目录
基础模型
- seq2seq模型:
- sequence to sequence
- 机器翻译
- 语音识别
- 例子:机器翻译【seq2seq】
- 输入:法语句子
- 输出:英语句子
- 模型:
- 编码网络:RNN结构,可向其中输入法语句子,接收完法语之后,会输出一个向量表示这个输入的法语句子
- 解码网络:编码的输出作为输入,训练输出一个个的词,每个预测的词作为下一个的输入进行预测

- 例子:图片描述【image to sequence】
- 输入:一张图片
- 输出:图像描述
- 模型:
- 编码网络;预训练的图像表示网络,用于提取图片的特征
- 预测网络:基于图片特征向量,生成描述,可用RNN模型,最后会输出一个序列

选择最可能的句子
- 语言模型:
- 估计句子的可能性
- 比如给定中间的词,预测上下文的词
- 比如给定上下文的词,预测中间的词
- 机器翻译:
- 条件语言模型
- 输入法语句子
- 输出英语句子,估计一个英文翻译的概率。这个英语句子是相对于输入的法语句子的可能性,所以是一个条件语言模型。

- 翻译概率最大化:
- 输入:一个法语句子
- 输出:一个翻译的英文句子
- 目的:不是想随机的输出,想输出一个很好的翻译。你会有很多的翻译可能性,那么就是要找到最合适的翻译y,使得这个条件概率(在给定法语句子时英语翻译的概率)最大化。
- 做法:集束搜索(beam search)

- 为什么不用贪心算法?
- 如果这里用贪心算法,做法就是这样的:生成第一个词的分布,选择最可能的一个;挑选了第一个后,继续挑选第2个最有可能的,如此继续。每一步都是挑选最优的一个。
- 翻译本质:挑选一个整体最优的,而这个最优的可能不是第一步最最优的,或者不是第二步是最优的。
- 例子:看下面的两个翻译
- 贪心:选择了”Jane is“之后,贪心会选择”going“,因为这个词是更常见的,概率是更大的。
- 但是显然第1个翻译比第2个是更好的,所以根据贪心的算法,最后可能选择了一个欠佳的翻译。

- 另外,每一步词的可选数量就是整个词典的大小,那么所有的都要进行计算的话,是不现实的。
- 近似搜索算法:尽力挑选出句子y使得条件概率最大,但不能保证找到的y值一定可以使得概率最大化。
集束搜索
- 核心:每一步都是选出B个最可能的单词,而不是一个
- 参数B:集束宽,beam width,考虑多少个选择
- 例子:
- 【挑选第1个单词】
- 在给定输入的情况下,获得了输入的表示向量。词向量输入到解码网络中,预测第1个词是什么。解码网络有一个softmax层,会得到10000个单词的概率值,那么取前B个(比如这里是3个)单词存下来便于后面使用。

- 【挑选第2个单词】
- 比如第1步选出来最有可能的3个词:in、jane、september
- 接下来选择第2个词,怎么选?对于第一步选的3个词,分别作为y2的输入,预测此时对应的y2,选取其对应的概率值最大的3个。这样就得到了,输入法语句子+输出一个词特定的条件下,第二个词应该选择什么。

- 【挑选第3个单词】
- 类似的,对于上面的情况,分别进行讨论,看在对应的第1、第2个词的情况下,保留第3个最大的情况
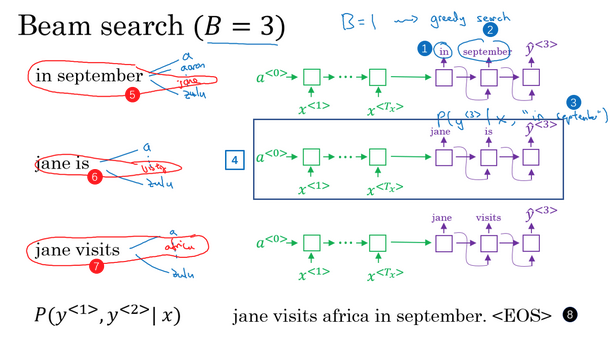
- 不断进行搜索,一次增加一个单词,直到句尾终止。
- 集束搜索 vs 贪心算法:
- 束宽的值可以选取不同的
- 当束宽=1时,每次就只考虑一个可能结果 =》贪婪搜索算法
改进集束搜索
- 乘积概率 =》对数概率和:
- 最大化的概率:乘积概率
- 概率值小于1,且通常远小于1。很多数相乘,会造成数值下溢(数值太小,电脑的浮点表示不能准确存储)。
- 乘积概率转为对数概率和:便于存储和计算
- 长度归一化:
- 原来:长句子 =》概率值低,短句子 =》概率值高。
- 缺点:可能不自然的倾向于简短的翻译结果,更偏向于短的输出,因为短句子的概率是由更少数目的小于1的数字乘积得到,所以不会那么小。
- 归一化:除以翻译结果的单词数量,就是取每个单词的概率对数值的平均,可明显的减少对输出长的结果的惩罚。

