目录
神经网络 neural network
- 构成:一层一层神经元
- 作用:帮助提取原始数据中的模式(特征),pattern feature extraction
- 关键:计算出每个神经元的权重
- 方法:使用BP算法,利用梯度递减或者随机梯度递减,得到每个权重的最优解
神经网络划分和比较
划分依据:
- 层数
- 神经元个数
- 模型复杂度
深浅神经网络比较:
- 浅层神经网络:shallow neural networks,比如上面的神经网络
- 深度神经网络:deep neural networks
神经神经网络例子:数字识别
- 在电脑视觉和语音识别领域应用广泛
- 一层一层的神经网络有助于提取一些物理特征
- 比如识别手写数字:
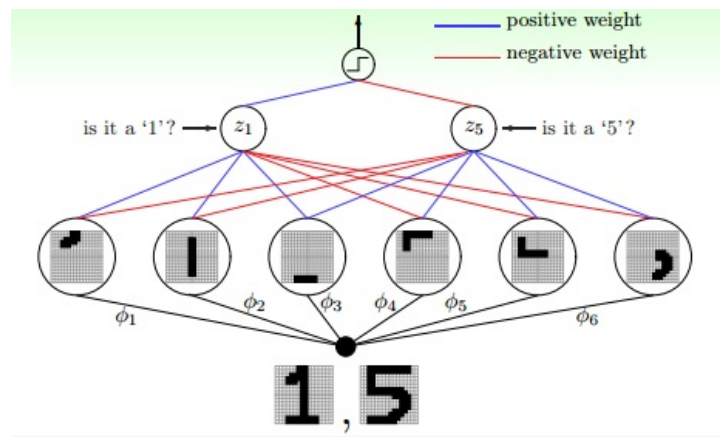
- 将数字图片分解,提取一块一块的不同部位的特征
- 1-3:每一个代表数字”1“的某个特征,合起来就是完整的数字”1“,这里权重是为正值的(蓝色),识别”1“时4-6的权重为负值
- 3-6:每一个代表数字”5“的某个特征,合起来就是完整的数字”5“,这里权重是为正值的(蓝色),识别”5“时1-2的权重为负值
深度学习的挑战与应对
- 难以确定应该使用什么样的网络结构:层次太深,可能性太多
- 模型复杂度很高
- 难以优化
-
极大的计算量
-
应对措施:

