目录
- 目录
- 为什么选择序列模型?
- 数学符号
- RNN模型
- 通过时间的反向传播
- 不同类型的RNN
- 语言模型和序列生成
- 对新序列采样
- RNN中的梯度消失
- GRU门控循环单元
- LSTM长短期记忆
- 双向神经网络
- 深层RNN
- 参考
为什么选择序列模型?
- 在语音识别、自然语言处理等领域引起变革
- 例子:
- 语音识别:输入音频片段,输出文字
- 音乐生成:输入空集、数字等,输出序列
- 情感分类:输入语句,输出对应的评价等级
- DNA序列:输入DNA序列,输出匹配的蛋白质
- 机器翻译:输入一种语言,输出另一种语言
- 视频行为:输入视频祯,输出识别出的行为
- 名字识别:输入语句,输出不同实体的名称

- 注意:
- 问题归纳:都是使用标签数据(X,Y)作为训练集的监督学习
- 输入和输出不一定都是序列
- 输入和输出的长度不一定相等
数学符号
- 都是序列模型,以输入是序列为例看怎么表示数据
- 例子:
- 命名实体识别问题
- 查找不同类型的文本中的人名、公司名、时间、地点、国家名和货币名等
- 输入数据:\(x^{<t>}:x^{<1>},x^{<2>}...\)如此表示顺序索引的单词
- t表示索引序列的位置,不管输入是不是时序序列,均可这样表示
- 输入序列长度:\(T_x\)
- 输出数据:\(y^{<t>}:y^{<1>},y^{<2>}...\)
- 输出序列长度:\(T_y\)
- 加入样本信息:\(x^{(i)<t>}\),训练样本i的序列中的第t个元素
- 序列长度:\(T_y^{(i)}\),第i个样本的输出序列的长度
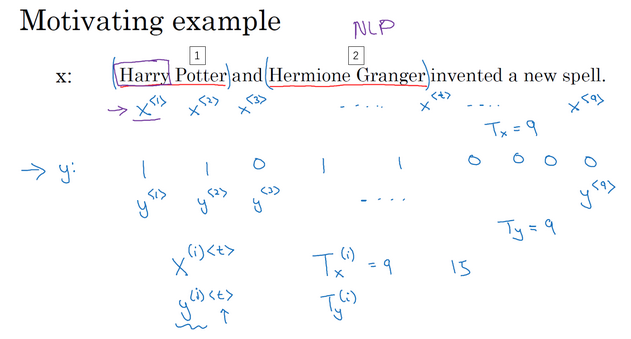
- 单词表示:
- 词典表示法
- 每个单词使用所选词典的one-hot表示,此词所在index为1,其他index为0
- 所以如果选用的词典是10000,那么对于一个序列长度为9的句子,其表示就是:9个长度为10000的向量
- 遇到不在词典中的单词,可创建新的标记叫做Unknown Word的伪造单词,
作为标记 [](https://raw.githubusercontent.com/Tsinghua-gongjing/blog_codes/master/images/20191010144812.png)
RNN模型
- 为什么不使用标准神经网络模型?
- 对于序列问题,为什么不使用标准的神经网络模型,一层层的计算?
- 问题1:不同的样本其长度不一定是相同的。不是所有的例子都有着相同的输入长度或者输出长度。标准网络的表达方式不太好。
- 问题2:从不同位置学到的特征不能共享。比如从某个例子中学到位置1出现的词是人名,那么这个词出现在其他的位置,应该也能学到其是人名。
- 问题3:参数巨大。比如词向量进行one-hot编码,如果词典大小是10000,那么每个词的表示就是这么大,一个10个单词的句子就是10x10000大小。全连接下的参数会非常巨大。

- RNN:
- 每一个时间步,RNN网络传递一个激活值到下一个时间步用于计算
- 零时刻:构造一个激活值,通常是零向量
- 每个时间步的参数是共享的

- 单向RNN:只用了序列中之前的信息做出预测
- 双向RNN:可以用到前后的序列信息做出预测
- 例子:上面的语句中,如果只根据前面的单词信息,不知道 Teddy 究竟是什么,但是使用前后的信息后,就知道这是不是个人名了。
- RNN前向传播计算:
- 根据每个时间点的输入,前一个时间点的激活值,来计算当前时间点的激活值和预测值
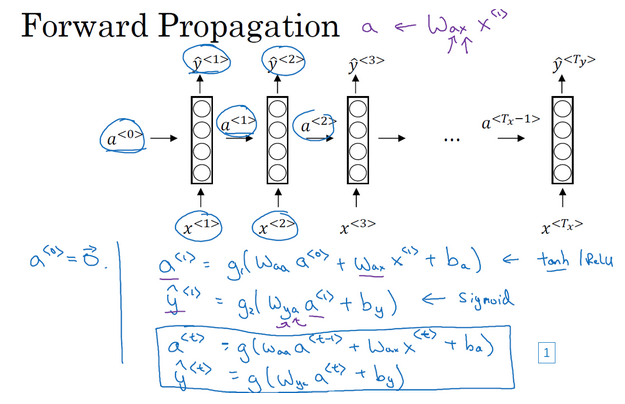
- RNN中常用的激活函数是tanh
- 计算的简化表示:对于前一时间点的激活值要乘以一个参数,当前时间点的输入也要乘以一下参数,所以可以把这部分进行合并表示(就是下图中的编号1可表示为编号2,编号345是拆开了说为什么是相等的)