- 归一化的对数似然目标函数
- 探索性:在长度Ty上加一个指数a,a可以取0.7,1.0之类的。如果a=1.0,就是完全长度归一化,如果a=0,那么就是没有归一化。设置适当的值,可以获得不同的效果。
- 如何选取束宽值B?
- B越大,考虑的选择越多,找到的句子可能越好,但是计算代价越大
- B越小,考虑的选择越少,找到的句子可能不好,但是计算代价越小
- 例子中使用的是3,实践中是偏小的
- 在产品中可设置到10,100可能是偏大的
- 束宽1变为3,模型的效果可能有所提升;束宽1000变为3000,模型的效果可能没有太多提升。
集束搜索的误差分析
- 误差分析:通过分析错误样本,定位模型的性能瓶颈,指导下一步应该从哪里进行改进
- 翻译模型:
- 组成:seq2seq模型(RNN的编码和解码器) + 集束搜索模型(寻找可能最优的翻译)
-
要么是RNN出错,要么是集束搜索出错,如何定位?
- 输入:法语句子
- 真实翻译:人的翻译\(y^*\)
-
算法翻译:算法的输出\(\overline{y}\)
- 做法:使用RNN模型计算两个概率,一个是在给定x下,人的翻译的条件概率:\(P(y^*\|x)\);一个是在给定x下,算法的翻译的条件概率:\(P(\overline{y}\|x)\)
- 判断:如果\(P(y^*\|x)\)大于\(P(\overline{y}\|x)\),真实的人的翻译比算法选择的更好,但是最后搜索算法选择了现在的\(\overline{y}\),说明是集束搜索算法出现了问题。
- 判断:如果\(P(y^*\|x)\)小于\(P(\overline{y}\|x)\),真实的情况是真实的人的翻译比算法选择的更好,但是算法却计算出前者概率更小,算法也确实是输出了基于RNN的更好的\(P(\overline{y}\|x)\),所以算法没有问题,是RNN模型本身不够好。

- 误差分析:
- 遍历数据集或者挑选一些例子
- 对于每个例子,用RNN模型计算上面提到的概率值
- 根据上面的判断原则,确定每个样本中是哪一个部分出现了问题:RNN还是beam搜索?
- 最后统计一下两者的比例,就知道接下来应该优化哪一部分了

Bleu得分
- 问题:当有同样好的多个答案时,怎样评估一个机器翻译系统?
- BLEU得分:
- 给定一个机器生成的翻译,自动计算一个分数来衡量机器翻译的好坏
- bilingual evaluation understudy:双语评估替补
- 相当于一个候选者,代替人类来评估机器翻译的每一个输出结果
- 评估:
- 机器翻译的精确度:输出的结果中的每一个词是否出现在参考中
- 下面例子:MT(机器翻译)输出,输出长度为7,每个词the都出现在参考中,所以精确度=7/7。
- 显然不是一个好的翻译
- 引入计分上限:这个词在参考句子中出现的最多次数,比如这里the在参考中出现最多的是2次,所以其上限是2.
- 改良后的精确度评估:2/7。分母:单词总的出现次数,分子:单词出现的计数,考虑上限。

- 二元词组的BLEU得分:
- 上面的其实是考虑的单个单词
- 其实句子还可考虑二元或者三元的词组得分
- 列出机器翻译中所有的二元词组
- 统计每个二元词组在机器翻译中出现的次数(count)
- 统计每个二元词组在参考中出现的考虑上限的计数(the clipped count)。比如这里的the cat在参考中最多出现1次,所以其截取计数是1而不是2.
- 改良后的精度:截取计数和/计数和

- 任意元词组的BLEU得分公式化:
- 一元、二元、三元词组等
- 每一个,就可以计算其改良后的精度:n元词组的countclip之和除以n元词组的出现次数之和

- 最终BLEU得分:
- 把不同元词组的得分加起来
- 不是直接相加,是进行指数的乘方运算翻译
- 引入了一个惩罚因子BP:因为短的翻译可能会更容易得到一个更高精度的,但是我们不想要那么短的翻译

