目录
经典网络
- CNN网络的发展历史:
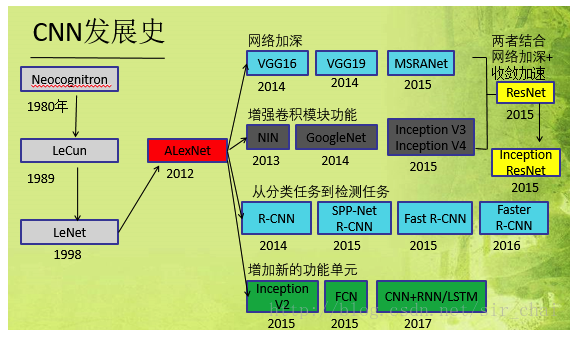
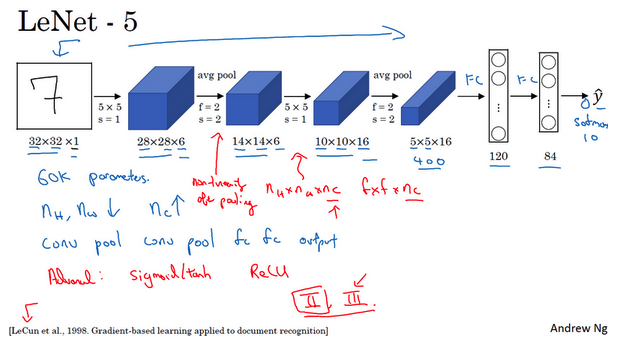
- LeNet-5:
- 识别手写数字
- 针对灰度图像进行训练
- 大约6万个参数
- 模式:一个或多个卷积层后面跟着一个池化层,然后又是若干个卷积层再接一个池化层,然后使全连接层,最后是输出。这种排列方式很常用。
- 非线性处理:使用sigmoid函数和tanh函数,而不是ReLU函数
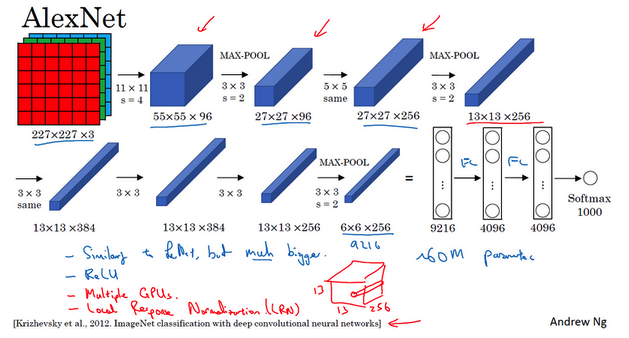
- AlexNet:
- 以第一作者Alex Krizhevsky的名字命名
- 与LeNet-5很多相似处,大得多
- 含有约6000万个参数
- 使用ReLU激活函数,使得其表现更加出色的另一个原因
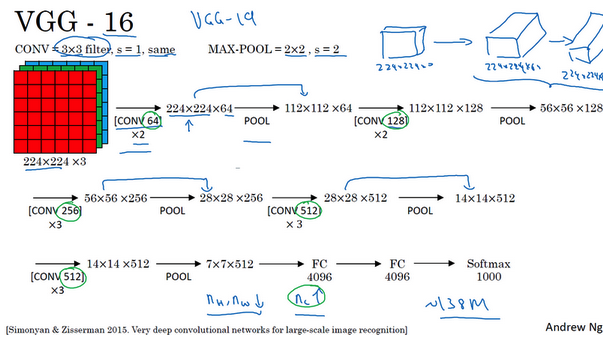
- VGG-16:
- 没有特别多的超参数
- 只需要专注于构建卷积层的简单网络
- 优点是简化了神经网络结构(相对一致的网络结构)
- 缺点是:需要训练的特征数量非常巨大
- 包含16个卷积层和全连接层