- 根据每个时间点的输入,前一个时间点的激活值,来计算当前时间点的激活值和预测值
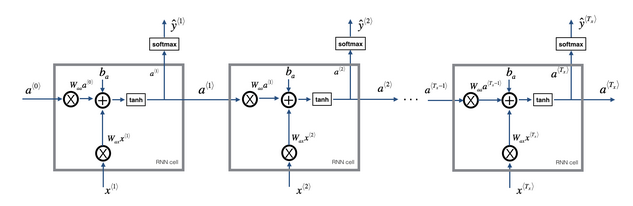
- 前向传播示意图:
- 这里是对每个cell展开了具体的计算流程示意图
- 先计算激活值,再根据激活值计算预测值。时间t时刻的预测值是依赖于激活值的计算的。
通过时间的反向传播
- 因为这里的网络是按照时间进行传递的,所以反向传播相当于时间回溯了
- 下图中蓝色的流就代表前向传播,红色的流代表反向传播

- 例子:计算a1,y1
- 输入:x1
- 前一刻的激活值:a0
- 计算a1还需要:Wa和ba,因为a1=g(Wa * [a0, x1] + ba),这里的Wa和ba在之后的每一个时间步也是需要用到的,所以是需要学习的参数
- 计算y1还需要:Wy和by,因为y1=g(Wy * a1 + by),这里的Wy和by在之后的每一个时间步也是需要用到的,所以是需要学习的参数
- 损失函数:
- 逻辑回归损失函数(交叉熵损失函数)
- 整个序列的损失:每一个时间步上的损失的和
- 反向传播示意图:
- 总损失下使用梯度更新参数

- 总损失下使用梯度更新参数
不同类型的RNN

- 一对一:标准的小型神经网络,输入x输出y
- 一对多:一个输入,多个输出
- 音乐生成。输入只有一个,比如音乐类型等,甚至是空的输入,但是需要输出一连串的音符
- 多对一:很多的输入,最后一个时间上输出
- 情感分析。输入的是一个序列(句子),最后给出一个评价等
- 多对多:输入是一个序列,输出也是一个序列
- 输出和输入长度相等。比如实体名称标注。
- 输出和输入长度不相等。比如机器翻译,从一个语言翻译到另一个语言,所用的词语长度不一定是一样的。
语言模型和序列生成
- 语言模型:
- 语音识别系统:计算每句话出现的可能性
- 告诉某个特定的句子出现的概率

- 如何构建语言模型?
- 训练集:很大的英文文本语料库(corpus)
- 语料库:自然语言处理的专有名词,指很长的或者说数量众多的英文句子组成的文本
- 句子标记化:根据词字典(比如10000个词),把句子中的每个单词转化成one-hot向量
- 定义句子结尾:增加额外的标记EOS
- 标点符号:自行决定是否看成标记
- 词不在词典中:用UNK进行替换,表示未知词
- 完成:输入的句子都映射到字典中的各个词上了

- 构建RNN模型得到这些序列的概率
- 时间t=0:输入x1和a0计算激活项a1,通常a0取0向量,x1也设为全为0的集合。此时是通过softmax预测第一个词是什么(就是y1),具体就是预测任意词为第一个词的概率,比如a,the,dog等各个词的概率。
- 时间t=1:计算第二个词(y2)是什么。有激活项a1,x1是什么?此时的x1是上一个时刻的输出y1,即x2=y1,那么久可以计算激活项a2,然后计算y2。此时预测y2是各个词的概率,只是此时的概率是个条件概率,就是说前面已经是某个词的情况下,此时预测的词是什么。
- 依次类推,把上一个时刻预测的输出作为下一个时刻的输入,再预测当前时刻的输出。每一步都会考虑前面得到的单词。
- 直到到达序列结尾

- 代价函数:
- softmax损失:预测值和真实值之间的差异
- 总体损失:单个预测的损失函数相加起来
对新序列采样
- 如何知道模型学到了什么?新序列采样的方式进行评估
- 采样:
- 第一个词。模型已经知道了第一位置出现的各个词的概率,那么可以根据这个向量的概率分布进行采样。
- 把采样得到的第一个词作为下一个时间的输入,然后预测得到y2
- 再把y2作为下一个时间的输入,以此类推
- 最后就可以得到一个完整的句子
- 基于词汇的RNN模型(字典中的词是英语单词)