- 有用的单一实数评估指标,用于评估生成文本的算法,判断输出的结果是否与人工写出的参考文本的含义相似
注意力模型直观理解
- 长句的问题:
- 基本模型:编码解码模型,读完一整个句子,再翻译
- 对短句子效果好,有比较高的Bleu分数
- 对长的句子表现变差,记忆长句子比较困难
- 人的翻译过程:看一部分,翻译一部分,一直这样下去
- 所以在基本的RNN中,对于长句会有一个巨大的下倾
- 下倾:衡量了神经网络记忆一个长句子的能力
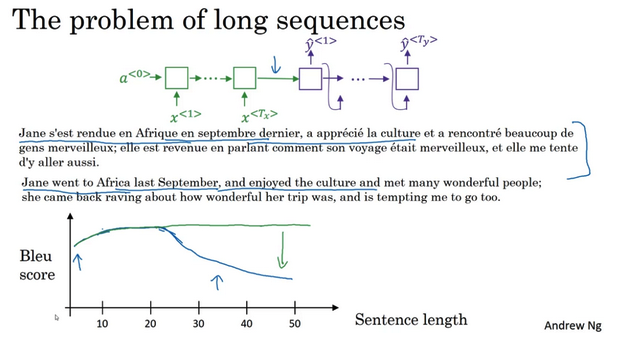
- 基本模型:编码解码模型,读完一整个句子,再翻译
- 注意力模型:
- 在生成第t个英文词时,计算要花多少注意力在第t个发语词上面

- 在生成第t个英文词时,计算要花多少注意力在第t个发语词上面
注意力模型
- 注意力模型:让神经网络只注意到一部分的输入句子,所以当生成句子的时候,更像人类翻译。
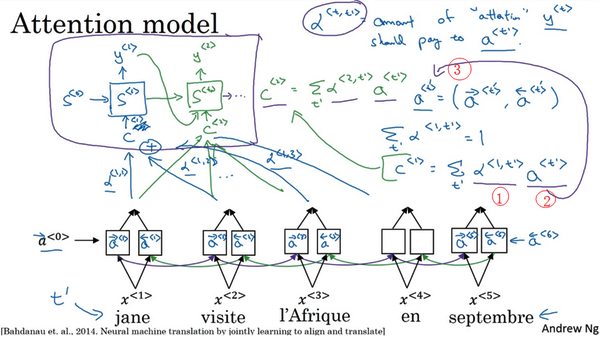
- 计算注意力:
- 使用对数形式,保证值的加和为1

- 缺点:花费三次方的时间
- 一般输出的句子不会太长,三次方也许是可以接受的
- 使用对数形式,保证值的加和为1
语音识别
- 语音视频问题:
- 输入:一个音频片段x
- 输出:自动生成文本y
- 处理步骤:原始音频片段 =》 生成一个声谱图 =》识别系统

- 音位模型:
- 曾经是通过音位来构建
- 音位:人工设计的基本单元
- 用音位表示音频数据
- 端到端的模型:
- 现在使用的
- 输入音频片段
-
直接输出音频的文本
- 需要很大的数据集:可能长达300小时
- 学术界:甚至达到3000小时
- 商业系统:超过1万小时的也有
- 注意力模型:
- 在输入音频的不同时间帧上,可以用一个注意力模型

- 在输入音频的不同时间帧上,可以用一个注意力模型
- CTC损失函数模型:
- CTC:connectionist temporal classification
- 比如输入一个10秒的音频,特征是100赫兹(每秒有100个样本),那么这个音频就有1000个输入
- 当有1000个输入时,对应的文本输出应该是没有1000个的。那怎么办?
- 引入空白符,用下划线”“表示,比如”h_eee“,”__qqq”等。
- CTC基本规则:将空白符之间的重复的字符折叠起来。
- CTC输出:可以强制输出1000个字符,但是包含空白符,它们是可以折叠的,最后uniq的字符会很少。

触发字检测
- 触发字检测系统:
- 通过声音来唤醒
- 不同的设备厂商有不同的触发字

- 检测算法:
- 处于发展阶段,最好的算法是什么尚无定论
- RNN结构:
- 计算音频片段的声谱图特征,得到特征向量
- 特征向量输入到RNN中
- 定义目标标签:在某个触发字的位置设为标签为1,说到触发字之前的位置设置标签为0。一段时间后,又说了触发字,此点设为标签1.
- 缺点:构建的是一个很不平衡的训练集,因为0比1的数量多很多。

- 解决:简单粗暴的,在固定的一段时间内输出多个1,而不是仅在一个时间步上输出1。可稍微提高1与0的比例。
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/sequence-models-5-sequence-models-attention-mechanism.html
Previous:
【5-2】自然语言处理与词嵌入
Next:
Auto encoder
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me