目录
标记样本、未标记样本
- 标记样本:labeled,给出了y值的训练样本,\(D_l=\{(x_1,y_1),...,(x_l,y_l)\}\)
- 未标记样本:unlabeled,类别标记未知的样本,\(D_u=\{(x_{l+1},y_{l+1}),...,(x_{l+u},y_{l+u})\}\)
- 传统监督学习:仅使用\(D_l\)构建模型,\(D_u\)包含信息被浪费
- 若\(D_l\)较小,训练样本不足,模型泛化能力不佳
- 问题:能否在构建模型的过程中将\(D_u\)利用起来?
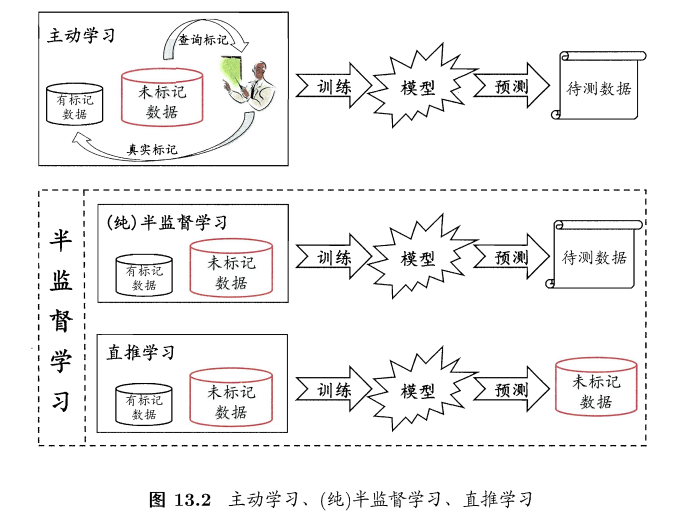
主动学习 vs 半监督
主动学习:active learning
- 引入额外的专家知识,通过与外界的交互来将部分未标记样本转变为有标记样本
- 对于未标记样本,拿来一个,询问专家是好还是坏样本,加入有标记样本数据集进行训练,如果添加的样本能增强模型能力,也可降低标记成本
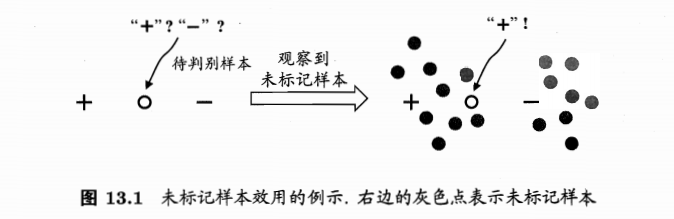
未标记样本的数据分布可提供信息
- 标记和未标记样本均:独立同分布
- 未标记样本数据多,数据分布更接近于真实分布
- 可帮助判断
- 比如可帮助判断分类:
半监督学习:
- 学习器不依赖外界交互、自动的利用未标记样本提升学习性能
- 显示需求强烈,获取标记很费力
- 利用未标记样本需要一些假设:
- 聚类假设:最常见,假设数据存在簇结构,同一个簇的样本属于同一个类别
- 流形假设:常见,假设数据分布在一个流形结构上,邻近的样本拥有相似的输出值。邻近用相似程度刻画,因此可看做聚类的推广。
- 假设本质:相似的样本拥有相似的输出
分类:
- 纯半监督学习:pure,训练数据中的为标记样本不是待预测的数据。更普世、泛化。
- 直推学习:transductive learning,学习过程中所考虑的为标记样本恰是待预测数据
生成式方法
- 基于生成式模型
- 假设所有数据(标记+未标记)由同一潜在模型生成
- 通过潜在模型的参数将未标记数据与学习目标联系起来
- 未标记数据的标记:模型的确实参数
- 可基于EM算法进行极大似然估计
- 不同的潜在模型(人为经验等进行的),对应不同的学习器
为什么未标记样本可以使用上?
- 例子:高斯混合分布的分类
- 预测时的最大化后验概率(对应应该分的类别):

- EM算法求解参数并预测:

