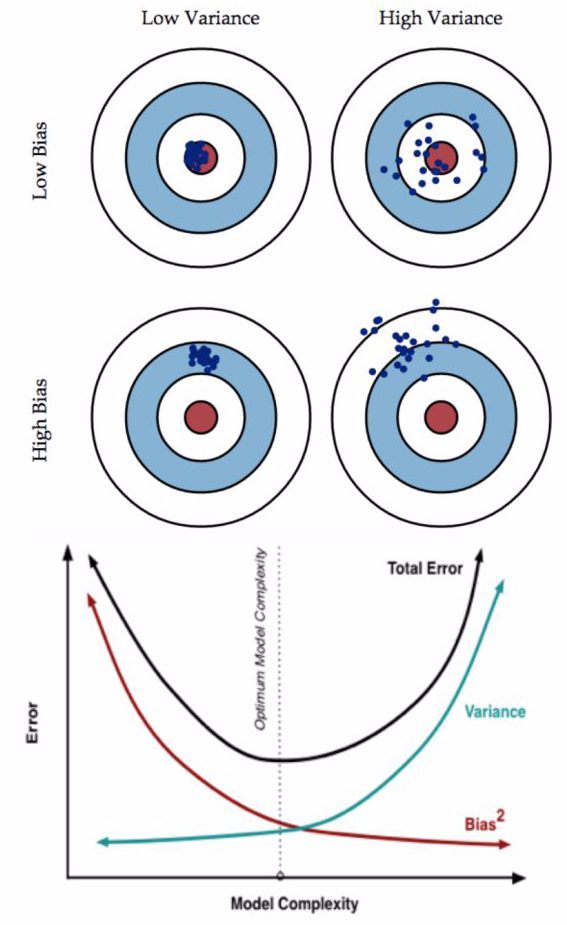
- 模型高偏差(bias)还是高差异(variance):
- high bias:underfit,比如在训练集和验证集上错误都很高,且两者很接近。
- high variance:overfit,比如在训练集上错误很低,但是在验证集上错误很高。
- 正则化与bias、variance:
- 正则化参数:lambda(平衡模型的性能和复杂度)
- 小的lambda,模型很复杂,可能会overfit,high variance
- 大的lambda,效果不很好,可能是underfit,high bias
- 选择不同的lambda值,起到正则化的效果,控制模型的复杂度。用训练集、验证集和测试集的错误值,选取合适的lambda值。
- 学习曲线(learning curve):
- 根据学习曲线判断如何提高模型的效果
- 学习曲线: 样本数量 vs 模型在训练集和验证集上的错误(error)
- 如果是模型high bias(underfit),训练集的误差随样本量增大逐渐增大到平稳,验证集的误差随样本量增大逐渐减小到平稳。【用更多的训练数据不会提升效果】
- 如果模型是high variance(overfit),【用更多的训练数据会提升效果】
- 神经网络和过拟合:
- 小网络:少的参数,容易欠拟合
- 大网络:多的参数,容易过拟合(模型太复杂,不易推广到新的数据)
- 大网络的过拟合可解决方式:正则化
- 知乎:Bias(偏差),Error(误差),和Variance(方差):
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/CS229-10-advice.html
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me