- 关键:
- 正则化:降低模型复杂度
- 初始化:优化训练,避免出现局部最优
- 常用:pre-train,【1】先对权重进行初始化的选择,【2】之后再用BP训练模型,得到最佳权重
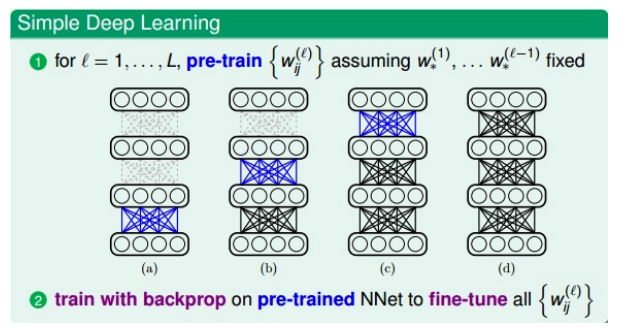
- 常用:pre-train,【1】先对权重进行初始化的选择,【2】之后再用BP训练模型,得到最佳权重
pre-training:autoencoder
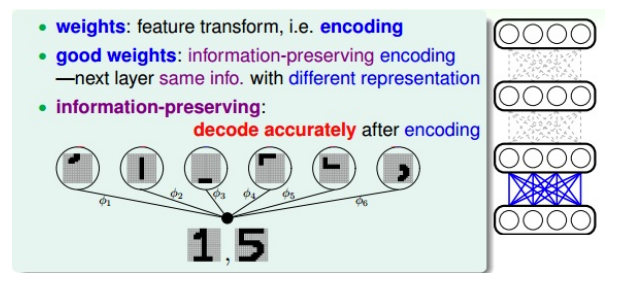
好的权重:最大限度保留特征信息
- 一种特征转换
- 也是一种编码,把数据编码成另外一些数据来表示
- 好的权重初始值?
-
尽可能的包含了该层输入数据的所有特征,类似于information-preserving encoding
- 数字的例子:
- 原始图片 -》特征转换 -》不同笔画特征
- 反过来:不同笔画特征 -》组合 -》 原始的数字
- information-preserving:可逆的转换,转换后的特征保留了原输入的特征,且转换是可逆的
- 这正是pre-train想要的
-
pre-train:如何得到好的初始权重
- 方法:
- 重构性网络:autoencoder
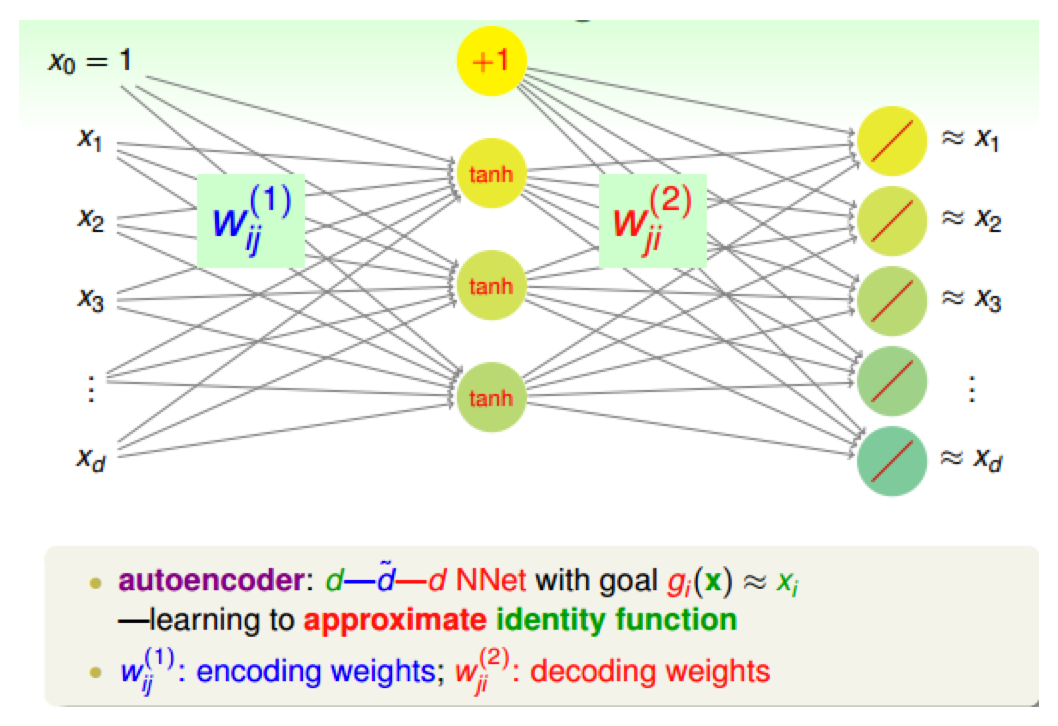
- 构建三层的神经网络,输入层,隐藏层,输出层
- 要求输出层和输入层是近似相等的
- 编码:输入层到隐藏层,\(W_{ij}^{(1)}\)是编码权重
- 解码:隐藏层到输出层,\(W_{ij}^{(2)}\)是解码权重
- 学习:逼近identity function
- 用途:
- 为什么要使用这种网络结构?或者为什么要去逼近identity function?
- 监督学习:
- 结构中包含了隐藏层,是对原始数据的合理转换 =》从数据中学习了有用的代表性信息
- 非监督学习:
- 密度估计:如果最终的输出g(x)与x很接近,则表示密度较大;如果相差甚远,则密度较小。
- 异常检测:知道哪些是典型的样本,哪些是异常的样本

