概述
- 奇异值分解(singular value decomposition,SVD):
- 提取信息的强大工具,将数据映射到低维空间,以小得多的数据表示原始数据(去除噪声和冗余)。
- 属于矩阵分解的一种,将数据矩阵分解成多个独立部分的过程。
- SVD奇异值分解及其意义这篇文章详细解释了SVD的意义及几个应用例子的直观展示,可以参考一下。
- 应用:
- 信息检索:隐性语义索引(latent semantic indexing,LSI)或者隐性语义分析(latent semantic analysis,LSA)。文档矩阵包含文档和词语,应用SVD,可构建多个奇异值,这些奇异值就代表了文档的主题概念,有助于更高效的文档搜索。
- 推荐系统:简单版本是直接计算用户之间的相似性,应用SVD可先构建主题空间,然后计算在该空间下的相似度。
- 电影推荐:协同过滤等
- 矩阵分解:
- 原始矩阵分解成多个矩阵的乘积,新的矩阵是易于处理的形式
- 类似于因子分解,比如12分解成两个数的乘积,有多种可能:(1,12),(2,6),(3,4)
- 多种方式,不同分解技术有不同的性质,适合不同场景
- 常见的是SVD
- SVD:
- 将原始数据矩阵\(Data\)分解成三个矩阵:\(U\),\(\sum\),\(V^T\)
- \(Data\):m x n,\(U\):m x m,\(\sum\):m x n,\(V^T\):n x n
- 分解过程:\(Data_{m \times n} = U_{m \times m}\sum_{m \times n}V_{n \times n}^T\)
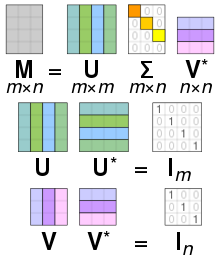
- 矩阵\(\sum\):只有对角元素,其他元素为0,且按照惯例对角元素是从大到小排列的。对角元素称为奇异值(singular value),对应原始数据矩阵\(Data\)的奇异值。
- PCA:矩阵的特征值,表征数据集的重要特征。奇异值和特征值存在关系:奇异值=\(Data * Data^T特征值的平方根\)。
- 矩阵\(\sum\)事实:在某个奇异值的数目(r个)之后,其他的奇异值都很小或者置为0.这表示数据集中仅有r个重要特征,其余特征是噪声或者冗余的特征。
- 如何确定需要保留的奇异值的个数?
- 策略1:保留矩阵中90%的能量信息。能量可以是所有奇异值的平方和,将奇异值的平方和累加到90%即可。
- 策略2:当有上万的奇异值时,保留前2000或3000个。
- 协同过滤:
- Amazon根据顾客的购买历史推荐物品
- Netflix向用户推荐电影
- 新闻网站对用户推荐新闻报道
- 通过将用户和其他用户的数据进行对比来实现推荐
- 相似度计算:
- 比如计算手撕猪肉和烤牛肉之间的相似性,可以根据自身不同的属性。但是不同的人看法不一样。
-
基于用户的意见来计算相似度 =》协同过滤:不关心物品的描述属性,严格按照许多用户的观点计算相似性。
- 欧式距离:距离为0,则相似度为1
- 皮尔逊相关系数(pearson correlation):度量向量之间的相似度,对用户评价的量级不敏感(这是优于欧式距离的一点)
- 余弦相似度(cosine similarity):计算两个向量夹角的余弦值。夹角为9度,则相似度为0;方向相同,则相似度为1.
def ecludSim(inA,inB): return 1.0/(1.0 + la.norm(inA - inB)) def pearsSim(inA,inB): if len(inA) < 3 : return 1.0 return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1] def cosSim(inA,inB): num = float(inA.T*inB) denom = la.norm(inA)*la.norm(inB) return 0.5+0.5*(num/denom) - 基于物品 vs 基于用户相似度?
