目录
目标定位
- 分类:判断其中的对象是不是某个(比如汽车)
- 定位分类:判断是不是汽车,且标记其位置
- 检测:含有多个对象时,检测确定它们的位置

- 分类网络:
- 图片输入到卷积神经网络
- 输出特征向量
- softmax预测图片类型
- 定位分类网络:
- 图片输入到卷积神经网络
- 输出特征向量
- softmax预测图片类型+输出边界框【让神经网络多输出几个单元即边界框】

- 边界框表示:
- 图片坐上角:(0,0)
- 图片右下角:(1,1)
- 边界框中心坐标:(bx, by)
- 边界框高度:bh
- 边界框宽度:bw
- 训练集:预测对象的分类+表示边界框的四个数字
- 目标标签如何定义(训练集):
- 分类标签:
- Pc:是否含有对象,有=1,无=0
- c1:有行人对象
- c2:有汽车对象
- c3:有摩托车对象
- 边界框:
- 如果对象存在(即Pc=1):此时四个有四个数值bx, by,bh,bw
- 如果对象不存在(即Pc=0):其他参数(c1,c2,c3,bx, by,bh,bw)均为问号”?“,表示毫无意义的参数。
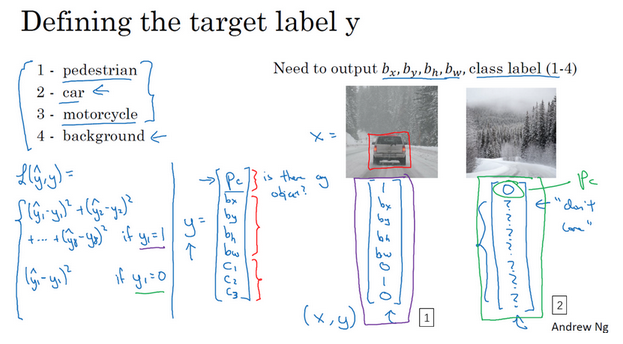
- 分类标签:
- 损失函数:
- 平方差策略:每个元素相应差值的平方和
- 有定位对象:y1=1,Pc=1,损失值是不同元素的平方和
- 无定位对象:y1=0,Pc=0,此时不用考虑其他元素,只关注神经网络输出Pc的准确度。
- 通常:(1)对边界框左边应用平方差或类似方法,(2)对Pc应用逻辑回归函数
特征点检测
- 特征点检测:landmark detection,给出物体的特征点的具体位置,比如人脸识别中眼睛的位置
- 网络:
- 和上面目标定位类似:定位是用四个值框出具体的位置
- 对于我们关注的特征点,可以用一个坐标表示一个特征点
- 比如左眼睛坐标,右眼睛坐标等
- 输出:softmax预测图片类型+输出每个考量的特征点的坐标
- 比如人脸识别:是否有人脸+左眼位置+右眼位置+。。。

- 人体姿态检测:输出关键特征点,比如左肩、腰等,就能知道人物所处的姿态了
- 训练集:
- 标签包含特征点的坐标
- 图片中特征点的坐标是人为辛苦标注的
- 特征点的特性在所有图片中必须保持一致。比如特征点1始终是左眼的坐标值,特征点2始终是右眼的坐标值。
目标检测
- 对象检测:基于滑动窗口的目标检测算法
- 基本步骤:
- 训练集:剪切的含有或者不含有汽车的图片作为正负样本
- 卷积神经网络进行训练
- 在新的图片上进行滑动窗口目标检测
- 图像滑动窗口操作:
- 选定一个大小的窗口,输入上面训练好的卷积神经网络,判断此方框中是否含有汽车。滑动窗口,重复操作,直到滑过所有角落。
- 选定一个更大一点的窗口,重复滑动检测的操作。
- 选定一个再大一些的窗口,重复滑动检测的操作。
- 如果有汽车,总有一个窗口可以检测到它。

- 缺点:
- 计算成本太大
- 剪出很多的小方块,卷积网络一个个的处理
- 如果步幅大:窗口少,但是可能检测性能不好
- 如果步幅小:窗口多,超高的计算成本
- 以前是一些线性分类器,计算成本不是太高;但是对于卷积神经网络这种分类器,成本很高。
滑动窗口的卷积实现
- 滑动窗口检测算法:效率低
- 卷积实现:效率高
- 实现1:将全连接层转换为卷积层
- 一般的CNN分类在卷积层后面是会有全连接层的
- 可以将FC层转换为卷积层
- 这里就会用到1x1的过滤器,来改变通道数量,也就是最后哦输出的大小