- 核心:
- 隐藏层的信息,即编码权重
- 一般是对称性的结构,平方误差:\(\sum_{i=1}^d(g_i(x)-x_i)^2\)
- 限制条件:编码权重和解码权重相同,\(W_{ij}^{(1)}=W_{ij}^{(2)}\),起到了正则化的作用,使得模型不那么复杂
- 通常隐藏层的神经元数目小于输入层

- 训练过程:
- 对第一层(输入层)进行编码和解码,得到权重\(W_{ij}^{(1)}\)$,作为网络第一层到第二层的初始化权重
- 对网络第二层进行编码和解码,得到权重\(W_{ij}^{(2)}\)$,作为网络第二层到第三层的初始化权重
- 以此类推
-
直到深度学习网络中所有层与层之间都得到初始化权重
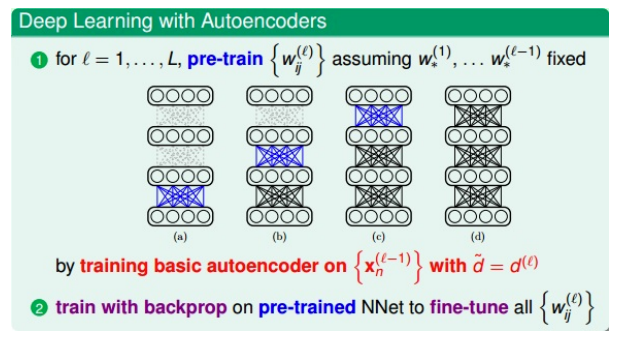
- 注意1:每次的目的是得到深度神经网络(自己定义的)中某两层之间(比如
l-1层到l层)的初始化权重,而这个权重是通过上面的简单的三层autoencoder网络训练的到的 - 注意2:对于深度神经网络中的
l-1层的网络,autoencoder中的隐藏层应该与深度神经网络中的下一层l层的神经元个数相同,这样才能得到相同数目的权重
控制复杂度:正则化
- 神经元和权重个数非常多
- 模型复杂度很大
- 需要正则化
- 常用的正则化方法:
- structural decisions/constrains
- weight decay or weight elimination regularizers
- early stopping
- denoising:在深度学习和antoencoder中效果很好
哪些原因导致模型的过拟合?
- 样本数量:数量少时易过拟合。如果数量一定,噪声的影响会很大,此时实现正则化的一个方式就是消除噪声。
- 噪声大小:噪声大时
如何去除噪声?
- 对数据进行清洗:直接操作,麻烦、费时费力
-
在数据中添加一些噪声:疯狂的操作
- 添加噪声的想法
- 来源:如何构建一个健壮的autoencoder
- autoencoder:编码解码后的g(x)会非常接近真实值x
- 如果对输入加入噪声,健壮的autoencoder,应该是使得输出g(x)同样接近真实值x
- 例子:识别数字,如果数字是歪斜的,经过编码解码后也能正确识别出来
- 所以这种autoencoder是很健壮的,起到了抗噪声和正则化的作用
denoising autoencoder
- 编码+解码
- 去噪声、抗干扰:输入一些混入了噪声的数据,仍然能够得到纯净的数据
- 加入噪声的数据集:\({(\check{x}_1, y_1=x_1),...,(\check{x}_N, y_N=x_N)}, \check{x}_n=x_n+noise\),\(x_n\)是纯净样本
- 训练目的:让\(\check{x}_n\)经过编码解码之后能恢复为纯净的\(x_n\)

linear autoencoder
- denoising autoencoder:非线性的,激活函数是tanh
- linear autoencoder:比较简单,PCA很类似
- 两者的计算:
- PCA会对原始数据进行减去平均值的操作
- 都可用于数据压缩或者降维,但是PCA更加广泛

参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/deep_learning.html
Previous:
[CS229] 13: Clustering
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me