- 推广:
- 将这里的混合高斯换为其他的模型,比如混合专家模型、朴素贝叶斯模型,可推导得到其他的生成式半监督学习方法
- 关键:
- 模型假设必须正确,即假设的生成模型必须和真实数据分布吻合,否则使用未标记数据会降低泛化性能
- 现实中难以做出准确假设,借助领域知识
半监督SVM
- 半监督SVM:semi-supervised support vector machine,S3VM
- SVM的推广
- SVM:寻找最大间隔划分超平面
- S3VM:寻找能将两类有标记样本分开,且穿过数据低密度区域的划分超平面
- 基本假设:低密度分隔low-density separation
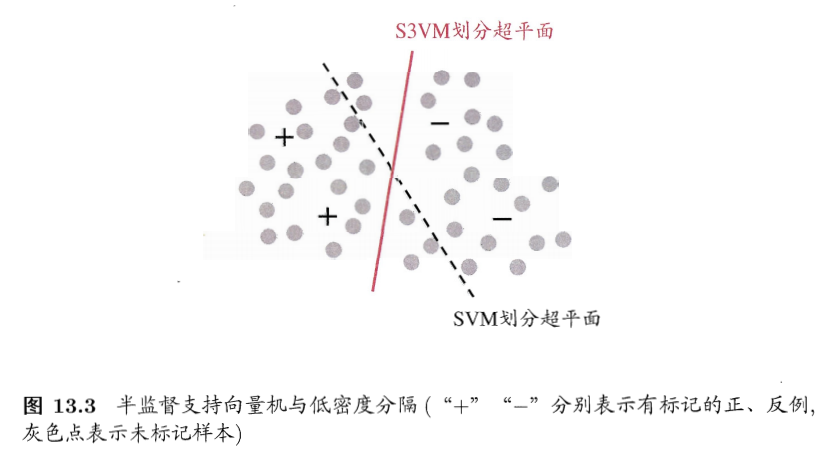
- 基本假设:低密度分隔low-density separation
- TSVM:transductive support vector machine
- 著名的半监督SVM
- 二分类问题
- 对未标记样本进行各种可能的指派(类别1还是类别2),然后在这些所有的可能中,寻求一个在所有样本上间隔最大化的划分超平面。
- 当超平面确定,未标记样本的指派就是其预测结果
- TSVM定义:
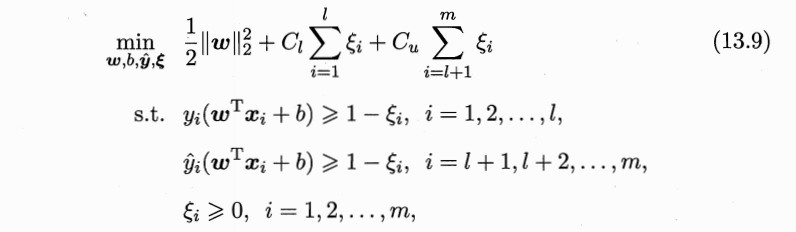
- 划分超平面:\((w,b)\)
- 松弛向量:\(\epsilon\)
- 平衡模型复杂度、有/无标记样本重要性:\(C_l, C_u\)
- 尝试不同的分类情况 =》穷举过程
- TSVM求解:局部搜索迭代
- 使用有标记样本学习一个SVM
- 利用SVM对未标记样本进行分类
- 此时有标记样本+无标记样本都是有标记的,只不过无标记的label是SVM给出的”伪标记“。代入到上面的式子,即可求解划分超平面和松弛向量(此时是个标准SVM问题)。此时”伪标记“不准确,需要提高有标记样本的重要性,所以设置:\(C_u\ltC_l\)
- 找两个label为异类且很可能分错的未标记样本,交换标记,再求解此时的划分超平面和松弛向量。
- 不断迭代,同时提高\(C_u\)的值,增大未标记样本对优化目标的影响
- 直到\(C_u=C_l\)为止

- 如果类别不平衡:将\(C_u\)拆分成\(C_u^+,C_u^-\)
- 缺点:
- 对每一对可能分类错的进行调整
- 计算开销巨大
图半监督学习
- 给定数据集,映射为图
- 结点:数据集的样本
- 边:边的强度对应样本之间的相似性
- 有标记样本:染过色的结点
- 未标记样本:未染色的节点
-
半监督学习:颜色在图上进行扩散或者传播的过程
- 标记传播方法:
- 多分类

- 多分类
基于分歧的方法
- 基于单学习器:生成式、半监督SVM、图半监督式
- 使用多学习器:基于分歧,disagreement-based methods,学习器之间的分歧对于未标记样本的利用至关重要
- 代表:协同训练(co-trainning),也是多视图学习的代表(multi-view learning)
- 多视图数据:
- 一个数据对象往往有多个属性集
- 每个属性集构成一个视图
- 例子:电影
- 图像画面信息属性集
- 声音信息属性集
- 字幕信息属性集
- 网上宣传信息属性集
- 电影样本:\(((x^1, x^2),y)\),\(x^1\)是图像属性向量,\(x^2\)是声音属性向量
- y是标记:影片类型
- 不同视图具有兼容性:即通过不同的属性预测的类别标记是兼容的,不能一个属性预测出的标记是另一个属性预测出来不涵盖的类别。即:\(y=y^1=y^2\)
- 因此不同的属性预测出的是样本不同的类别的信息
- 相容性基础上,不同视图的互补信息会给学习器构建带来便利
- 协同训练:
- 数据具有充分独立视图
- 充分:每个视图足以产生最优学习器
- 独立:视图是独立的
- 训练过程:
- 在每个视图上分别训练出一个学习器
- 每个学习器分别挑出自己最有把握预测对的未标记样本,赋予标记。将这个样本给另一个学习器作为有标记样本进行训练,以更新模型。
- ”相互学习,共同进步“
- 不断迭代,直到学习器不再变化为止

