目录
词汇表征?
- 词嵌入:自动理解一些类似的词
- 比如男人对女人
- 国王对王后等
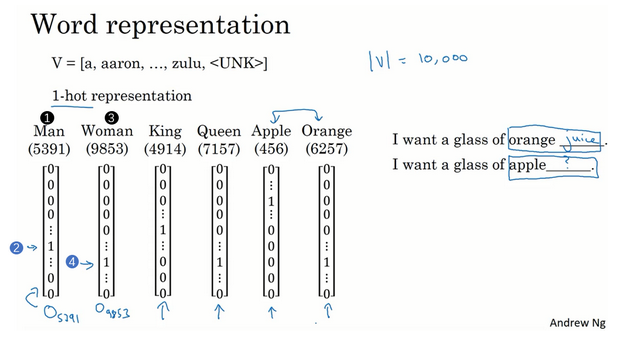
- 词语表示:独热编码
- 最常见的是one-hot方式
- 用词典来表示
- 缺点:把每个词孤立起来,算法对于相关词的泛化能力不强
- 为什么不好?因为这样的表示任意两个词都是相同长度的向量表示,但是只在其对应的位置为1,其他位置均为0.那么任意两个词向量的內积是0,所以相互之间没有任何区分性,比如king和apple相对于orange来说都是一样的。但是我们知道apple应该是更相似的。
- 词语表示:特征化
- 使用不同的特征:比如性别,食物等
- 比如几百个特征,对于每个特征,看每个词在这个特征里面的取值
- 这样每个词都是一个特征向量来表示的
- 此时对于orange和apple可能就很相似了
- 从而对于不同的单词其泛化能力会更好

- 词嵌入可视化:
- 把特征向量(比如300维的)嵌入到一个二维空间中,进行可视化
- 常见算法:t-SNE
- 对于相近的概念,学到的特征也比较类似,在可视化的时候,概念比较相似,最终也会映射为相似的特征向量

使用词嵌入
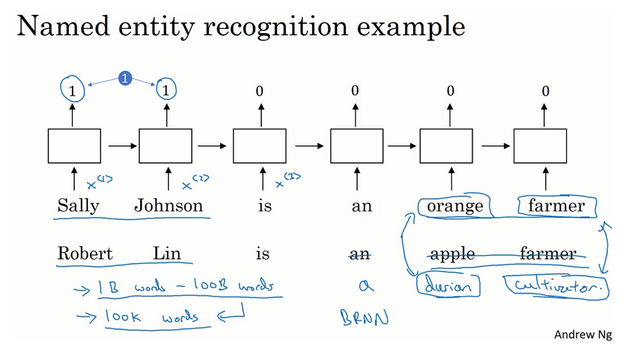
- 例子:命名实体识别
- 找出人名
- 比如下面例子中的两句:一个说是橘子农民,一个是苹果农民,那么如果学到第一个句子中Sally是人名,同样应该可以学到下面的Robert也是农民。
- 为什么有这个效果?
- 学习词嵌入的算法会考察非常大的文本集
- 词嵌入做迁移学习:
- 基于大量的文本集中学习词嵌入。下载文本集或者训练好的模型。
- 把词模型迁移到新的只有少量标注训练集的任务中。比如下载的训练好的模型对每个词是300维向量表示,那么就可以用这个来表示自己的数据集,而摒弃比如说one-hot编码的方式。
- 自行选择是否微调模型。如果上一步中自己有很多的数据,可以微调,如果数据很少,不必微调。
- 应用:命名实体识别、文本摘要、文本解析、指代消解,非常标准的NLP任务中
- 在语言模型、机器翻译用的少,因为这种任务中数据集很大。迁移学习在任务数据量很少的时候比较适用。

- 词嵌入 vs 人脸编码:
- 词嵌入:只有固定的词汇表,一些没出现过的单词记为未知
- 人脸编码:用向量表示人脸,未来涉及到海量的人脸照片
词嵌入的特性
- 实现类比推理
- 问题形式如:如果man对应woman,那么king对应什么?
- 对应问题转换为向量表示
- 每个单词都有词特征向量表示
- man对应woman,可得到这两个特征向量的差值
- king和什么对应?其实是:找一个词的特征向量,使得其和king的差值与man、woman的差值是近似相等的,即: \(e_{man} - e_{woman} = e_{king} - e_{?}\)

