概述
- 关联分析(association analysis)/关联规则学习(association rule learning):从大规模数据集中寻找物品间的隐含关系。
- 隐含关系的形式:
- 频繁项集(frequent item sets):经常出现在一块的物品的集合。经典例子【尿布与啤酒】:男人会在周四购买尿布和啤酒(尿布和啤酒在购物单中频繁出现)。
-
定量表示 -》支持度(support):数据集中包含该项集的记录所占的比例。
- 关联规则(association rules):暗示两种物品之间可能存在很强的关系。
-
定量表示 -》置信度(confidence):= support(P|H)/support(P),这里的
P|H是并集意思,指所有出现在集合P或者集合H中的元素。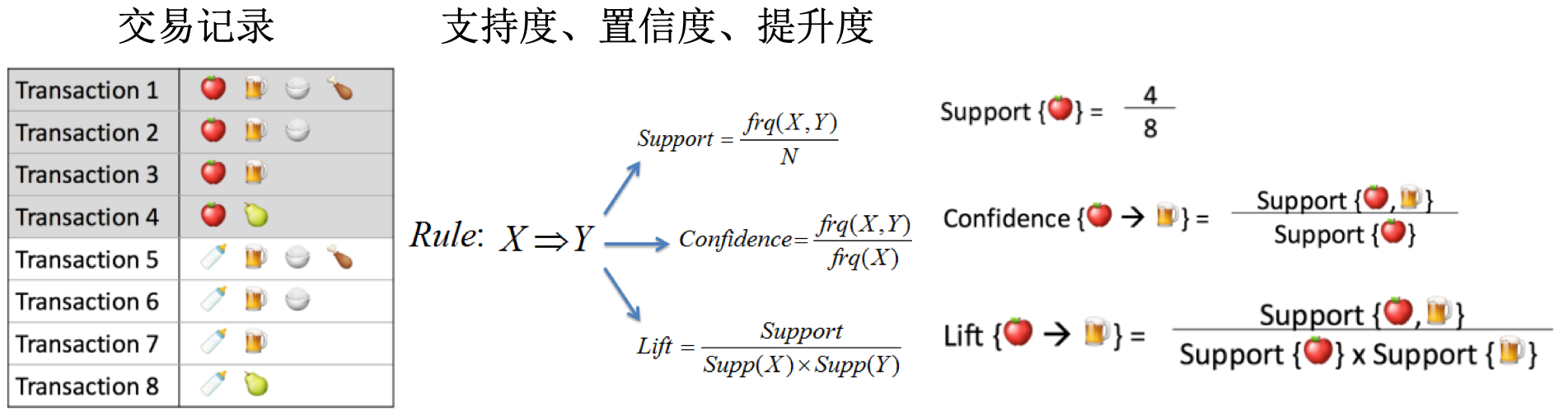
- 置信度存在一定的问题,因为只考虑了X的频率,没有考虑Y的频率。当Y本身的频率就很高时,(X,Y)的频率可能本来就很高,不一定存在强相关性。
- 引入提升度(lift):= support(P|H)/support(P)xsupport(H)。下面是个例子:beer和soda的置信度很高,但是lift值为1。
- 置信度越高,越可信。lift值接近1时,说明两者没有什么相关性。

- Apriori算法:
- apriori: 拉丁文,指来自以前。定义问题时通常会使用先验知识或者假设,称作一个先验(a priori)。在贝叶斯统计中也很常见。
- 目标:鉴定频繁项集。对于N种物品的数据集,其项集组合是2^N-1种组合,非常之大。
- 原理:如果某个项集是频繁的,那么它的所有子集也是频繁的。如果一个项集是非频繁的,那么它的所有超集也是非频繁的。
- 示例:这里演示了如果苹果不是一个频繁集,那么包含其的超集也不是的,可以不用寻找这部分以确定是否含有频繁集。

- 关联规则:
- 鉴定强相关的
- 使用置信度衡量相关性,同样采用apriori规则,以减少需要衡量的关系对数
实现
Python源码版本
Apriori算法:
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1)#use frozen set so we
#can use it as a key in a dict
def scanD(D, Ck, minSupport):
# 扫描集合D,把Ck中支持度低的item去掉
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if not ssCnt.has_key(can): ssCnt[can]=1
else: ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList, supportData
def aprioriGen(Lk, k): #creates Ck
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1==L2: #if first k-2 elements are equal
retList.append(Lk[i] | Lk[j]) #set union
return retList
def apriori(dataSet, minSupport = 0.5):
C1 = createC1(dataSet)
D = map(set, dataSet)
L1, supportData = scanD(D, C1, minSupport)
L = [L1]
k = 2
while (len(L[k-2]) > 0):
Ck = aprioriGen(L[k-2], k)
Lk, supK = scanD(D, Ck, minSupport)#scan DB to get Lk
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
关联规则生成函数:
def generateRules(L, supportData, minConf=0.7): #supportData is a dict coming from scanD
bigRuleList = []
for i in range(1, len(L)):#only get the sets with two or more items
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] #create new list to return
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq] #calc confidence
if conf >= minConf:
print freqSet-conseq,'-->',conseq,'conf:',conf
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): #try further merging
Hmp1 = aprioriGen(H, m+1)#create Hm+1 new candidates
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): #need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
Efficient-Apriori版本
sklearn没有直接可调用的工具,现在有现成的模块Efficient-Apriori,可以很方便的进行关联分析:
from efficient_apriori import apriori
transactions = [('eggs', 'bacon', 'soup'),
('eggs', 'bacon', 'apple'),
('soup', 'bacon', 'banana')]
itemsets, rules = apriori(transactions, min_support=0.5, min_confidence=1)
print(rules) # [{eggs} -> {bacon}, {soup} -> {bacon}]
处理大数据集:
def data_generator(filename):
"""
Data generator, needs to return a generator to be called several times.
"""
def data_gen():
with open(filename) as file:
for line in file:
yield tuple(k.strip() for k in line.split(','))
return data_gen
transactions = data_generator('dataset.csv')
itemsets, rules = apriori(transactions, min_support=0.9, min_confidence=0.6)
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/association_analysis.html
Previous:
K均值聚类算法
Next:
FP-growth算法来高效发现频繁项集
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me