07: Regularization
- 过拟合的问题:
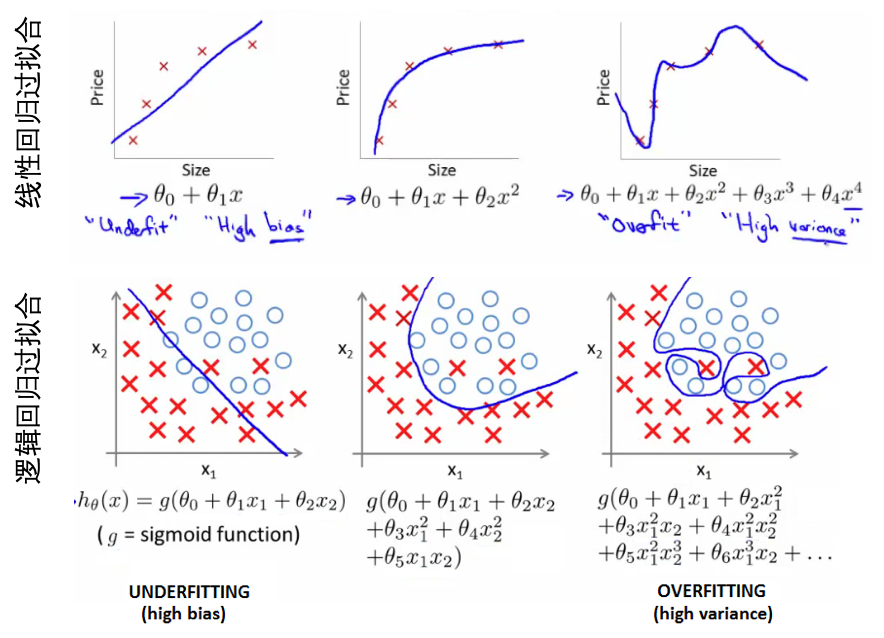
- 线性过拟合:预测房价的问题,从一阶到二阶到四阶的线性拟合【之前的学习也知道,如果模型中的特征数目很多,那么损失函数有可能越接近于0】,损失越来越小大,但是缺乏泛化到新数据的能力。
- 欠拟合(underfitting):高偏差。
- 过拟合(overfitting):高方差,假设空间太大。
- 逻辑回归的过拟合:其函数经过逻辑函数之前可以简单或者复杂,从而欠拟合或者过拟合。
- 如何解决过拟合:
- 如何鉴定是否过拟合?泛化能力很差,对新样本的预测效果很糟糕。
- 低维时可以画出来,看拟合的好坏?高维时不能很好的展示。
- 特征太多,数据太少容易过拟合。
- 方案【1】减少特征数目。1)手动挑选特征;2)算法模型挑选;3)挑选特征会带来信息丢失
- 方案【2】正则化。1)保留所有特征,但是减小权重函数的量级;2)当有很多特征时,每一个特征对于预测都贡献一点点。
- 正则化:
- 参数值较小时模型越简单
- 简单的模型更不容易过拟合
- 加入正则项,减小每个参数的值
- 加入正则项后的损失函数:
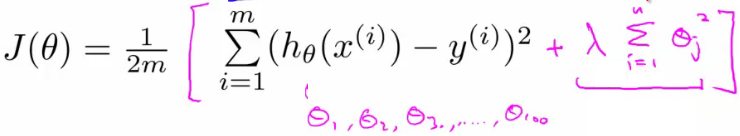
- λ正则化参数:平衡模型对于训练数据的拟合程度,和所有参数趋于小(模型趋向于简单)
- 如果λ很大,所有的参数就都很小,各个特征项没啥用,模型预测效果不好 =》欠拟合。

- 如果λ很大,所有的参数就都很小,各个特征项没啥用,模型预测效果不好 =》欠拟合。
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/CS229-07-regularization.html
Previous:
sklearn: 数据集加载
Next:
Confusion matrix
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me