13: Clustering
- 聚类:从无标签的数据中学习,是非监督的学习。
- 监督式:有标签,用模型去拟合
- 非监督式:尝试鉴定数据的结构,基于数据的结构把数据聚集起来
- 场景:1)市场分割(顾客分类);2)社交网络分析;3)集群构架;4)天文数据分析(理解银河系信息)
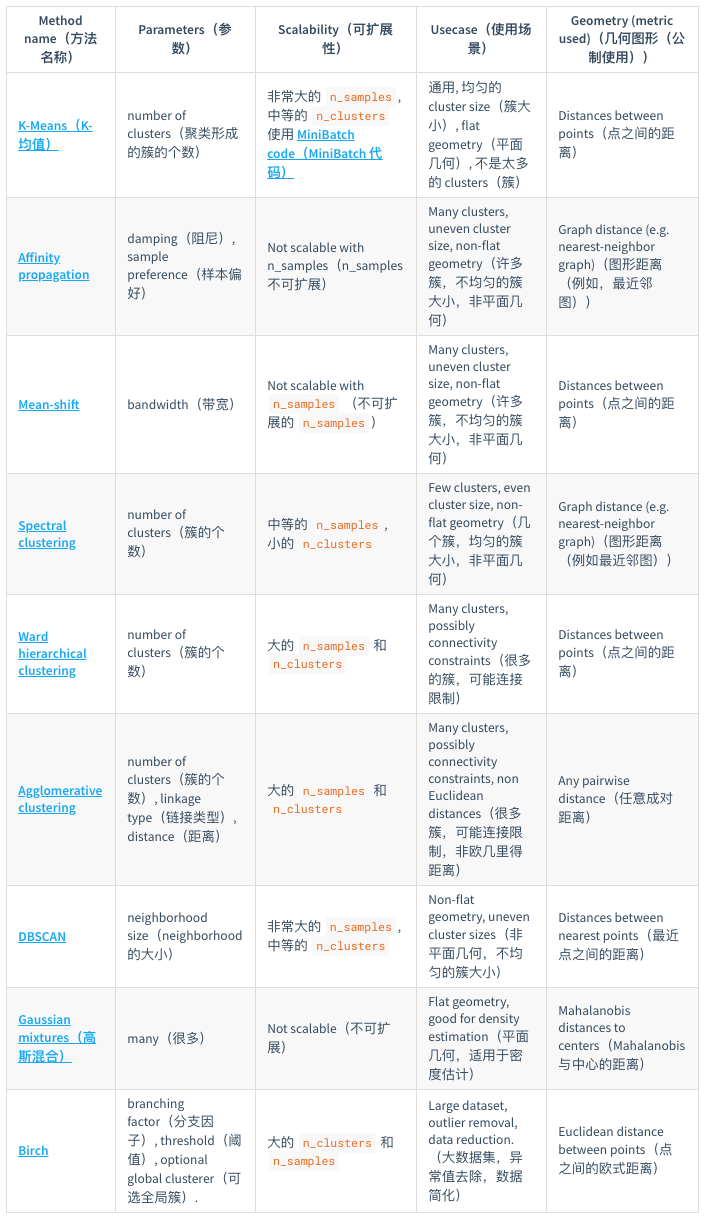
- sklearn提供了一个常见聚类算法的比较:
- k-means算法(至今最广泛使用的聚类算法):
- 【1】随机初始化类中心(比如K个)
- 【2】类分配(cluster assigned step)。对数据集中的每个样本,分配其属于最近的类中心的那个类。
- 【3】中心移动(move centroid step)。每个类的点的中心重新计算。
- 正式的定义:
- 比如K个类别,x1,x2,。。。,xn个样本,算法的步骤如下:

- 有的中心没有数据:
- 去除掉这个中心,最后得到K-1个类
- 重新对K个中心初始化选取(不一定100%work)
- 不易分隔的类别:
- 实际应用中,有的数据集或者问题没有明显的类别界限,亦可尝试k-means
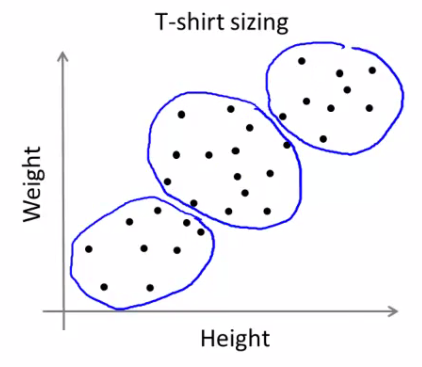
- 例子:根据身高和体重信息,做不同大小的衣服
- 损失函数:
- 和监督式学习一样,非监督式学习也有优化的目标或者损失函数
- 损失函数如下(最小化每个数据点与其所关联的聚类中心点之间的距离之和):
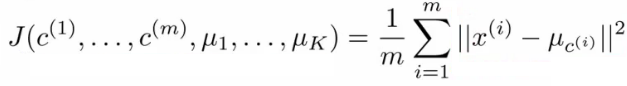