- 基于字符的RNN模型
- 字典:字母、大小写的、数字
- 训练数据:单独的字符而不是词汇
- 优点:不必担心会出现未知的标识
- 缺点:会得到太多太长的序列,计算成本昂贵

- 绝大部分使用的是基于词汇的语言模型
- 基于字符的语言模型
- 左边:新闻文章训练出来的
- 右边:莎士比亚的文章训练出来的

RNN中的梯度消失
- 基本的RNN一个很大的问题:梯度消失
- 训练的时候后面的loss更新对前面的层没有影响
- 如果RNN处理一个1000时间序列长度的数据,那么就相当于是一个1000层的网络,容易出现梯度消失。
- 例子:
- ”The cat, which already ate,…, was full“
- “The cats, which ate, were full”
- 句子前后有长期依赖,就是前面的单词对后面的单词有影响,但是基本的RNN不善于捕捉长期依赖效应

- 标准网络:从输出y得到的梯度很难传播回去,很难影响靠前层的权重,从而影响到前面的层(上图编号4)
- 基本的RNN有很多局部影响
- 比如上图中的输出y3主要受其附近的值的影响
- 不擅长处理长期依赖的问题
- 梯度爆炸:
- 在反向传播中,随着层数的增多,梯度不仅可能指数型下降,也可能指数型上升
- 梯度爆炸:很容易发现,因为参数会大到崩溃,看到很多NaN或者不是数字情况(网络计算出现了数值溢出)
- 解决:梯度修剪。最大值修剪,观察梯度向量,如果大于某个阈值,就缩放梯度向量。是比较鲁棒的方法。
GRU门控循环单元
- GRU:
- gated recurrent unit,门控循环单元
- 改变了RNN的隐藏层
- 更好的捕捉深层连接
- 改善了梯度消失的问题
- RNN单元可视化回顾:
- 根据a(t-1)和x(t)的线性加和,输入到一个激活函数(这里是tanh)计算a(t)
- 把a(t)丢到softmax进行预测
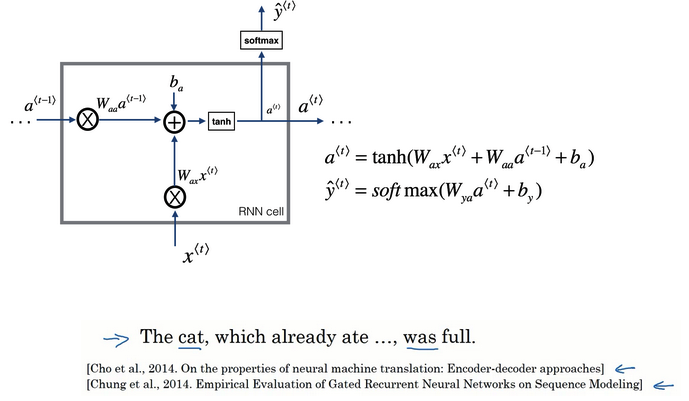
- GRU简化版:
- 新变量c:记忆细胞
- 时间t处的记忆细胞值等于此时的激活值:c(t)=a(t)。在这里是一样的,在后面的LSTM可以看到是不一样的。
- 记忆细胞的候选值:使用激活函数计算,输入是上一时间的记忆细胞c(t-1)和此时的输入x(t)。计算公式类似于计算a(t),但是具体的权重参数不同。
- 门:更新门,关乎着是否要对记忆细胞的值进行更新。其计算的输入是:上一时间的记忆细胞c(t-1)和此时的输入x(t),但是采用的是sigmoid激活函数。因为sigmoid函数值范围在【0,1】之间,这个跟后面的判断更新有关。
- 是否更新?表达式:门 * 记忆细胞候选值 + 门反面 * 记忆细胞旧值

- 【步骤1】根据上一时刻的记忆细胞和输入x计算记忆细胞的候选值
- 【步骤2】根据上一时刻的记忆细胞和输入x计算更新门
- 【步骤3】根据门确定是否更新旧的细胞记忆值,得到激活值或者此时的记忆值
- 如果更新门=0(不更新):激活值=旧值保留
-
如果更新门=1(更新):激活值=候选值,丢掉旧值
- 门用的是sigmoid激活函数,如果其自变量值是很大的负数,那么激活后近似于0.此时,c(t)=c(t-1),非常有利于维持细胞的值,即使经过很多的时间步,能很好的维持。且此时更新门的值很小很小,所以不会有梯度消失的问题。这就是缓解梯度消失的关键!!!
- GRU完整版:
- 更改:在计算记忆细胞的新候选值加上一个新的项
- 相关门r:相关性,告诉候选值和旧值有多大的相关性
- r计算:根据上一时刻的记忆细胞和输入x计算,公式类似于计算更新门,只是具体的权重参数不一样