- 约1.38亿个参数,但是结构不复杂
- 亮点:随着网络的加深,图像的高度和宽度都在以一定的规律不断缩小,每次池化后刚好缩小一半,而通道数量在不断增加,而且刚好也是在每组卷积操作后增加一倍。
残差网络
- 神经网络训练难:非常深的神经网络训练困难,存在梯度消失和梯度爆炸
- 跳跃连接:从某一层网络层获得激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。比如下面的a(l)跳过一层或者好几层,从而将信息传递到神经网络的更深层。
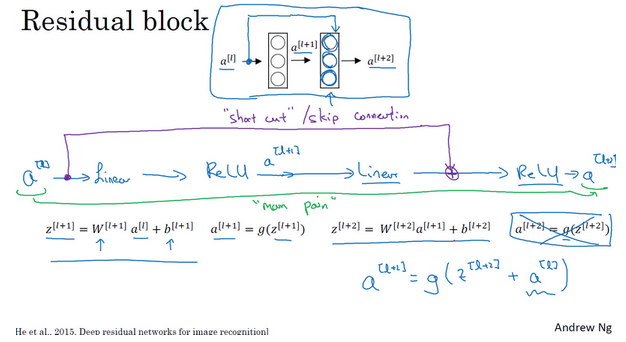
- 残差块:
- 主路径:一层一层向后传播,首先是线性激活,由a(l)得到z(l+1) ,然后是非线性激活,由z(l+1)得到a(l+1) ,依次向后传播。a(l) => z(l+1) => a(l+1) => z(l+1) => a(l+2)。正常的时候信息流从a(l)传到a(l+2)需要经过这些步骤。
- 残差块:将a(l)拷贝到后面的层,在非线性激活前加上这个拷贝的a(l)。对于这里向后拷贝2层,就是\(a^{[l+2]}=g(z^{[l+2]}) => a^{[l+2]}=g(z^{[l+2]}+a^{[l]})\)。也就是这里加上的a(l)产生了一个残差块。