- 类分配步骤就是寻找合适的c1,c2,。。。,cm,使得损失函数最小
- 中心移动步骤就是寻找合适的μ,使得损失函数最小。
- 关于如何理解损失函数优化,可以参考这篇文章
- 随机初始化:
- 如何初始化以避免局部最优?
- 常见做法:随机从训练样本中选取K个作为初始的中心。
- 不同的初始化会得到不同的聚类结构,有可能陷入局部最优,比如下图:
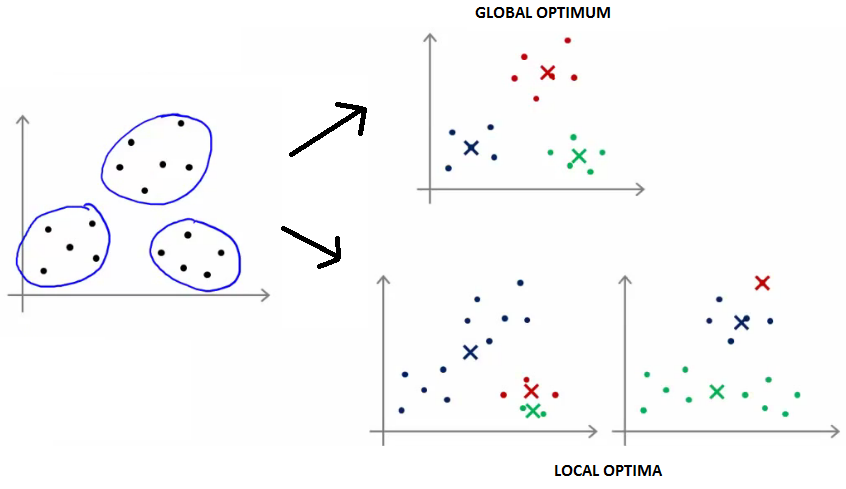
- 如何解决局部最优:可以多做几次(通常50-1000次)随机初始化,看结果是否都是这样的。更具体的是,随机初始化50-1000次,每次计算对应的损失值,取最小的损失值的。
- 当类别K在2-10时,多次随机初始化比较有效果
- 当类别K大于10时,多次随机初始化没有特别必要
- 如何选取类别数K:
- 没有好的自动化的方式进行设定,通常可以可视化数据集协助判断
- Elbow方法:选取一系列的K,画关于K的损失值分布,选取损失值最小所对应的K。
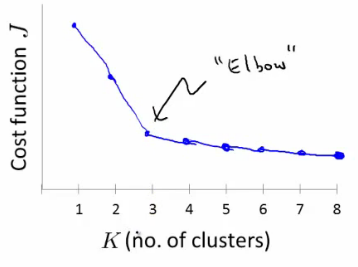
- 根据后续的结果反馈来判断,可以先做几个不同数目K的结果,根据此类别数据的用途来判断这种大小的K值是否合适。
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/CS229-13-clustering.html
Previous:
[CS229] 12: Support Vector Machines
Next:
深度学习
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me