- 基于用户(user-based):行与行的比较
- 基于物品(item-based):列与列的比较
- 选择哪个取决于用户或物品的数目。计算时间均会随着对应数量的增加而增加。
- 用户数目很多,倾向于使用基于物品相似度的计算。(大部分的产品都是用户数目多于物品数量)
- 推荐引擎的评价:
- 没有预测的目标值,没有用户调查的满意程度
- 方法:交叉测试,将某些已知的评分值去掉,对这些进行预测,计算预测和真实值之间的差异。
- 评价指标:最小均方根误差(root mean square error,RMSE)
- 为什么SVD应用在推荐系统中?
- 真实的数据集很稀疏,很多用户对于很多物品是没有评价的
- 先对数据集进行SVD分解,用一个能保留原来矩阵90%能量值的新矩阵代替
- 在低维空间(提取出来的主题空间)计算相似度
- 推荐引擎的挑战:
- 稀疏表示:实际数据有很多0值
- 相似度计算:可离线计算并保存相似度
- 如何在缺乏数据时给出推荐(冷启动cold-start):看成搜索问题
- 图像压缩:
- 可将图像大小压缩为原来的10%这种
实现
Numpy线性代数工具箱linalg
>>> import numpy as np
>>> U,Sigma,VT = np.linalg.svd([[1,1], [7,7]])
>>> U
array([[-0.14142136, -0.98994949],
[-0.98994949, 0.14142136]])
>>> Sigma # 为了节省空间,以向量形式返回,实际为矩阵,其余元素均为0
array([ 1.00000000e+01, 1.44854506e-16])
# 可以看到第1个数值比第二个数值大很多,所以特征2可以省去
>>> VT
array([[-0.70710678, -0.70710678],
[-0.70710678, 0.70710678]])
通常的推荐策略:
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0: continue
overLap = nonzero(logical_and(dataMat[:,item].A>0, \
dataMat[:,j].A>0))[0]
if len(overLap) == 0: similarity = 0
else: similarity = simMeas(dataMat[overLap,item], \
dataMat[overLap,j])
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
unratedItems = nonzero(dataMat[user,:].A==0)[1]#find unrated items
if len(unratedItems) == 0: return 'you rated everything'
itemScores = []
for item in unratedItems:
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]
基于SVD的评分估计:
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
Sig4 = mat(eye(4)*Sigma[:4]) #arrange Sig4 into a diagonal matrix
xformedItems = dataMat.T * U[:,:4] * Sig4.I #create transformed items
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j==item: continue
similarity = simMeas(xformedItems[item,:].T,\
xformedItems[j,:].T)
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal
基于SVD的图像压缩:
这里原来的图像是32x32的,进行SVD分解,得到U,Sigma,VT,分别是32x2,2,32x2的,所以存储这3个矩阵的大小是:32x2+2+32x2=130,原来是32x32=1024,几乎10倍的压缩。
def printMat(inMat, thresh=0.8):
for i in range(32):
for k in range(32):
if float(inMat[i,k]) > thresh:
print 1,
else: print 0,
print ''
def imgCompress(numSV=3, thresh=0.8):
myl = []
for line in open('0_5.txt').readlines():
newRow = []
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
myMat = mat(myl)
print "****original matrix******"
printMat(myMat, thresh)
U,Sigma,VT = la.svd(myMat)
# 将Sigma向量转换为矩阵,其他元素均为0的
SigRecon = mat(zeros((numSV, numSV)))
for k in range(numSV):#construct diagonal matrix from vector
SigRecon[k,k] = Sigma[k]
# 只保留前numSV个特征,进行数据重构
reconMat = U[:,:numSV]*SigRecon*VT[:numSV,:]
print "****reconstructed matrix using %d singular values******" % numSV
printMat(reconMat, thresh)
参考
- 机器学习实战第14章
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/SVD.html
Previous:
FP-growth算法来高效发现频繁项集
Next:
特征提取
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me