- ResNet:何凯明、张翔宇、任少卿、孙剑
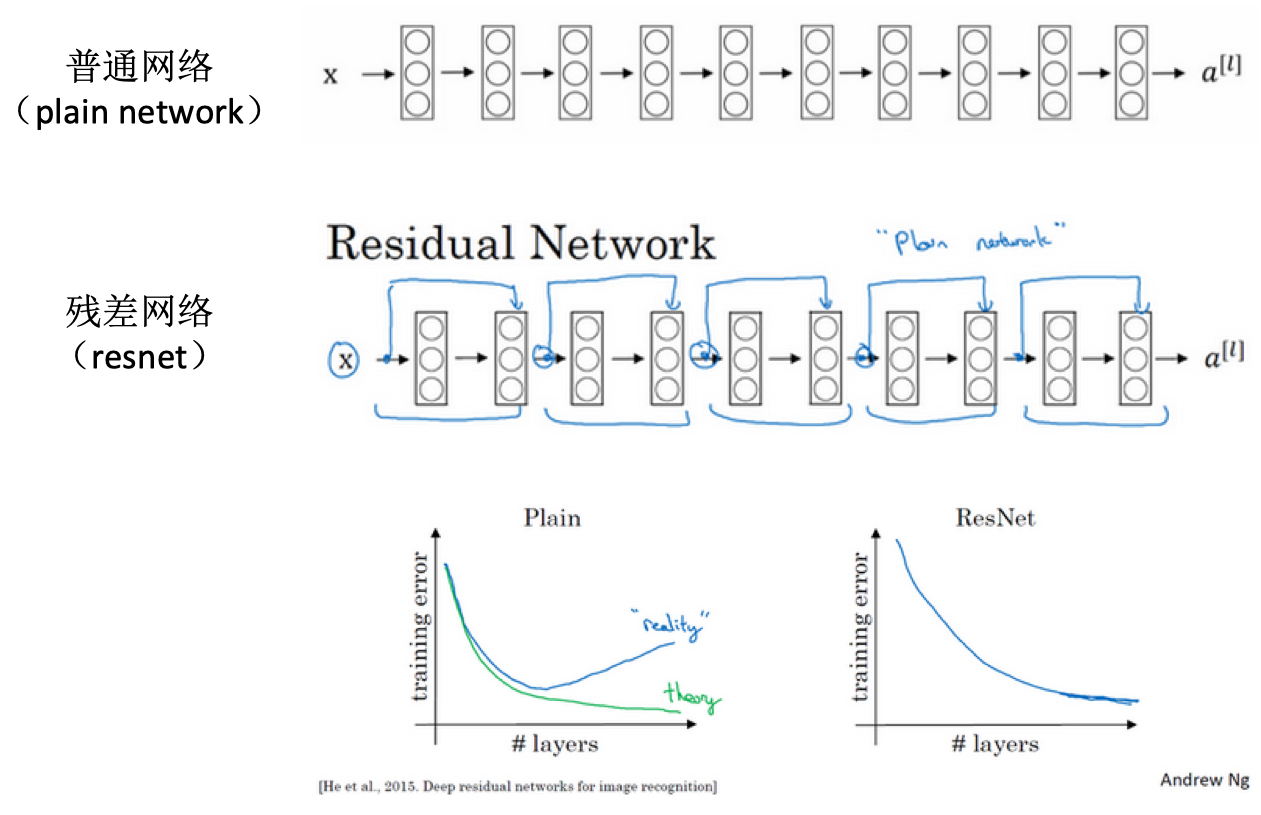
- ResNet vs plain net:
- 普通网络:深度越深则优化算法越难训练,训练错误会越来越多
- 残差网络:训练误差在很深的网络也能很小
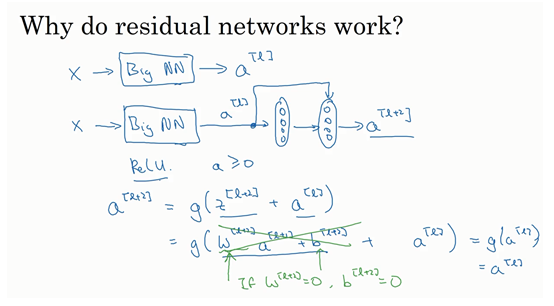
- 为什么残差网络有用?
- 基础:模型在训练集上训练效果好
- 容易学习恒等式:对于加入残差后在进行非线性变换之前的项,如果深度很深,那么此时可能权重(w)和偏差(b)为0。如果用的是ReLU激活函数,a(l)是大于0,激活后\(a^{[l+2]} = g(W^{[l+2]}a^{[l+1]} + b^{[l+2]} + a^{[l]}) = g(a^{[l]}) = a^{[l]}\)
- 此时增加了两层,其效率不逊色于简单的网络
- 很多时候甚至可以提高效率
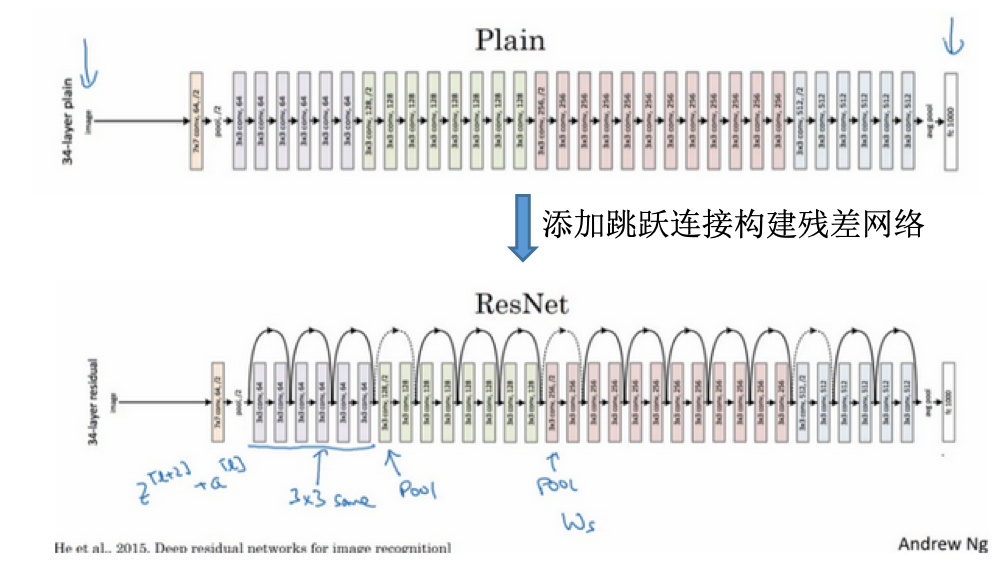
- 假如z(l+2)与a(l)有相同维度,那么a(l)的维度等于这个输出层的维度,使用了许多same卷积。