- 例子:原来是通过FC,最后得到4个类别的概率值
- 现在通过三个过滤器,最后也得到这4个值,只不过是通过卷积的形式得到的
- 实现2:一次输入图片(滑动窗口的卷积实现)
- 理论上每次一个窗口输入到CNN中进行预测分类。
- 但是把所有的窗口分别输入到CNN中,其实就是一次做一个卷积操作。因为卷积时也是会通过步幅来遍历整个图片的,每次遍历的某一个方块其实也就是某一个窗口。
- 因此可以通过卷积来实现一次对所有的窗口进行预测的目的。
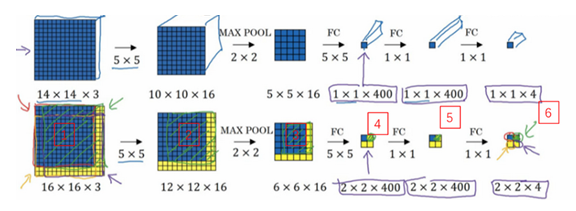
- 上面例子:
- 原来:每次输入一个窗口,最后得到此窗口的输出1x1x4的
- 现在:一次把图片输入,得到2x2x4的输出,因为遍历了4个,相当于上面的4次分别输入。
- 原理:
- 不需要把输入图像分割成四个子集,再分别执行前向传播
- 而是把他们作为一张图片输入给卷积网络计算
- 其中的公共区域可以共享很多计算,也减小了计算量
- 缺点:
- 虽然提高了算法的效率
- 边界框的位置可能不够准确
Bounding Box预测
- 滑动窗口检测:不能输出最精确的边界框
- YOLO算法:
- You Only Look Once
- 更精确的边界框
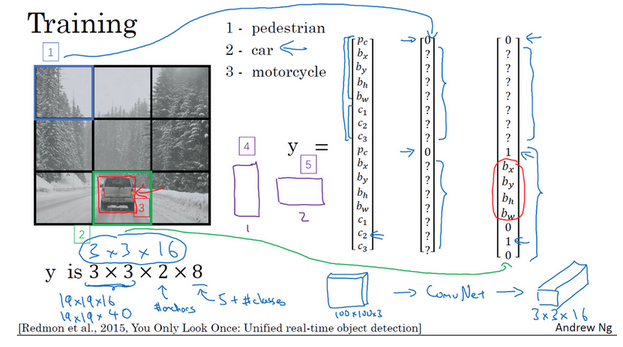
- 思路:使用精细的网格(比如19x19)将图像分隔开,对于每一个小的网格,使用前面的分类和定位算法,那么对于每一个网格,可以得到一个八维的向量(Pc,c1,c2,c3,bx, by,bh,bw)。所以整个图片就得到一个19x19x8的向量。就能够知道在哪个网格中是有汽车的,且是包含了更准确的一个边界框。

- 例子:上面是3x3的网格,最后知道在网格4和6中是有汽车的
- 注意:对象是按照其中点所在网格算的,比如网格5包含有左侧汽车的一部分,但是因为此汽车的中点是在网格4中,所以此汽车分配与网格4,而不是网格5。
- 坐标表示:
- 之前滑动窗口坐标是相对于整个图片的
- YOLO这里是相对于每个网格的
- 网格坐上是(0,0),右下是(1,1),宽度和高度是相对于此网格的比例,是0-1之间的值。
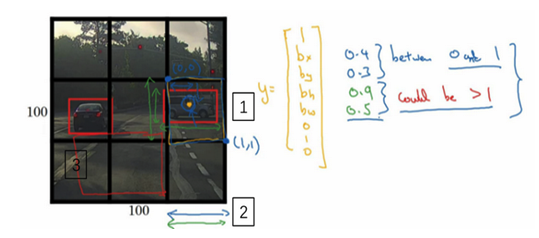
- 优点:
- 网格精细得多,多个对象分配到同一个网格的概率小很多
- 可以具有任意宽高比
- 输出更精确的坐标
- 不会受到滑动窗口分类器的步长大小限制
- 一次卷积运算:效率很高
交并比
- 交并比:
- Intersection Over Union
- 计算两个边界框交集和并集之比
- 评价对象检测算法是否精确

- 一般取:IoU>=0.5,认为检测正确
- 0.5是约定的值,也可以采取其他更严格的值
非极大抑制
- 非极大抑制:non-max suppression
- 算法对同一个对象做出多次检测
- 可以确保对每个对象只检测一次
- 疑问:但是不是中点所在的网格才算吗?检测多次有什么影响呢?中点所在的那个网格并不是概率最大的?
- 理论上是只有一个格子,但是实践中会有多个格子觉得存在检测的对象
- 只输出概率最大的分类结果,但是抑制很接近但不是最大的其他预测结果

