df = sns.load_dataset('tips')
print df.head()
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
seaborn的pointplot适合画,单一变量在不同类别中的变化趋势,不适合直接展示两个变量之间的相关性:
sns.pointplot(x='total_bill', y='tip', data=df)
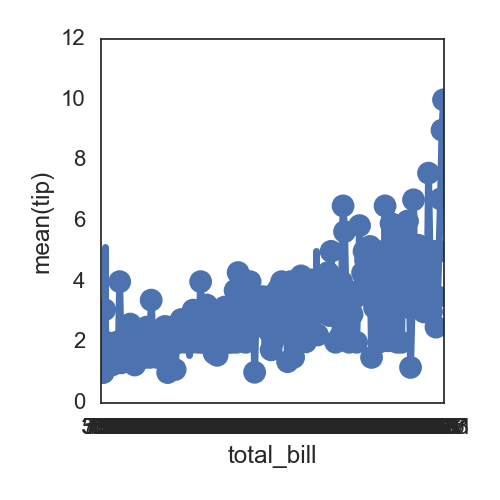
默认的点与点之间是有连线的,可以指定为没有:
sns.pointplot(x="total_bill", y="tip", data=df, linestyles='', )
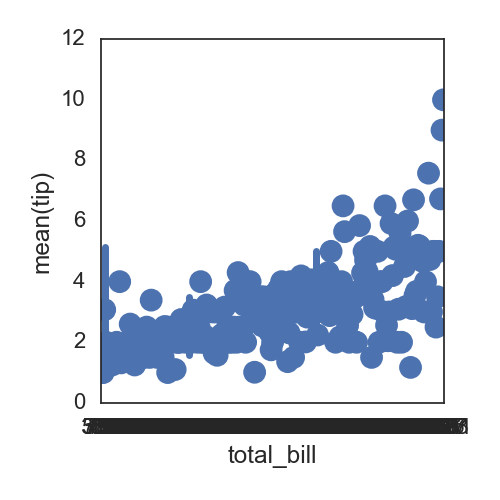
所以直接展示两个变量之间的相关性时,可以直接使用pandas的关于df的函数plot:
df.plot(kind='scatter', x='total_bill', y='tip')
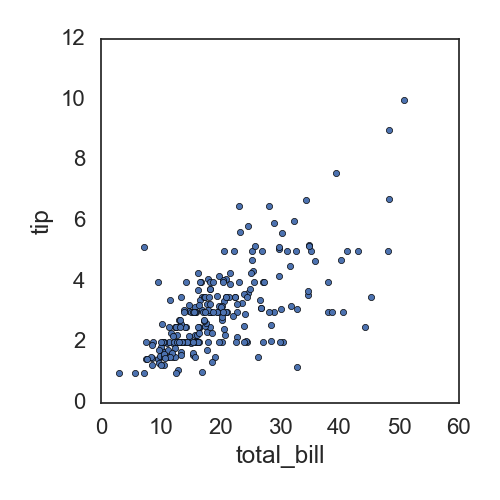
也可用matplot自带的实现,但是默认的效果没有基于df的好:
plt.scatter(x=df['total_bill'], y=df['tip'])
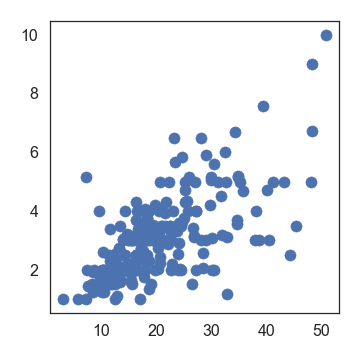
在这里还有很多调试其他的参数的例子,如果需要,可以参考。
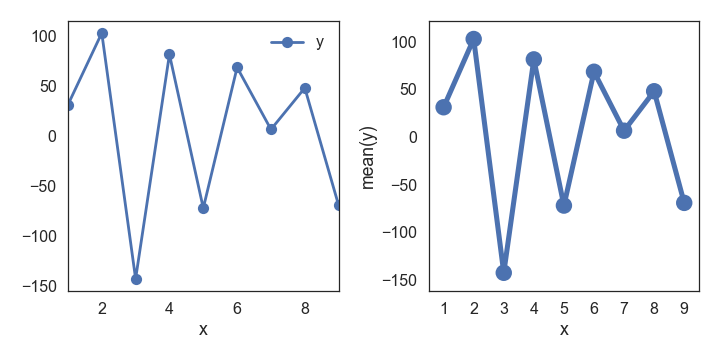
连接型的scatter plot,直接用plot函数即可实现:
df=pd.DataFrame({'x': range(1,10), 'y': np.random.randn(9)*80+range(1,10) })
plt.plot( 'x', 'y', data=df, linestyle='-', marker='o')

也可用df.plot或者seaborn的pointplot直接画,默认的pointplot看起来效果更好:
df2.plot(ax=ax[0], x='x', y='y',linestyle='-', marker='o')
sns.pointplot(x='x', y='y', data=df2, ax=ax[1])
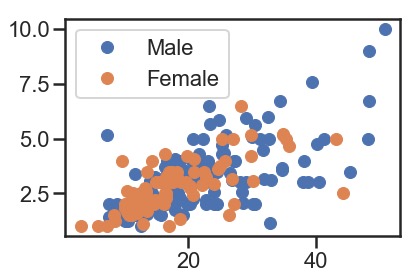
指定点的颜色按照某一列的属性进行上色(参考这里):
# specify the category columns and grouping
groups = df.groupby('sex')
# Plot
fig, ax = plt.subplots()
ax.margins(0.05) # Optional, just adds 5% padding to the autoscaling
for name, group in groups:
ax.plot(group.total_bill, group.tip, marker='o', linestyle='', ms=12, label=name)
ax.legend()
plt.show()
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/scatterplot.html
Previous:
Frequently used genome related data
Next:
Algorithm: 穷举、二分查找
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me