目录
1. 缺失值
- 真实的数据集包含缺失数据
- 缺失数据编码:空格,NaN,或其他占位符
- 使用含有缺失值数据基本策略:舍弃含有缺失值的行或者列。弊端:舍弃了可能有价值的(不完整的)数据。
-
更好的策略:从已有的数据进行推断,从而进行缺失数据填充(imputation)。
- 下面的表是现有的缺失值处理的方法的总结:
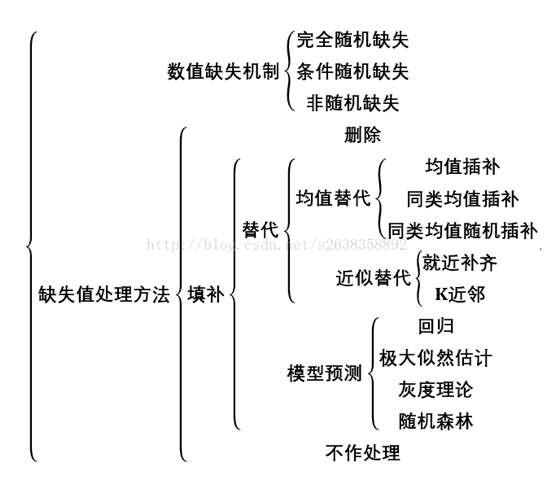
2. 插补方法:单变量 vs 多变量
- 单变量:值使用第
i个特征维度中的非缺失值来插补这个特征中的缺失值。类函数:impute.SimpleImputer - 多变量:使用整个可用特征维度来估计缺失值。类函数:
impute.IterativeImputer
3. 单变量插补
- 类函数:
impute.SimpleImputer - 可提供常数进行插补
- 可使用缺失特征列的统计量进行插补,比如平均值、中位数、众数
- 支持不同的缺失编码:比如数值型、字符型
>>> import numpy as np
>>> from sklearn.preprocessing import Imputer
# 使用特征列平均值插补
>>> imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
>>> imp.fit([[1, 2], [np.nan, 3], [7, 6]])
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
>>> X = [[np.nan, 2], [6, np.nan], [7, 6]]
>>> print(imp.transform(X))
[[ 4. 2. ]
[ 6. 3.666...]
[ 7. 6. ]]
# 对分类数据,使用频率进行插补
>>> df = pd.DataFrame([["a", "x"],
... [np.nan, "y"],
... ["a", np.nan],
... ["b", "y"]], dtype="category")
...
>>> imp = SimpleImputer(strategy="most_frequent")
>>> print(imp.fit_transform(df))
[['a' 'x']
['a' 'y']
['a' 'y']
['b' 'y']]
4. 多变量插补
- 类函数:
IterativeImputer - 原理:将每个缺失值的特征建模为其他特征的函数,建立好关系模型之后就可以对缺失的值进行估计。
- 具体步骤:每一轮,其他特征列为X(如果其他特征也含有缺失值,怎么使用?),缺失值包含列为输出y,使用回归器在未缺失数据上拟合,然后使用拟合模型对缺失的y值进行预测。迭代的方式对每个特征进行,重复
max_iter轮,最后一轮的计算结果被返回。
>>> import numpy as np
>>> from sklearn.experimental import enable_iterative_imputer
>>> from sklearn.impute import IterativeImputer
>>> imp = IterativeImputer(max_iter=10, random_state=0)
>>> imp.fit([[1, 2], [3, 6], [4, 8], [np.nan, 3], [7, np.nan]])
IterativeImputer(add_indicator=False, estimator=None,
imputation_order='ascending', initial_strategy='mean',
max_iter=10, max_value=None, min_value=None,
missing_values=nan, n_nearest_features=None,
random_state=0, sample_posterior=False, tol=0.001,
verbose=0)
>>> X_test = [[np.nan, 2], [6, np.nan], [np.nan, 6]]
>>> # the model learns that the second feature is double the first
>>> print(np.round(imp.transform(X_test)))
[[ 1. 2.]
[ 6. 12.]
[ 3. 6.]]
5. 缺失值标记
- 有时需要找到数据集中的缺失值
- 转换器:
MissingIndicator,将数据集转换为矩阵,可指示缺失值的存在 - 通常
NaN是占位符,可指定其他值为占位符
>>> from sklearn.impute import MissingIndicator
>>> X = np.array([[-1, -1, 1, 3],
... [4, -1, 0, -1],
... [8, -1, 1, 0]])
# 指定-1为缺失值
# 默认只返回包含缺失值的列,所以这里值显示了3列
>>> indicator = MissingIndicator(missing_values=-1)
>>> mask_missing_values_only = indicator.fit_transform(X)
>>> indicator.features_
array([0, 1, 3])
>>> mask_missing_values_only
array([[ True, True, False],
[False, True, True],
[False, True, False]])
# 设置参数 features="all"可以把其他的列的数据也指示出来
# 这种做法通常是我们想要的
>>> indicator = MissingIndicator(missing_values=-1, features="all")
>>> mask_all = indicator.fit_transform(X)
>>> mask_all
array([[ True, True, False, False],
[False, True, False, True],
[False, True, False, False]])
>>> indicator.features_
array([0, 1, 2, 3])
- 创建FeatureUnion,是的分类器能够处理数据
>>> transformer = FeatureUnion(
... transformer_list=[
... ('features', SimpleImputer(strategy='mean')),
... ('indicators', MissingIndicator())])
>>> transformer = transformer.fit(X_train, y_train)
>>> results = transformer.transform(X_test)
>>> results.shape
(100, 8)
# 使用pipeline,把特征转换放在模型之前
# 这样就会对数据先进行转换,再fitting
>>> clf = make_pipeline(transformer, DecisionTreeClassifier())
>>> clf = clf.fit(X_train, y_train)
>>> results = clf.predict(X_test)
>>> results.shape
(100,)
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/sklearn_imputation.html
Previous:
sklearn: 数据预处理2
Next:
模型评估与选择
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me