概述
K-近邻算法(k-nearest neighbors, KNN):对于要进行分类的数据,与已知的数据进行比较,计算相似性,找出最相似的K个,然后看这个K个的所属类别,最高概率的类别即为目标变量的分类。
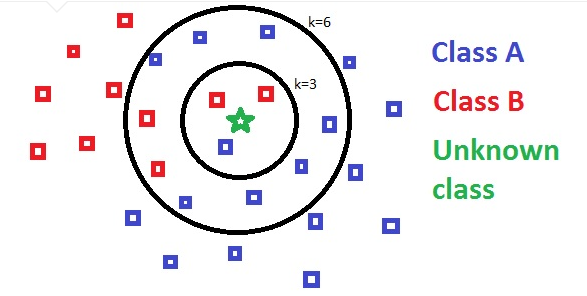
可视化图解 (KDnuggets):

- 原理:采用不同特征值之间的距离进行分类。
- 优点:精度高,对异常值不敏感,无数据输入假定
- 缺点:计算复杂性高,空间复杂度高
- 适用:数值型,标称型
当选定不同的K值大小时,预测对应的分类可能不同,所以需要尝试不同的K值。下图中,当k=3时,会预测为B类型,当k=6时,会预测为A类型。
实现
任务:改善约会网站的配对效果
数据集:(4列)
- 每年飞行里程数
- 玩游戏所占时间比例
- 每周消费的冰激凌公升数
- 约会好感度(标签列,largeDoses:魅力很大,smallDoses:魅力一般,didntLike:不喜欢)
gongjing@MBP ..eafileSyn/github/MLiA/source_code/Ch02 % head datingTestSet.txt
40920 8.326976 0.953952 largeDoses
14488 7.153469 1.673904 smallDoses
26052 1.441871 0.805124 didntLike
75136 13.147394 0.428964 didntLike
读取数据集的函数:
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
# label是最后一列,但是是str类型,不能用int转换
# classLabelVector.append(int(listFromLine[-1]))
classLabelVector.append(listFromLine[-1])
index += 1
return returnMat,classLabelVector
Python源码版本
归一化函数:在这个数据集中,不同的特征单位不同,数值差异很大,因而在计算不同样本的相似性时,数值大的特征会很大程度上决定了相似性的数值,所以需要把不同的特征都归一化到一致的范围。通常转换为[0,1]或者[-1,1],这里是通过转换将值归一化到0-1之间:newValue = (oldValue - min) / (max - min)
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
KNN分类函数(python是实现):
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
对约会数据进行读取分类:
def datingClassTest():
hoRatio = 0.50 #hold out 10%
datingDataMat,datingLabels = file2matrix('datingTestSet.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %s, the real answer is: %s" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
the classifier came back with: largeDoses, the real answer is: largeDoses
the classifier came back with: smallDoses, the real answer is: smallDoses
......
the total error rate is: 0.064000
32.0 # 当hold out数据比例为10%时,有5个预测错误了。
sklearn版本
df = pd.read_csv('./datingTestSet.txt', header=None, sep='\t')
df.head()
# 构建测试集和训练集
# 前面10%的数据作为测试集,后面90%的数据作为训练集
hoRatio = 0.1
X_test = df.ix[0:hoRatio*df.shape[0]-1, 0:2]
print X_test.shape
y_test = df.ix[0:hoRatio*df.shape[0]-1, 3]
print y_test.shape
X_train = df.ix[hoRatio*df.shape[0]:, 0:2]
print X_train.shape
y_train = df.ix[hoRatio*df.shape[0]:, 3]
print y_train.shape
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
metrics.accuracy_score(y_test, y_pred)
# accuracy: 0.76, 有24个预测错误了
参考
- 机器学习实战第2章
- ApacheCN:第2章 k-近邻算法
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/KNN.html
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me