目录
计算机视觉中关于图像的基本问题
- 图像分类:识别图像包含什么类别的物体。图像级别
- 目标检测:框出检测到的物体
-
语义(图像)分割:对每个像素点进行分类,从而得出一个物体的准确轮廓。像素级别,因为要判断每个像素点的类别,比如某个像素点是属于汽车、人还是背景等。没有物体,只有像素。

- CNN图像语义分割的流程:
- 下采样+上采样:卷积、去卷积、resize
- 多尺度特征融合:点相加、通道维度拼接
- 获得像素级别的分割map:对每个像素点进行分类
CNN为什么不能用于语义分割?
- CNN很强大:
- 多层结构,可自动学习多层次的特征
- 浅卷积层学习局部特征
- 深的卷积层学习更抽象的特征
- 不能语义分割:
- 在卷积和pooling过程中丢失图像信息,因为一般feature map size是逐渐变小的
- 不能很好的指出物体的具体轮廓、哪个像素属于哪个具体的物体
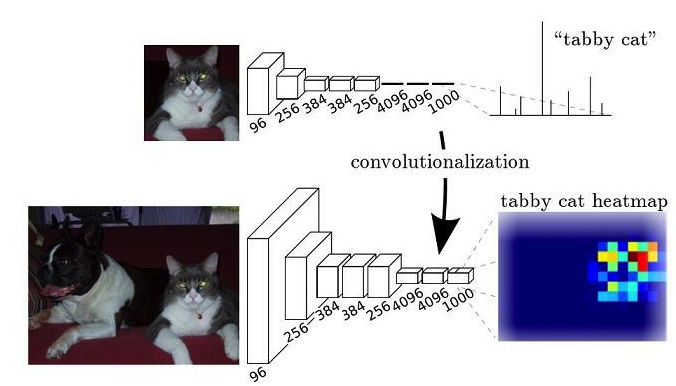
- 无法做到精确分割。CNN网络一般最后加入全连接层,经过softmax获得每个类别的概率。此概率信息是一维的,即对应整个图像属于的类别,不能标识每个像素点。

语义分割之FCN
- FCN:全卷积网络
- 网络中只有卷积层没有全连接层,所以称为全卷积网络
- 将一般CNN中的全连接层换为卷积层
-
利用上采样和反卷积到原始图像大小,即可做像素级别的分类
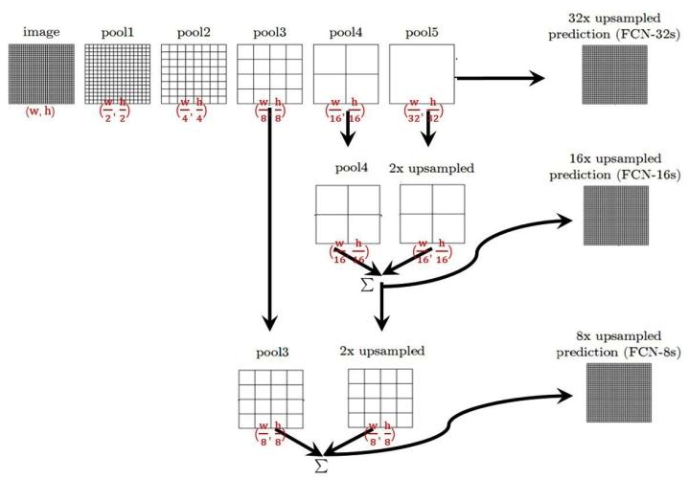
- 经典的网络结构:
- FCN-32:对pool5的特征进行32倍上采样,再做softmax
- FCN-16:有融合,(1)对pool5进行2倍上采样,将(2)pool4和(1)进行点相加,在对相加融合的特征进行16倍上采样,最后做softmax
- FCN-8:有融合,(1)对pool5进行2倍上采样,将(2)pool4和(1)进行点相加,再对相加融合的特征进行2倍上采样,然后和pool3进行点相加,最后进行8倍上采样,做softmax
- FCN网络效果的比较
- 可以看到:FCN-32s < FCN-16s < FCN-8s
- 结论:使用多层特征融合,有利于提高分割的准确性

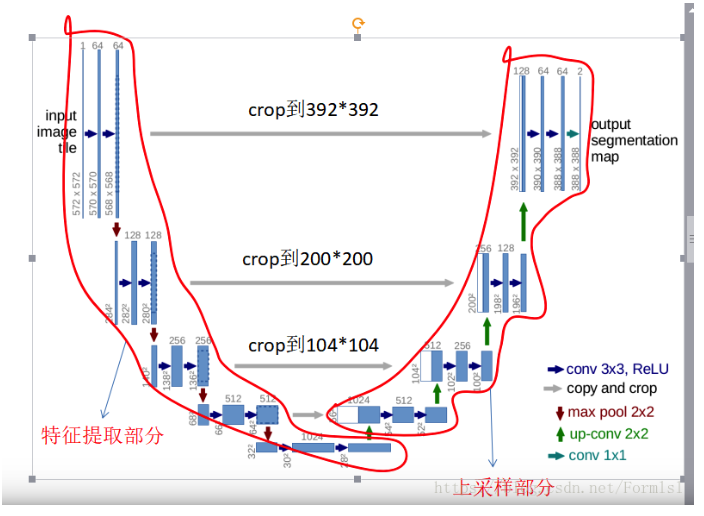
语义分割之U-Net
- U-Net:
- 很小的分割网络,没有使用空洞卷积,结构简单
- 网络结构像U型,所以称为U-Net
- 网络结构:
- 特征提取部分:类似于VGG
- 上采样部分:每上采样一次,就和特征提取对应的通道数进行融合。
- 融合方式:拼接,就是将特征在通道维度拼接在一起,形成更厚的特征。
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/U-net.html
Previous:
Install GPU based tensorflow
Next:
稀疏编码
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me