不同的方法
参考:
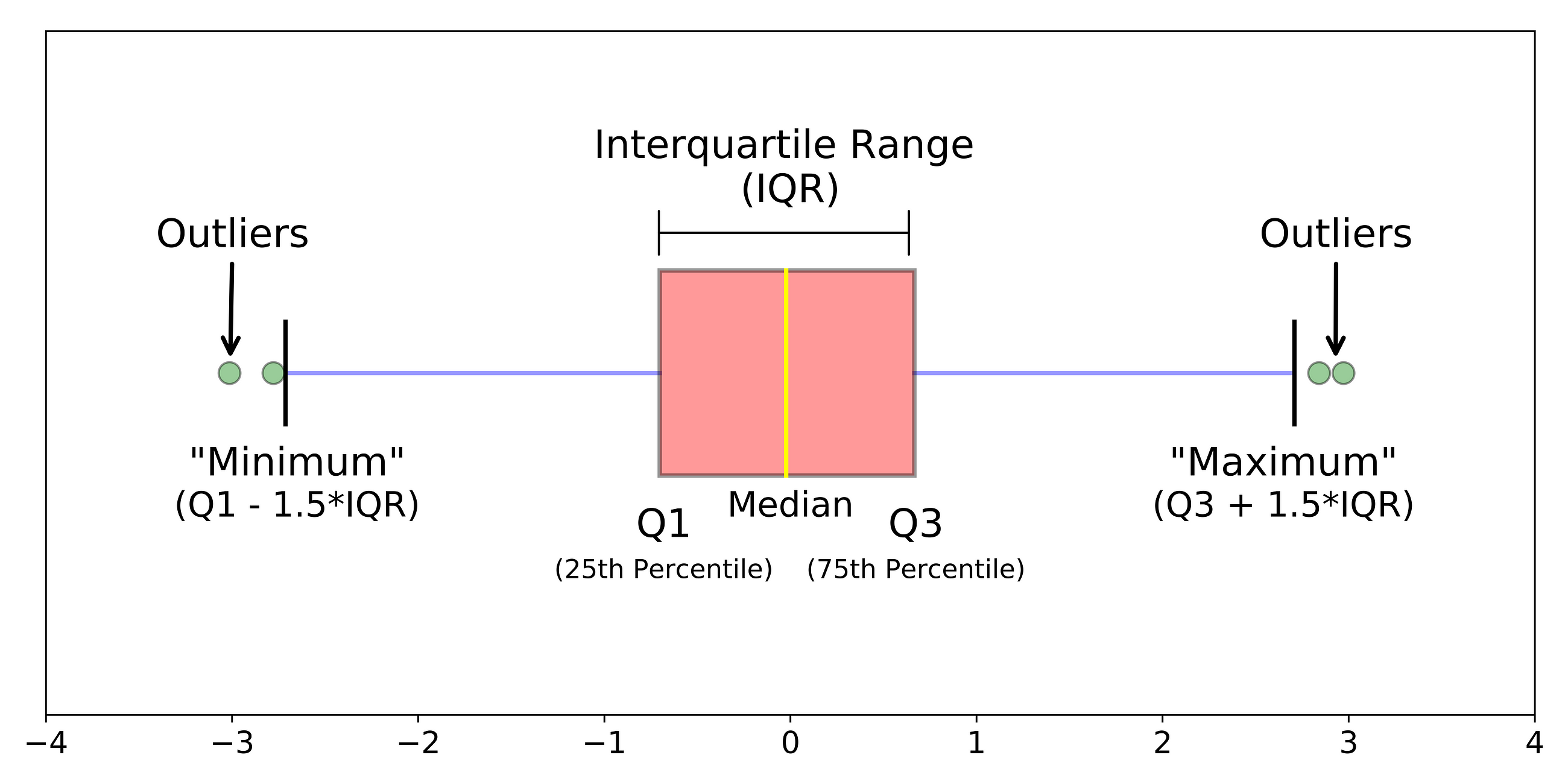
数字异常值(Numeric Outlier)
原理:计算1、3分位值Q1、Q3,位于四分位范围之外的[Q1-k*IQR, Q3+k*IQR]就是异常值,其中IQR=Q3-Q1。
特点:
- 一维特征空间中最简单的非参数异常值检测
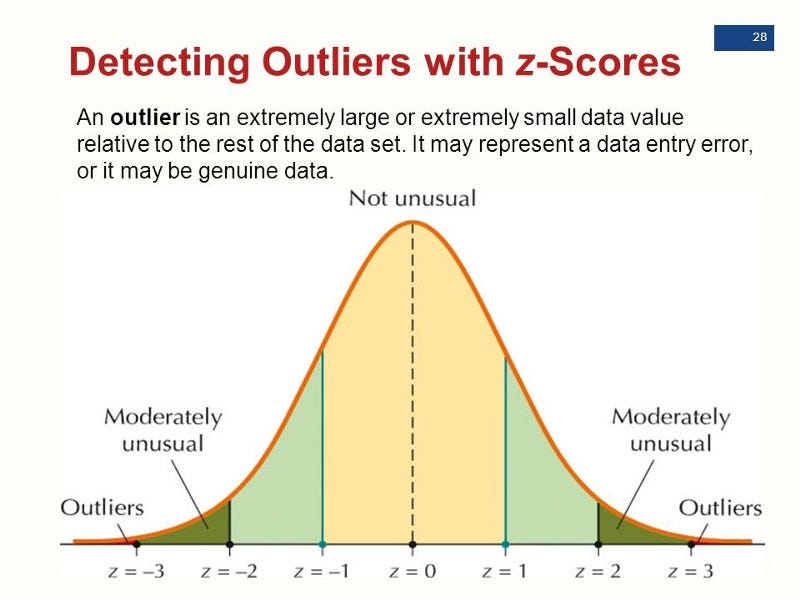
Z-score(统计假设检验)
原理:假定数据是服从高斯分布的,那么在分布尾端的就是异常值。
特点:
- 一维或者低维空间
- 维度灾难:随着维度越来越高,数据点的距离会越来越近。
- 特征服从高斯分布
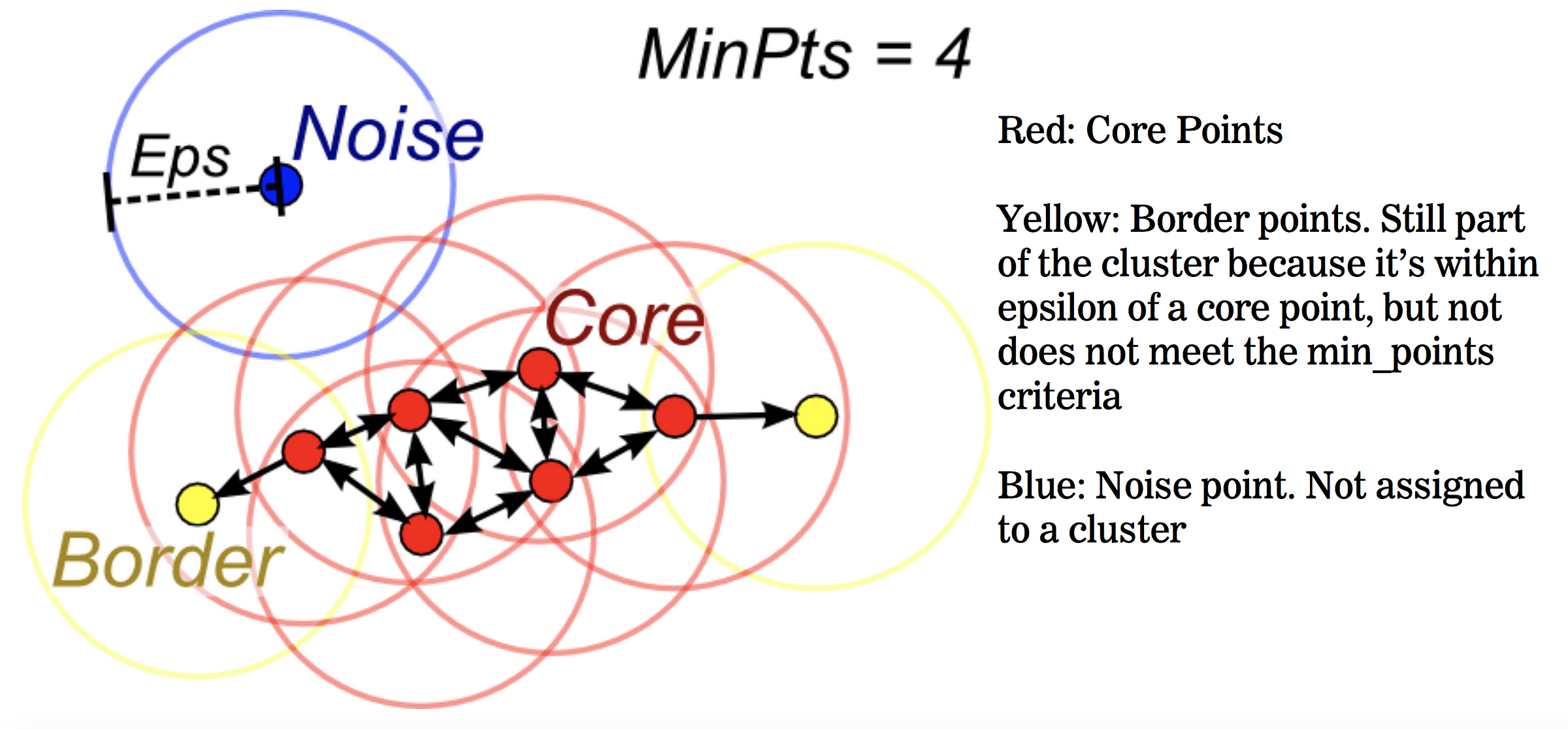
DBSCAN
原理:根据给定的参数(最小包含点数、距离度量),计算不同点之间的距离,将点分为3类:核心点、边界点、噪声点
- 核心点(core points):在距离ℇ内至少具有最小包含点数个其他店的数据点
- 边界点(border points):核心点的距离ℇ内邻近点,但包含的点数小于最小包含点数个
- 噪声点:所有不属于上述的其他数据点,也是异常值
特点:
- 一维或者高维空间
- 基于密度的非参数检测
- 属于一种聚类方法
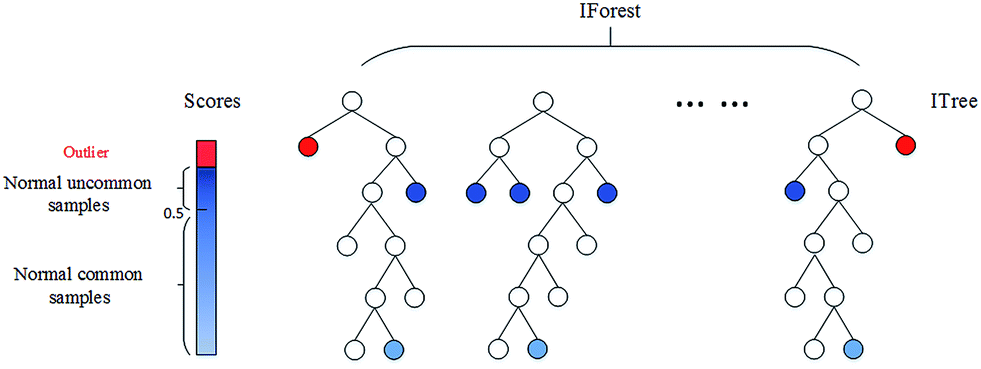
孤立森林(Isolation Forest)