- 论文中的网络:
- 很多3x3的卷积,且大多是same卷积
- 维度得以保留,所以可以直接相加
网络中的网络及1x1卷积
- 1x1卷积于二维:
- 输入:6x6x1
- 过滤器:1x1x1
- 作用:把图片每个像素乘以一个数字
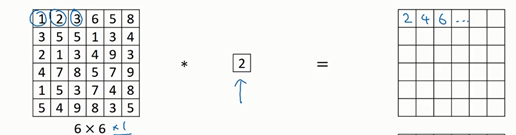
- 1x1卷积于三维:
- 输入:6x6x32
- 过滤器:1x1x32
- 作用:对相同高度和宽度的某一切片上的32个数字,乘以一个权重(即过滤器中的32个数字)
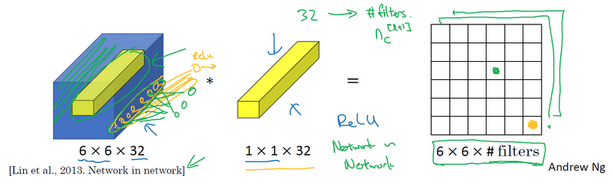
- 作用:对32个不同的位置应用一个全连接层,在输入层上实施一个非平凡的计算
- 压缩作用:
- 池化层:压缩高度和宽度。经过池化之后,图像的大小变成原来的一半,并一直减小
- 1x1卷积:压缩通道数。当每个过滤器的深度和原图像深度一样时,但是使用不同的过滤器数目,可以使得输出的通道数变化(变大变小等)。
谷歌Inception网络
- 为什么出现Inception网络?
- 参考这里的背景介绍
- CNN结构演化图:
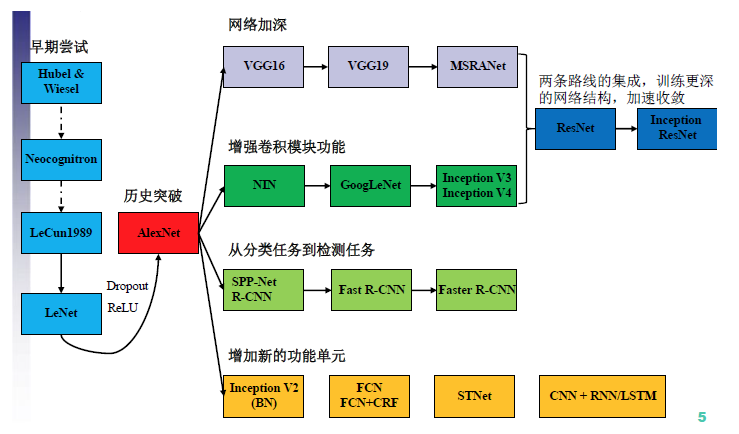