- 算法表示:
- 找一个向量,使得两组差异近似
- 转换:找到单词w使得\(e_w\)与\(e_{king} - e_{man} + e_{woman}\)的相似度最大化
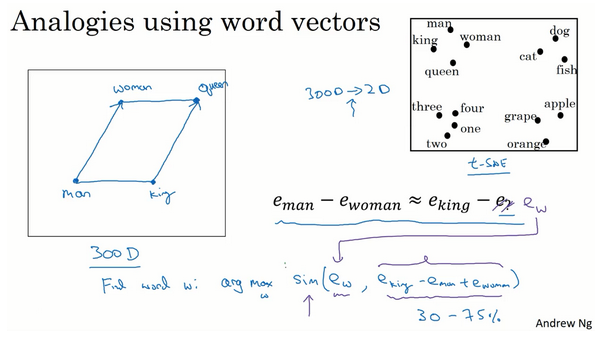
- 类比推理准确率很难到100%,一般是30%-75%
- 相似度:
- 余弦相似度:其实就是两个向量夹角(角度越小,越相似)的余弦值
- 如果夹角=0,两个很相似,相似度=1
- 如果夹角=90,两个很不相似,相似度=0
- 如果夹角=180,两个呈现完全相反的方向,相似度=-1

嵌入矩阵
- 算法:学习词嵌入 =》学习一个嵌入矩阵
- 嵌入矩阵E x 独热编码 = 词向量e
- 词典是:10000
- 词特征是:300
- 嵌入矩阵:300x10000
- 某一个词的独热编码是:10000x1
- 这个词的词特征矩阵:嵌入矩阵(300x10000)与独热编码(10000x1)的內积,最后得到一个300维的向量,正好也是嵌入矩阵E下,这个词对应的300维向量

- 实际中:矩阵相乘效率低下,会有专门的函数查找矩阵E的某列。因为这个时候E是已经求解出来的,不用再通过相乘的方式去获得某个词的特征表示,而是直接索引获取。
学习词嵌入
- 学习词嵌入:有难的算法,也有简单的算法
- 模型流程:
- 输入一个句子,预测接下来的词是什么
- 每个词可以独热编码,求一个矩阵E,使用独热编码和矩阵E表示这个词的特征向量
- 把这些个词的特征向量(这里是300维x6个词=1800)输入到神经网络
- 最后输出到softmax进行预测,预测这个句子接下来是什么词语
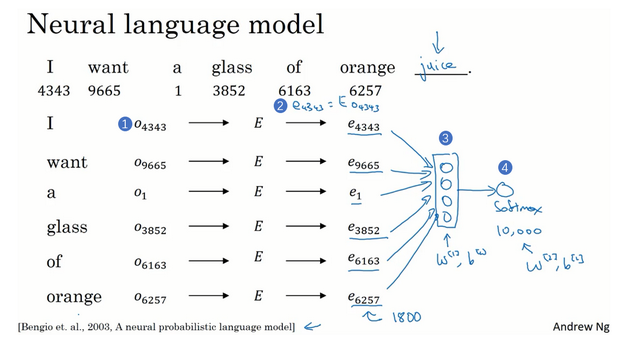
- 当有了训练集之后,就可以训练从而求得模型中的参数了,包括嵌入矩阵E的全部数值
- 问题?输入的句子长度是不一样的怎么办
- 输入不一样长?
- 常见:使用一个固定的历史窗口
- 比如总是输入4个词,预测接下来的一个词
- 那么此时输入到网络的是:300维x4个词=1200
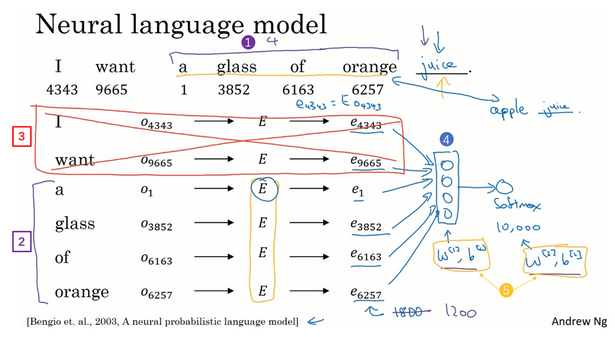
- 其他算法:
- 要预测的词:叫目标词,比如上面输入一句话,预测接下来的一个词,这个词就是目标词
- 问题:左边4个词+右边4个词,预测中间是什么词?
- 问题:一个词,预测接下来是什么词?
- 问题:前两位的一个词,当前词是什么?

