目录
散列函数与散列表
- 场景:在杂货店,如果顾客买东西,如何在O(1)的时间查找到对应商品的价格
-
方法1:数组或者链表,每个元素包含商品名称+价格,使用二分查找,时间代价为O(log n)。还是慢,无法满足需求。
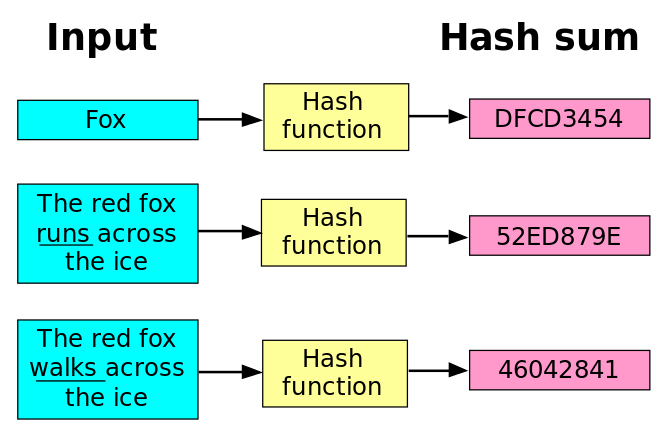
- 散列函数:
- 功能:无论你提供什么数据,都还你一个数字
- 专业描述:将输入映射到数字
- 散列值:通常用一个短的随机字母和数字组成的字符串来代表
- 要求:
- 必须是一致的。什么时候输入一个特定的条目,其输出必须是一样的。
- 将不同的输入映射到不同的数字。如果输出都是一样的,毫无用处。
- 价格存储的例子:
- 输入 =》函数 =》存储的index =》index处的值
- 准确指出价格的存储位置
- 散列表:
- hash table,散列映射、映射、字典、关联数组
- 数组、链表:直接映射到内存
- 散列表:更复杂,使用散列函数来确定元素的存储位置
案例:查找
- 手机电话簿:
- 姓名到电话号码的映射
- 创建映射
- 查找
- 网站:
- 网站名称到IP地址的映射
- 这就是DNS解析(DNS resolution)
案例:防止重复
- 投票:
- 每个人来投票
- 如果未投,则可以投,否则不能再套票。【这其实也是查找的过程】
- 使用散列表来检查是否重复,速度非常快
voted = {}
def check_voter(name):
if voted.get(name):
print("kick them out!")
else:
voted[name] = True
print("let them vote!")
check_voter("tom")
check_voter("mike")
check_voter("mike")
案例:用作缓存
- 访问网页如facebook:
- 1)向facebook服务器发出申请
- 2)服务器做出处理,生成一个网页将其发送给用户
- 3)用户获得一个网页
- 核心:页面的URL映射为页面数据
- 如果某个网页是高度访问的,可以直接存储下来,不用再服务器中间处理的过程,增加访问速度
- 优点:
- 用户更快的看到网页
- facebook需要做的工作更少
冲突
- 理想:将不同的键值映射到不同的地方
- 现实:几乎不可能编写出这样的散列函数
- 冲突:不同的键值被映射到同一个存储位置
- 处理:如果两个键值映射到同一个位置,就在这个位置存储一个链表
- 因此:
- 散列函数很重要
- 如果散列表存储的链表很长,那么查询速度将急剧下降
性能
- 散列表的查找平均是常量时间,简单查找时线性的,二分查找时对数时间的
- 平均情况:
- 查找:与数组一样
- 插入和删除:与链表一样快
- 因此兼具数组和链表的优点
- 最坏情况:
- 查找、插入、删除都是O(n)复杂度
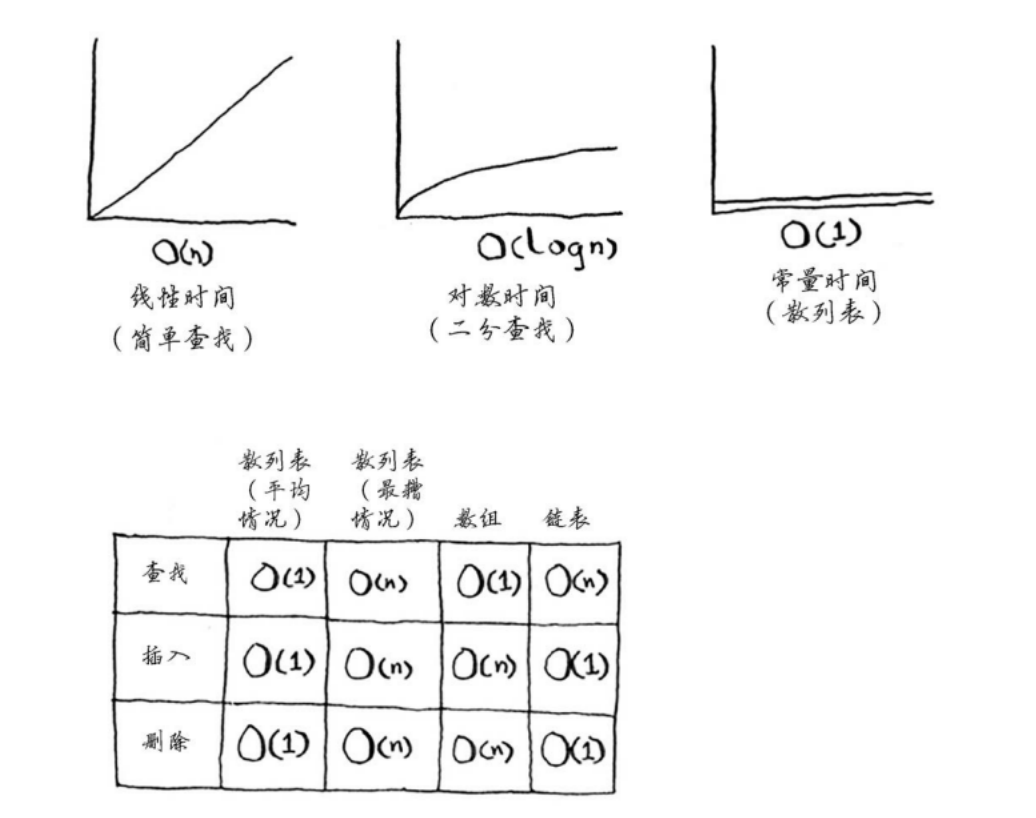
- 查找、插入、删除都是O(n)复杂度
- 如何避免冲突:
- 较低的填装因子
- 良好的散列函数
填装因子
- 填装因子=(散列表包含的元素数目)/(位置总数)
- 散列表是用数组来存储数据,因此需计算数组中被占用的位置数
- 调整长度:当填装因子增大时,需增加散列表的位置
- 经验:一旦填装因子大于0.7,就调整散列表的长度
–
良好的散列函数
- 良好的:散列值呈现均匀分布
- 糟糕的:散列值扎堆,导致大量冲突

参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/algorithm-hash.html
Previous:
Algorithm: 分治法与快速排序
Next:
Algorithm: 图及图搜索
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me