- GoogLeNet出来之前:对于网络的改进是,网络更深(层数),网络更宽(神经元数目)
- 缺点:(1)参数太多,容易过拟合;(2)网络越大计算复杂度越大;(3)网络越深,会出现梯度消失,难以优化
- 解决:增加网络深度和宽度的同时减少参数,于是就有了Inception。
- Inception:
- 盗梦空间的电影名称
- 替你决定过滤器的大小选择多大
- Inception模块:
- 将1x1,3x3,5x5的conv和3x3的max pooling,堆叠在一起
- 增加了网络的宽度
- 增加了网络对尺度的适应性
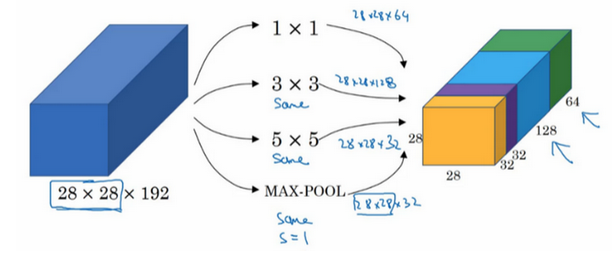
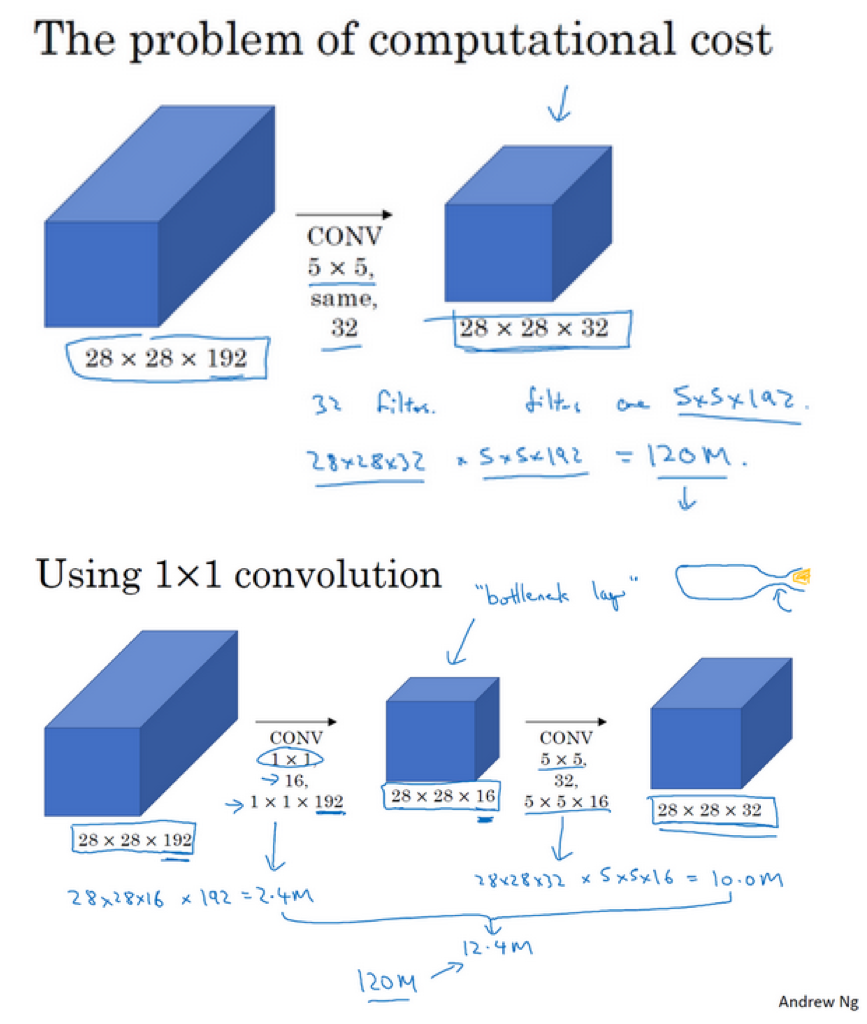
- 计算成本:
- 可以看到,上面的网络中使用不同的过滤器大小进行卷积操作,其计算的成本是很高的
- 比如对于5x5的卷积:过滤器大小(5x5x192)x输出大小(28x28x32)=1.2亿
- 为了降低计算成本,引入1x1卷积操作,因为其是可以用来降低通道数目的
- 此时计算成本:前部分28x28x16x192,后部分28x28x32x5x5x16=1.2亿【计算成本降低为原来的10%】