- 数据具有充分独立视图
- 适用:
- 采用合适的基学习器
- 数据不具备多视图时,需要巧妙设计
半监督聚类
- 聚类的监督信息有两种:
- 必连和勿连约束:必连 =》样本必须在同一个类里,勿连=》样本必须不在同一个类里
- 少量的有标记样本
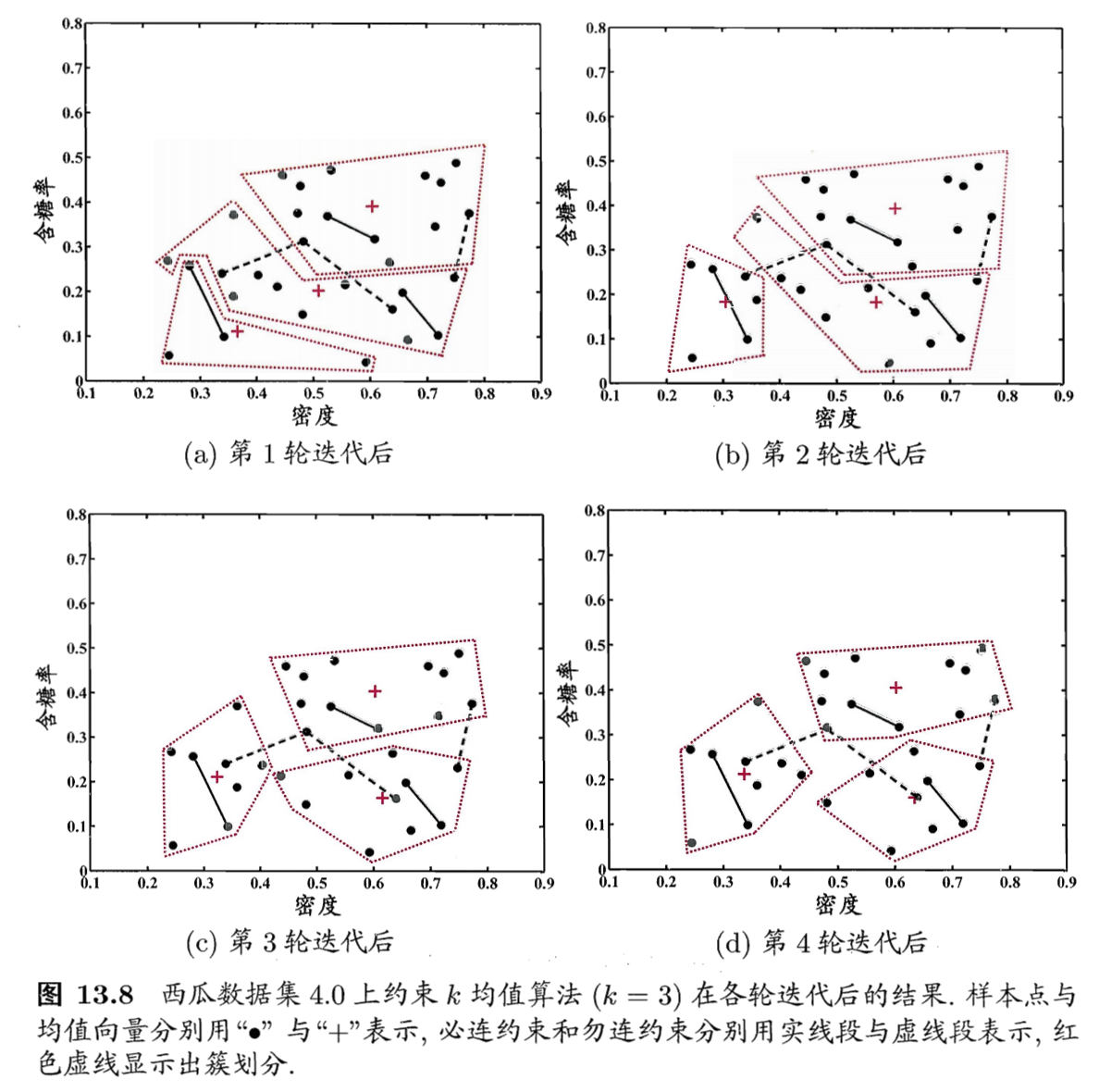
- 约束K均值聚类:
- 利用必连和勿连约束的代表
- 算法过程:

- 西瓜数据集的聚类结果:
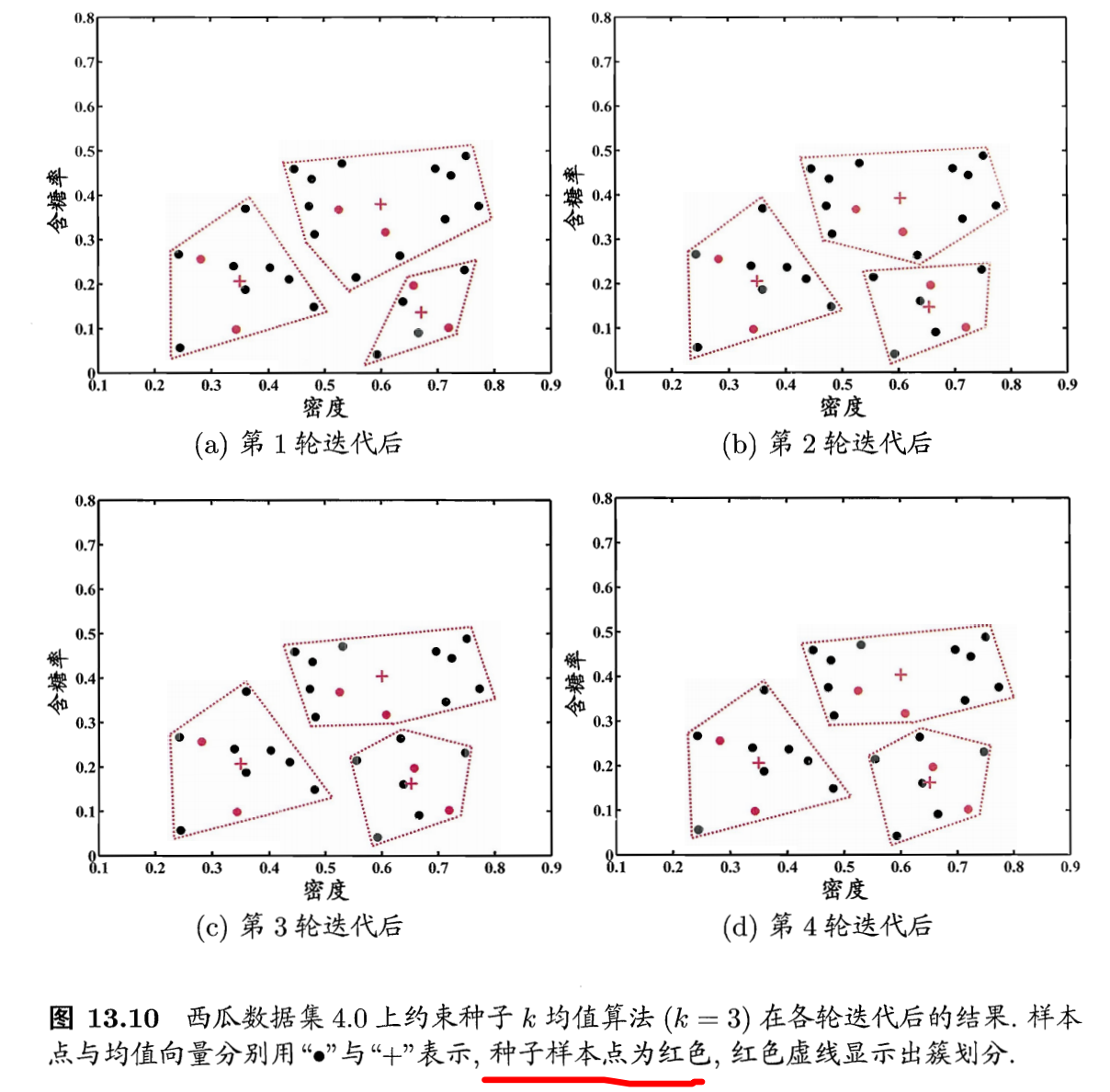
- 约束种子k均值聚类
- 利用少量有标记样本的信息
- 少量的有标记样本,其类别是知道的
- 将有标记样本作为种子,用他们初始化k个聚类中心
- 同时在迭代过程中不改变种子的所属类别关系
- 算法过程:

- 西瓜数据集的聚类结果:
参考
- 机器学习周志华第13章
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/semi-supervised-learning.html
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me