原理: 通过计算每个数据点的孤立数,孤立数低于阈值的点确定异常点。
- 孤立数:孤立数据点所需的拆分数
- 选取一个点A
- 在【最小值,最大值】间选取随机点B
- 如果B值<A值,则B值变为新的下限
- 如果B值>A值,则B值变为新的上限
- 在上下限之间存在除了A之外的其他数据点,就重复该过程,直到A点完全孤立
- 异常值:孤立数更小(更少的次数即可被分隔出来)
- 算法步骤(参考):
- 1、训练:从训练集中采样,构建iTree数。
- 【1】从n个样本中不放回的随机选取m个样本,作为树的训练样本。
- 【2】从此样本中,随机选取一个特征,并随机选取一个值,对样本进行二叉划分。小于该值的在树左边,大于该值的在树右边。树的终止条件:1)数据不可再分;2)树的高度达到log2(m)。
- 2、测试:对于测试样本,用构建的每颗iTree树进行测试,记录path长度,然后基于所有的path长度计算测试样本的异常分数:\(s(x,n) = 2^{(-\frac{E( { h(x) })} { c(n) } )}\), \(c(n) = 2H(n − 1) − (2(n − 1)/n)\) 是二叉搜索树的平均路径长度,\(H(k) = ln(k) + \xi\),\(\xi\)是欧拉常数,其值为0.5772156649。
- 1、训练:从训练集中采样,构建iTree数。
特点:
- 一维或者多维、大数据集、非参数检测
- 基于相似性
- 无需计算基于点的距离