- 在构建神经网络时,不想决定池化层是使用1x1,3x3还是5x5的过滤器,Inception模块是最好的选择
- Inception网络:
- 将Inception模块组合起来
- 有很多重复的模块在不同的位置组成的网络
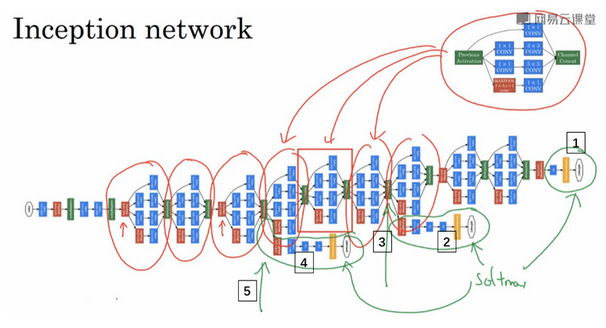
- 其他版本:引入跳跃连接等
迁移学习
- 大型的数据集:
- ImageNet
- MS COCO
- Pascal
- 研究者已经在这些数据上训练过他们的算法,训练花费长时间多GPU
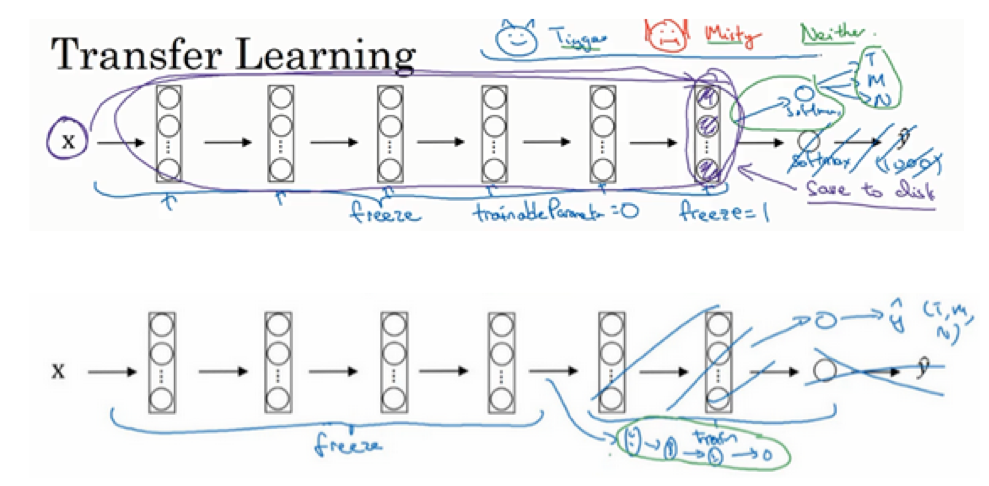
- 迁移学习:
- 下载开源的权重参数,当做一个很好的初始化用在自己的神经网络上
- 用迁移学习把公共的数据集的知识迁移到自己的问题上
- 值得考虑,除非你有一个极其大的数据集和非常大的计算量预算来从头训练你的网络
- 例子:
- 图片猫咪类型识别:只有3种,猫咪1+猫咪2+都不是
- 迁移:基于imagenet数据集学习的分类器,但是其有1000类,即其softmax输出是1000种
- 做法:可以只训练softmax层(3种输出),前面的网络结构和权重完全冻结保持不变,直接进行训练