Word2Vec
- Skip-Gram:
- 抽取上下文和目标配对,来构造一个监督学习问题
- 随机选取一个词作为上下文词(context)
- 在一定词距内选另一个词,比如前后5或者10个词,在这个范围内随机选取词(目标词,Target)
- 构造监督学习问题:根据上下文词,预测一定词距内随机选择的某个目标词

- 模型:
- 词汇表:10000
- 上下文词:独热向量*嵌入矩阵E得到其嵌入向量
- 嵌入向量输入softmax单元,预测不同目标词的概率:\(p(t\|c)=\frac{e^{ {\theta}_t^T e_c}}{\sum_{j=1}^{10000}e^{ {\theta}_t^T e_c}}\)
- 参数:\({\theta}_t\),与输出t有关的参数,即某个词t与标签相符的概率
- 这里的输入是x(上下文词),预测的是y(目标词):这里y是一个10000的向量,所有可能目标词的概率。
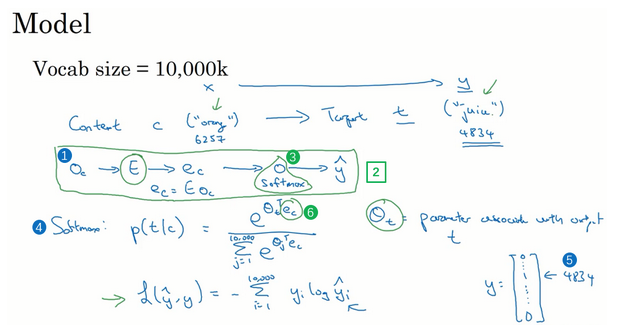
- 理解:输入一个词,预测其前面或者后面是什么词
- 问题:
- 计算速度慢
- 要对比如10000个概率进行计算并求和
- 解决:分级的softmax和负采样
- 分级的softmax:不是一下子就确定词语属于哪一类,而是类似二分,告诉你是属于前5000还是后5000,是前2500还是后2500.形成一个树形结构 =》计算成本与词汇表大小的对数成正比,而不是与词汇表的大小成正比。