- 基于数据点,构建一堆随机树,通常异常点位于更靠近根节点(具有最短平均路径)的地方
PCA
原理:假设数据在低维空间上有嵌入,那么无法、或者在低维空间投射后表现不好的数据可以认为是离群点。
- 【方法1】:找k个特征向量,计算投射后的重建误差,正常点的重建误差应该小于异常点
- 【方法2】:找k个特征向量,计算每个样本到这k个选特征向量所构成的超空间的加权欧氏距离,正常点的这个距离应该是小于异常点的
- 【方法3】:直接分析协方差矩阵,计算每个样本的马氏距离(样本到分布中心的距离),正常点的距离小于异常点。【soft PCA】
特点:
- 线性模型
MCD(Minimum Covariance Determinant)
原理:用椭圆去包含一半的数据点,使得方差最小。
特点:
- 基于线性

OCSVM(One-Class Support Vector Machines)
原理:训练集中只有一类样本,学习一个边界,包含所有的数据点。
特点:
- 学习的是边界,不同于SVM学习的分隔超平面
- 基于线性

LOF(Local Outlier Factor)
原理:通过局部的密度分布进行检测,异常点的局部密度值低于正常点。
特点:
- 基于相似性
- 局部数据密度(跟其最近邻的点的平均局部数据密度)

kNN(k Nearest Neighbors)
原理:样本与其k近邻的数据点的距离可以作为异常值,异常点的这个距离值更大。
特点:
- 基于相似性

