17: Large Scale Machine Learning
- 为什么需要大的数据集?
- 模型取的好效果的最佳途径:小偏差的算法,在大数据上训练
- 当数据集足够大时,不同的算法,效果相当
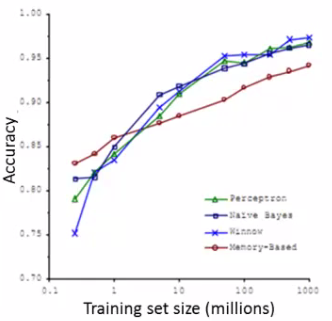
- 问题:大数据集带来的计算问题,计算资源消耗巨大
- 大数据集的学习:
- 训练是需要优化参数,计算误差,下图是逻辑回归单个样本的误差,如果是大数据集(比如样本数m=1000000),需要计算1000000次。这个计算加和的过程本身就很耗计算资源:

- 可能解决方案:1)使用其他的方法,2)优化避免加和操作
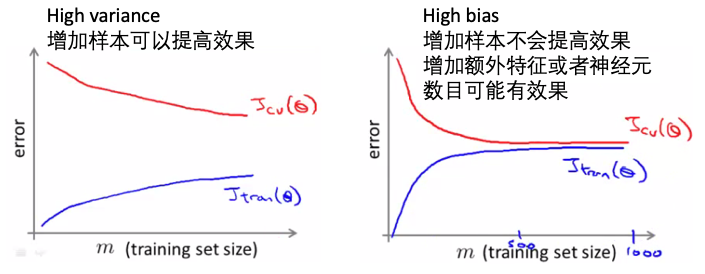
- 优先考虑:小数据集训练。通常可能效果不好,有的能到达跟大数据集相当的效果。如何评估小数据集是否足够,可以看学习曲线(训练集数量 vs 误差):
- 训练是需要优化参数,计算误差,下图是逻辑回归单个样本的误差,如果是大数据集(比如样本数m=1000000),需要计算1000000次。这个计算加和的过程本身就很耗计算资源:
- batch梯度下降:
- 损失函数(这里以线性回归为例):
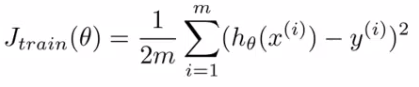
- 在优化时,梯度下降要应用于每一个参数\(\theta\),而其更新的大小,根据下面的公式,是要依赖于所有的样本的(每个样本都要贡献于这个梯度的更新):
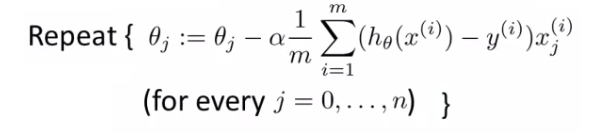
- 优点:能够达到全局最小
- 缺点:同时要看所有的样本,计算消耗大
- 损失函数(这里以线性回归为例):
- 随机梯度下降:
- 单个样本的损失(只看\(\theta\)在单个样本上的损失表示):

- 总的损失(和上面的batch梯度递减的损失函数是一样的,最终的目的是一样的):

- 算法步骤1:训练集数据随机打乱。保证\(\theta\)的移动是不存在bias的。
- 算法步骤2:从1到m(样本数),每次更新所有的\(\theta\),但是这里的\(\theta\)是只与一个样本有关的【update the parameters on EVERY step through data】。\(\theta\)值在不断的优化,但是每次都是对于一个样本最优,不是对全部样本最优:

- 下面是批梯度下降和随机梯度下降的比较:
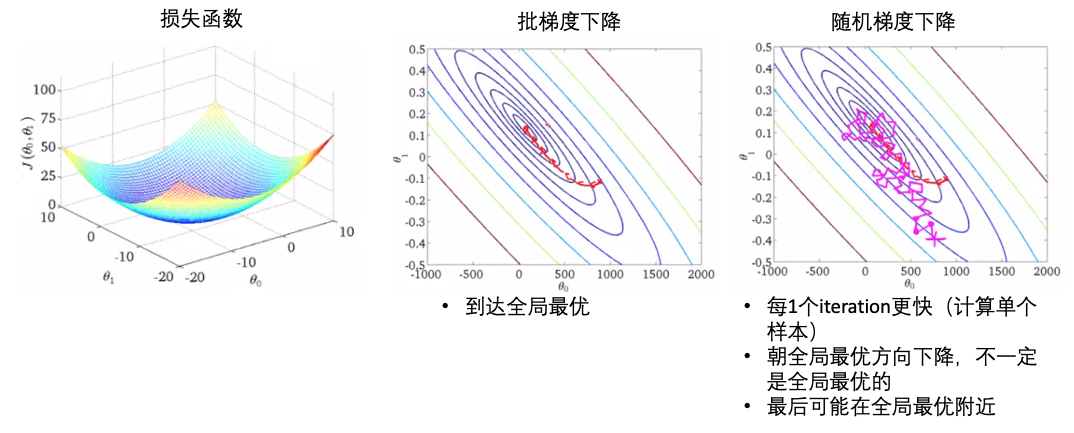
- SGD不一定能到达全局最优,可以运行多次在整个数据集上。
- 单个样本的损失(只看\(\theta\)在单个样本上的损失表示):
- 小批量梯度下降(mini-batch):
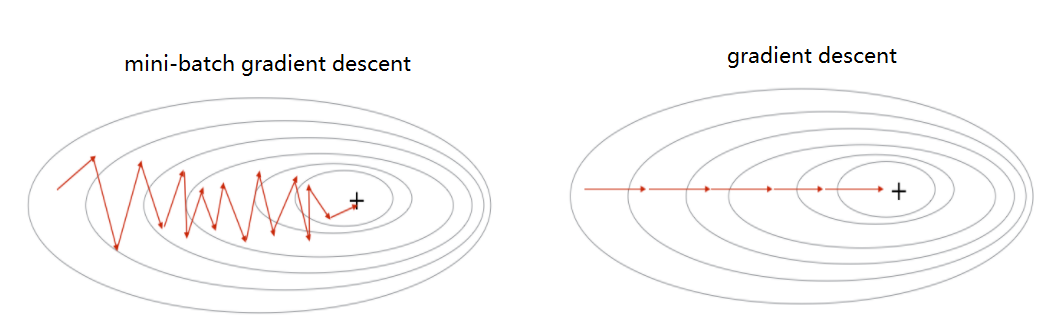
- 小批量 vs 随机梯度下降:
- 向量化计算,实现更高效,并行计算
- 需要优化参数b(batch size)
- 随机梯度和批量梯度下降都是小批量梯度下降的特例
- 随机梯度下降的收敛:
- 【批量梯度下降】:直接看每一次的迭代
- 【随机梯度下降】:比如可以看每1000次的迭代的损失变化
- 检查学习曲线:迭代次数 vs loss,看模型随迭代次数的收敛情况:
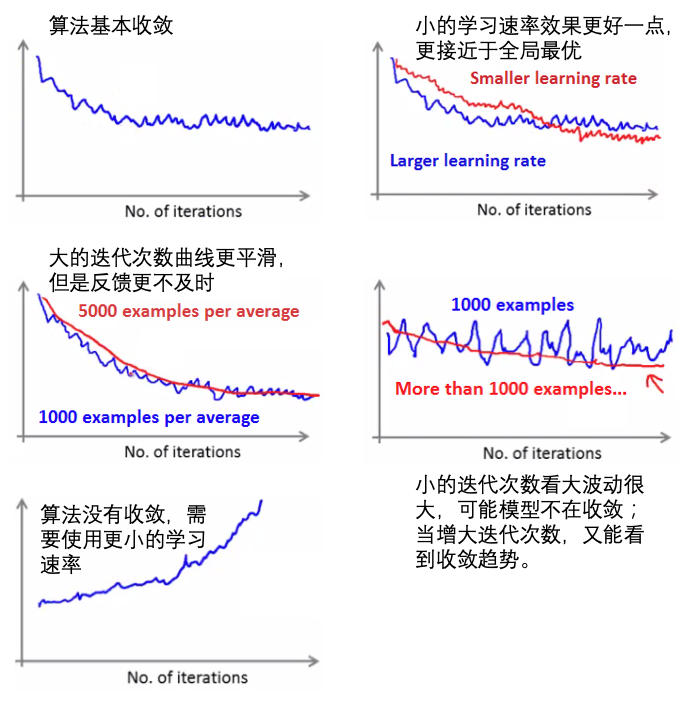
- 学习速率:
- SGD中的学习速率通常比批地图下降更小,因为SGD的梯度更新的差异性(variance)更大(每次都是随机选取一个样本?)。
- 通常学习速率是常量,但是为了达到全局最优,可以缓慢的减小学习速率
- 通常:α = const1/(iterationNumber + const2)
- 在线学习(online learning):
- 持续的数据流
- 例子1:物流价格的确定。有一个在线的服务,记录什么样的价格,物品等(作为特征)可以保证交易的成果。不断有新的订单,作为新的数据更新模型。
- 例子2:商品搜索。根据搜索关键词呈现10个商品,是否继续点击(click through rate,CTR),从而收集数据和标签,更新训练模型。
- Map reduce:
- 基本框架:

- 在梯度下降的计算中:

- Hadoop:a good open source Map Reduce implementation
- 基本框架:
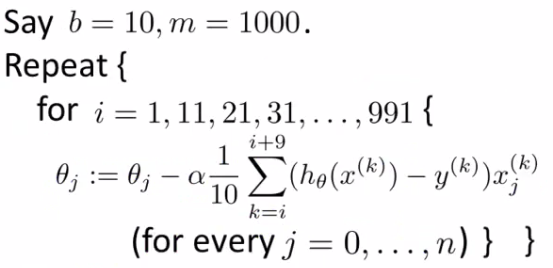
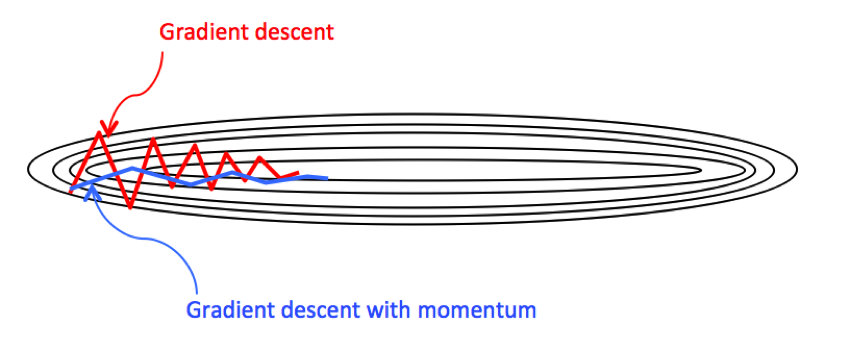
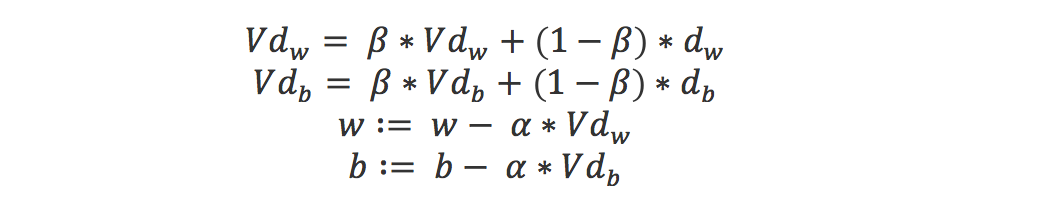
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/CS229-17-large-scale-machine-learning.html
Previous:
Stanford deep learning
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me