LSTM长短期记忆
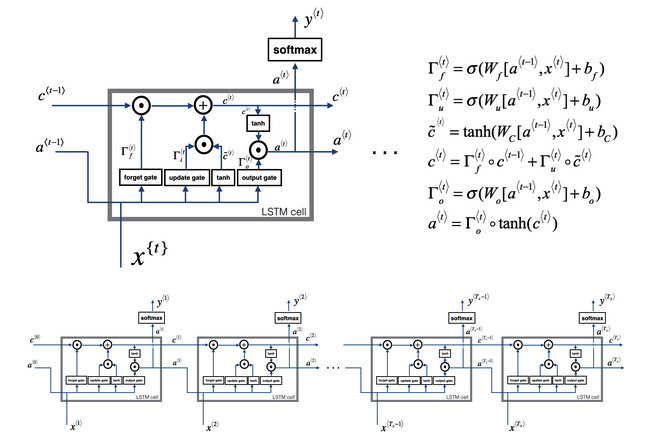
- LSTM:
- long short term memory,长短期记忆
- 比GRU更加高效
- LSTM vs GRU:
- 增加了遗忘门。遗忘门和更新门共同决定记忆细胞值,GRU中只有更新门。
-
增加了输出门:因为此时记忆细胞的值不再直接等于激活值,所以需要有一个输出门

- GRU:更加简单,容易创建更大的网络,计算性能更快,易于扩展到大型网络
- LSTM:更强大灵活,因为具有三个门,使用的更多(虽然出现的更早)
- LSTM计算:
- 【步骤1】根据上一时刻的激活值和输入x计算记忆细胞的候选值
- 【步骤2】根据上一时刻的激活值和输入x计算更新门
- 【步骤3】根据上一时刻的激活值和输入x计算遗忘门
- 【步骤4】根据上一时刻的激活值和输入x计算输出门
- 【步骤5】记忆细胞值 = 更新门 * 候选值 + 遗忘门 * 旧值,计算记忆细胞值
- 【步骤6】激活值 = 输出门 * 记忆细胞值,计算激活值
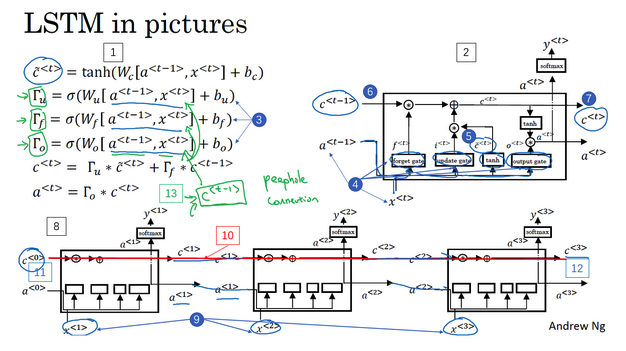
- LSTM前向传播:
- 注意看一下计算的先后顺序和细节
- 前一个激活值是会影响记忆值的计算
- 最后计算的记忆值又会影响输出的激活值
双向神经网络
- 双向RNN:在序列的某点不仅获取之前的信息,也获取未来的信息
- 单向RNN例子:
- 预测只能使用之前的信息
- 但是有时候只有根据后面的信息才能做出准确的判断
- 不管使用基本的RNN单元,还是GRU或者LSTM都是一样的
- 比如下例子中只根据前面的单词是不知道Teddy的名称属性的

- 双向RNN:
- 前向传播:包括两部分的计算,一部分是从左到右的,一部分是从右向左的
- 不仅使用之前的信息,还使用之后的信息。这里的使用就是要传播,比如使用之后的信息,就是后面的输入通过网络要传到前面的结点

- 例子:还是上面的Teddy,网络先从最开始的单词,顺序计算激活值(从左向右),计算完了之后,又从右向左计算,那么后面的值的信息也就传到前面去了。
- 基本单元也可以是GRU或者LSTM
深层RNN
- 通常网络:很多层
- 深层RNN:把多个RNN堆叠起来
- 深层网络比较:
- 左边:标准网络
- 右边:RNN,原来的激活值是a(0),a(1)这种表示的,就直接是第几层的激活值。在RNN里面,稍作修改,因为还有时间的信息,a(0)(1)这种,表示第几层网络的第几个时间点的激活值。

-
例子:a(2)(3)的激活值,两个输入,同一层的上一个时间点,上一层的同一个时间点的激活值
- 每一层网络均有自己的权重值,训练学习得到
- 通常三层就已经很多了
- 可以是GRU或者LSTM单元
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/sequence-models-5-RNN.html
Previous:
SQL速查表
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me