- 直观理解:
- 对于某些重叠的box,只取概率最大的
- 其他重叠的则被抑制而不输出
- 比如下面例子中:对于右边的车子,有几个box说检测到了,但是概率是不一样的,只留取最大的(高亮),其他的都被抑制掉(变暗)
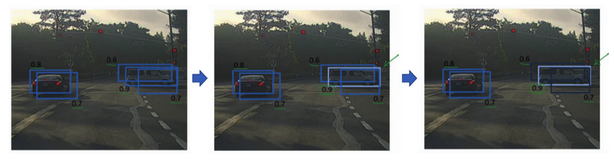
- 具体算法:
- 丢掉预测概率很低的一些边界,比如Pc<=0.6的
- 对剩下的,选取概率最大的边界框(高亮)丢掉与此边界框高度重合的其他边界框(比如IoU>=0.5的)

Anchor boxes
- 目的:处理两个对象出现在同一个格子的情况
- 算法:
- 不使用:根据每个对象所在的中点分配给对应的格子。输出:比如是3x3x8,8个长度的向量表征所在格子
- 使用:根据每个对象所在的中点分配给对应的格子,且分配给与所在格子有最大交并比的anchor box。输出:3x3x16,比如有两个anchor box,前8个表示第一个anchor box的信息,后8个表示第二个anchor box的信息

- 例子:
- 2个anchor box:1个是行人,1个是汽车形状
- 对于箭头所指的网格(编号2),汽车和行人对象的中点都在此网格中。且此对象与两个anchor box均有很高的交并比,所以在这两个都是有信息的。
- 对于右下角的那个格子,只有汽车,没有行人,那么此时y的表示同样包含两个anchor box的部分,但是对于第一个anchor box(行人形状)是没有信息的(问号”?“表示)

- 注意:
- 假如同一个格子有3个对象怎么办?一般处理不好,除非最开始定义多个anchor box
- 两个对象分配到一个格子,且他们anchor box形状一样
- 两个对象中点处在同一个格子中的概率很低,尤其是当格子数目很大的时候
- anchor box形状指定:手工指定,选择5-10个覆盖想要检测的对象的各种形状;更高级的是使用k-均值算法自动选择anchor box
YOLO算法
- 算法输出是包含anchor box信息的,所以在训练集的label中也是要包含这部分信息的
- 训练:
- 构造训练集,人为标注
- 比如对于下面的格子1,什么也没有,其label对应的两个anchor box类别为0,其他边界的信息都以问号表示
- 对于下面的格子2,只有汽车,其label对应的第一个anchor box为0,边界是问号;第二个anchor box是1,且有具体边界
- 预测:
- 构建好了模型,怎么对新图片进行预测?
- 分好格子,每个格子运行神经网络(一次的卷积实现)
- 但是此时对于没有anchor box信息的,输出的边界是一些噪音值,而不是问号

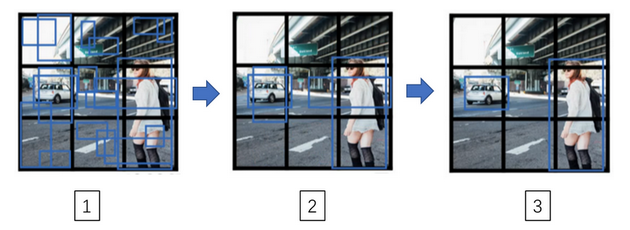
- 预测后的非极大抑制处理:
- 对于获得的结构需要进行非极大抑制处理
- 注意:每个类别分别做非极大抑制

- 例子:从1到2,是丢掉预测概率很低的类别的边界;从2到3,是对于剩下的边界,每个类别单独非极大抑制处理
候选区域
- 候选区域:
- 使用某种算法求出候选区域,对每个候选区域运行一下分类器
- 为什么?图片很多的地方没有任何对象,在这些区域进行检测(滑窗或者卷积)是在浪费时间
- 如何挑选候选区域?
- 图像分割算法:使用图像分割算法,得到一些可能存在对象的区域
- 代表:R-CNN(带区域的卷积网络)
- 对于挑选的区域,使用滑窗

- R-CNN变种:
- R-CNN还是太慢了
- Fast R-CNN:R-CNN的卷积实现,显著提升了速度
- Faster R-CNN:使用碱基神经网络实现图像分割,获取候选区域,而不是使用更传统的分割算法获取候选区域,算法快很多
- 大多数快R-CNN还是比YOLO算法慢很多

- 吴:认为一步做完的类似YOLO算法长远是更有希望的
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/CNN-4-object-detection.html
Previous:
【4-2】深度卷积网络:实例探究
Next:
【4-4】特殊应用:人脸识别和神经风格转换
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me