- 上下文c进行采样?
- 为什么要采样?构建训练集
- 一旦上下文c确定了,目标词t就是c正负10词距内进行采样了
- 方案1:对语料库均匀且随机采样。有些词比如the、an等会出现得很频繁。
- 方案2:不同的分级来平衡更常见的词和不那么常见的词。
- Skip-Gram vs CBOW:
- skip-gram:输入一个词,预测其前面或者后面是什么词。从目标字词推测出原始语句。【造句】
- CBOW:continuous bag-of-words model,获得中间词两边的上下文,然后预测中间的词。从原始语句推测目标字词。【完形填空】
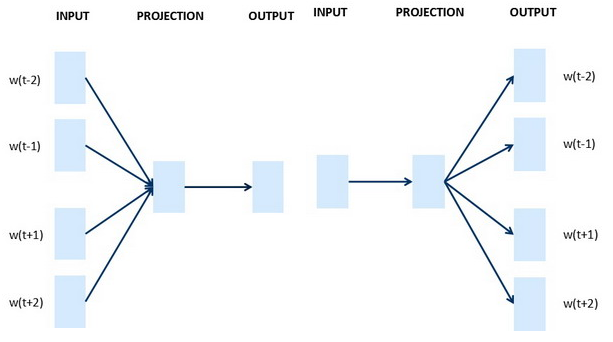
- 参考这里word2vec-pytorch/word2vec.ipynb看两种模型的具体实现
定义的模型:
class CBOW(nn.Module):
def __init__(self, vocab_size, embd_size, context_size, hidden_size):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embd_size)
self.linear1 = nn.Linear(2*context_size*embd_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, vocab_size)
def forward(self, inputs):
embedded = self.embeddings(inputs).view((1, -1))
hid = F.relu(self.linear1(embedded))
out = self.linear2(hid)
log_probs = F.log_softmax(out)
return log_probs
class SkipGram(nn.Module):
def __init__(self, vocab_size, embd_size):
super(SkipGram, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embd_size)
def forward(self, focus, context):
embed_focus = self.embeddings(focus).view((1, -1))
embed_ctx = self.embeddings(context).view((1, -1))
score = torch.mm(embed_focus, torch.t(embed_ctx))
log_probs = F.logsigmoid(score)
return log_probs
负采样
- 新监督学习问题:给定一对单词,预测这是否是一对上下文词-目标词(context-target)
- 样本:
- 正样本:采样得到一个上下文词和一个目标词,此对词标记为1(正样本)
- 负样本:使用上面相同的上下文词,在在字典中随机选取一个词,此对词标记为0(负样本)。随机选取的一个词如果在上下文词的一定词距之内,也没关系。
- 一般负样本给定k次:就是对每个正样本的相同上下文词,重复k次随机选取词,作为负样本。

- 训练:
- 监督学习算法
- 输入:x,一对对的词
- 预测:y,这对词会不会一起出现,还是随机取到的,算法就是要区分这两种采样方式。
- K值大小:小数据集取5-20,大数据集取小一点,更大的数据集取2-5,这里k=4
- 模型:
- softmax模型
- 输入x,输出y(0、1),是否是一对上下文-目标词。在给定的上下文词和目标词情况下,输出y=1的概率:\(P(y=1\|c,t)=\sigma(\theta_t^Te_c)\)
- 1一个正样本+K个负样本训练一个类似逻辑回归的模型
- 基于逻辑回归:将sigmoid函数作用于\(\theta_t^Te_c\)
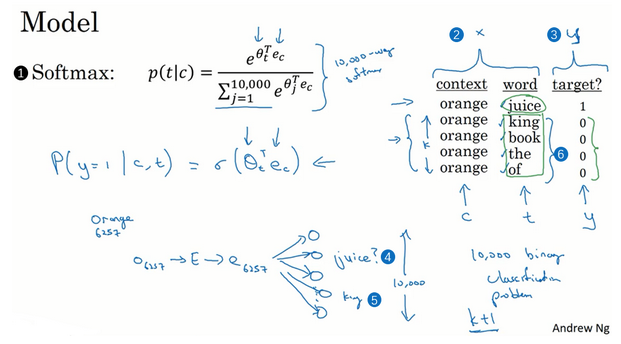
- 每次迭代做k+1个分类问题,所以计算成本比更新10000维的softmax分类器成本低
- 如何选取负样本?
- 上面说了:从字典里面随机选取?
- 方案1:根据词出现的频率进行采样。the、an这类词会很高频。
- 方案2:均匀随机抽样,对于英文单词的分布非常没有代表性。
- 方案3:根据这个频率值来选取,\(P(w_i)=\frac{f(w_i)^{\frac{3}{4}}}{\sum_{j=1}^{100000}f(w_i)^{\frac{3}{4}}}\)。通过词频的3/4次方的计算,使其处于完全独立的分布和训练集的观测分布两个极端之间。
对于skim-gram和CBOW两种模型,根据给定的text数据生成训练数据的方式:
# context window size is two
def create_cbow_dataset(text):
data = []
for i in range(2, len(text) - 2):
context = [text[i - 2], text[i - 1],
text[i + 1], text[i + 2]]
target = text[i]
data.append((context, target))
return data
def create_skipgram_dataset(text):
import random
data = []
for i in range(2, len(text) - 2):
data.append((text[i], text[i-2], 1))
data.append((text[i], text[i-1], 1))
data.append((text[i], text[i+1], 1))
data.append((text[i], text[i+2], 1))
# negative sampling
for _ in range(4):
if random.random() < 0.5 or i >= len(text) - 3:
rand_id = random.randint(0, i-1)
else:
rand_id = random.randint(i+3, len(text)-1)
data.append((text[i], text[rand_id], 0))
return data
cbow_train = create_cbow_dataset(text)
skipgram_train = create_skipgram_dataset(text)
print('cbow sample', cbow_train[0])
print('skipgram sample', skipgram_train[0])
GloVe词向量
- GloVe:
- global vectors for word representation
- 用词表示的全局变量
- 对两个词的关系明确化
- 任意两个位置相近的词,比如上下文词和目标词,他们出现的频率应该是接近的