HBOS(Histogram-based Outlier Score)
原理:计算每个数据点,各个特征的值所在的特征所在bin的总和。
特点:
- 基于概率
- 假设特征之间是相互独立的

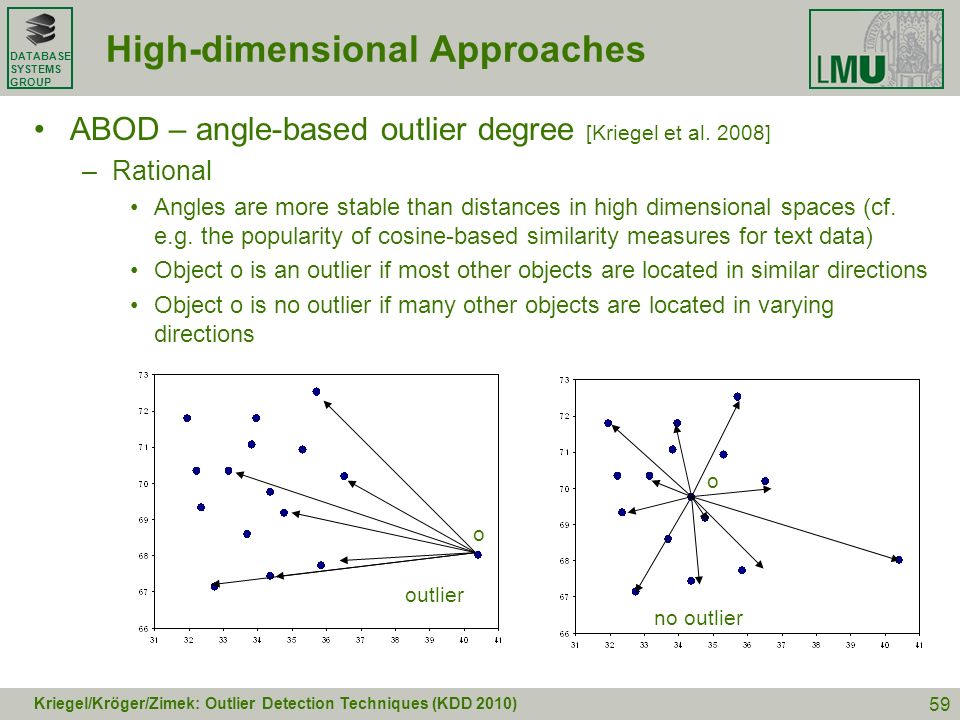
FastABOD(Fast Angle-Based Outlier Detection using approximation)
原理:计算每个样本与其他所有样本所形成夹角的方差,异常点的方差小(因为距离其他点都比较远)
特点:
- 基于相似性
Feature Bagging
原理:随机选择特征子集来构建n个子样本,在数据集的各个子样本上安装多个基本检测器,使用平均或其他组合方法来提高预测精度。
特点:
- 可以使用不同的基本检测模型
- 集成型的算法
- “对feature和data进行bagging之后再利用多种模型输出异常分值,或加权或平均,或者干脆加入到原始特征里,都是比较有效的方法,在实际应用中,模型的精度和召回都提高了五个百分点以上”
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/outliner-detection-summary.html
Previous:
Python module sklearn
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me