- 通常:如果你有越来越多的数据,你需要冻结的层数越少,能够训练的层数就越多
数据增强
- 数据扩充:
- 经常使用的一种技巧来提高计算机视觉系统的表现
- 方法:
- 常见的方式有
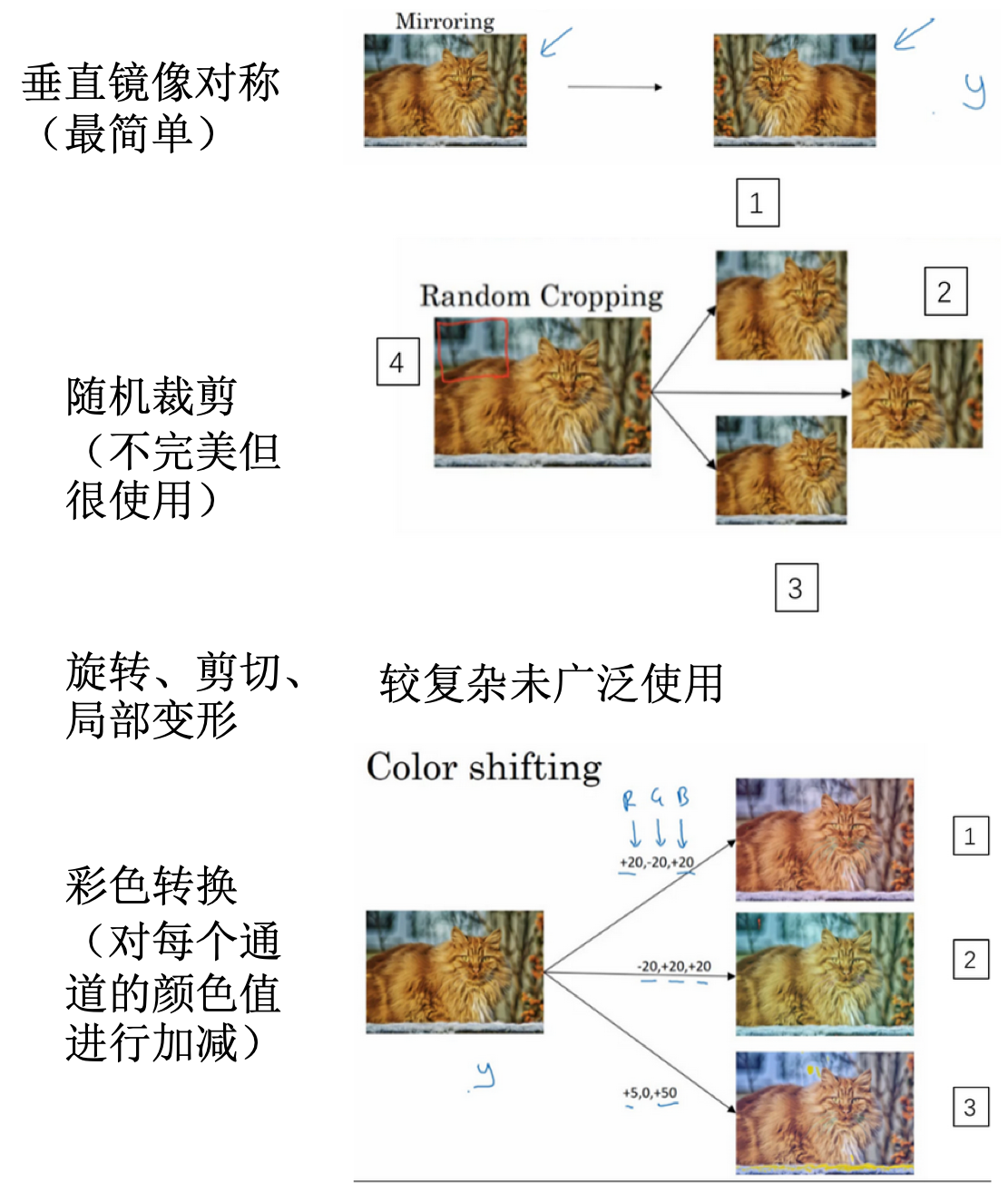
- 常见的方式有
计算机视觉现状
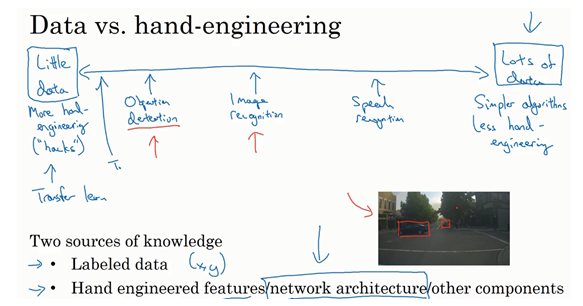
- 机器学习问题:介于少量数据和大量数据范围之间
- 知识或者数据的来源:
- 被标记的
- 手工工程。一般其实是崇尚更少的人工处理
- 基准测试技巧:
- 集成。比如在多个网络中训练,取其平均结果。
- multi-scrop:裁剪选取一个中心区域,取其四个角得到四个样本,其实还是属于样本扩充。对于计算量要求很高。
- 需要耗费大量的计算,不是服务于客户的,只是为了在基准测试中取的好的效果
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/CNN-4-case-study.html
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me