- 模型:
- 评估同时出现的频率是多少
- 对于任意的一对词,都可以得到这个
- 将差距最小化

- 额外的加权项f(Xij):能使得出现更频繁的词更大但不至于过分的权重
情感分类
- 情感分类任务:
- 看一段文本,分辨这个人是否喜欢他们在讨论的这个东西
- 挑战:标记的训练集没有那么多
- 例子:
- 餐馆评价
- x:评价的一段话,y:给出的几颗星(评价等级)

- 简单模型:
- 某一个评价作为例子
- 对于此评价的每个单词,通过独热编码向量和嵌入矩阵转换为嵌入向量
- 嵌入向量相加取平均。这个能保证最后取得维度是一样的,比如次特征向量是300维的,那么取平均之后还是300维的,且不受输入句子长度的影响。
- 平均后的向量输入softmax分类器
- 输出y:5个可能的结果的概率值
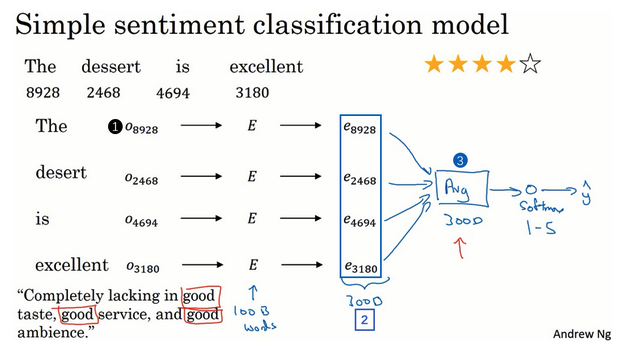
- 此处:【平均值运算单元】,把所有单词的意思给平均起来使用
- 问题:没有考虑词序,也就是一句话如果打乱顺序,最后的词向量平均表示是一样的,但是可能意思是不同的
- RNN版本模型:
- 每个单词通过独热编码向量和嵌入矩阵转换为嵌入向量
- 嵌入向量作为时序序列传到RNN模型中
- 属于多对一的模型,在最后一步才计算一个特征表示,用于预测输出
- 此时就考虑了句子的具体含义,效果更好

词嵌入除偏
- bias:是指学习到的东西存在性别、种族、性取向等方面的偏见。因为现在这些模型越来越多的参与到决策,所以需要排除这些偏见的影响。
- 例子:
- 可能学到man是程序员,但是woman是家庭主妇,这就是带有性别偏见的

- 可能学到man是程序员,但是woman是家庭主妇,这就是带有性别偏见的
- 消除偏见:
- 鉴定bias:比如有一些SUV算法,对一些词语进行聚类,不同的维度(偏见、不偏见)。如果在偏见轴大的,就是属于有偏见的。
- 中和:对于不确切的词可以处理一下,避免偏见。
- 均衡:有一些词保证它们只在一个维度是有差异的,比如grandmothers和grandfathers只在性别有差异,其他特征保证相等(在坐标抽上的距离是相当的)。

参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/sequence-models-5-NLP-word-embediings.html
Previous:
爬虫抓取微博内容
Next:
【5-3】序列模型和注意力机制
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me