目录
基本概念
- 特征:属性
- 相关特征:relevant feature,对当前学习任务有用的属性
- 无关特征:irrelevant feature,对当前学习任务没什么用的属性
- 特征选择:feature selection,从给定的特征集合中选择出相关特征子集的过程
- 数据预处理过程
- 一般学习任务:先进行特征选择,再训练学习器
- 为什么要特征选择?
- 减轻维数灾难问题。属性过段时,可以选择出重要特征,这点目的类似于降维。降维和特征选择是处理高维数据的两大主流技术。
- 去除不相关特征能降低学习任务难度。
- 需要:确保不丢失重要信息
- 冗余特征:一般是没用的,如果能对应学习任务所需的中间概念,则是有益的。比如学习立方体对象,给定底面长、底面宽、底面积,此时底面积是冗余的。如果是学习立方体体积,此时底面积是有用的,可以更快的计算。
特征子集搜索
如何根据评价结果获取候选特征子集?【子集搜索】
- 前向搜索:逐渐增加相关特征,forward
- 每个(总共d个)特征看做一个候选子集
- 对d个进行评价,选择最佳的一个作为此轮选定集,比如{a2}
- 加入一个特征,看加入哪个时是最优的,且需要优于上一轮的{a2},比如是{a2,a4}
- 假定在k+1轮时,最优的(k+1,在上一轮添加了一个)子集不如上一轮的好,则停止搜索
- 后向搜索:逐渐减少特征的策略,backward
- 所有特征作为一个特征集合
- 每次尝试去掉一个无关特征
- 双向搜索:结合前向和后向,bidirectional
- 每一轮增加选定的相关特征
- 减少无关特征
- 特点:
- 都属于贪心策略
- 仅考虑了使得本轮选定集最优
特征子集评价
如何评价候选特征子集的好坏?【子集评价】
- 信息增益:信息增益越大,特征子集包含的有助于分类的信息越多
- 划分:子集A确定了对于数据集D的一个划分,样本标记Y对应着对D的真实划分,估算这两个划分的差异,对A进行评估
特征选择分类
特征选择:子集搜索+子集评价
- 前向搜索+信息熵 =》决策树
- 分类:
- 过滤式:filter
- 包裹式:wrapper
- 嵌入式:embedding
sklearn的特征选择
- 模块:sklearn.feature_selection
- 可进行特征选择和数据降维
- 提高模型的准确度或者增强在高维数据上的性能
- 是特征工程的一部分
过滤式
- 过程:先进行特征选择,再训练学习器,特征选择与后续学习器无关
- Relief:
- Relevant Features
- 著名的过滤式特征选择方法
- 用“相关统计量”度量特征的重要性。是一个向量,每个分量分别对应一个初始特征。特征子集的重要性:等于子集中每个特征所对应的相关统计量分量之和。
- 【选择策略1】:指定阈值\(\tau\),比这个阈值大的分量所对应的特征保留
- 【选择策略2】:指定特征个数k,分量最大的k个特征保留
如何确定相关统计量?
- 训练集:\({(x_1,y_x),...,(x_m,y_m)}\)
- 每个样本\(x_i\),先在其同类样本中寻找其最近邻\(x_{i,nh}\) =》猜中近邻(near-hit)
- 再从其异类样本中寻找其最近邻\(x_{i,nm}\) =》猜错近邻(near-miss)
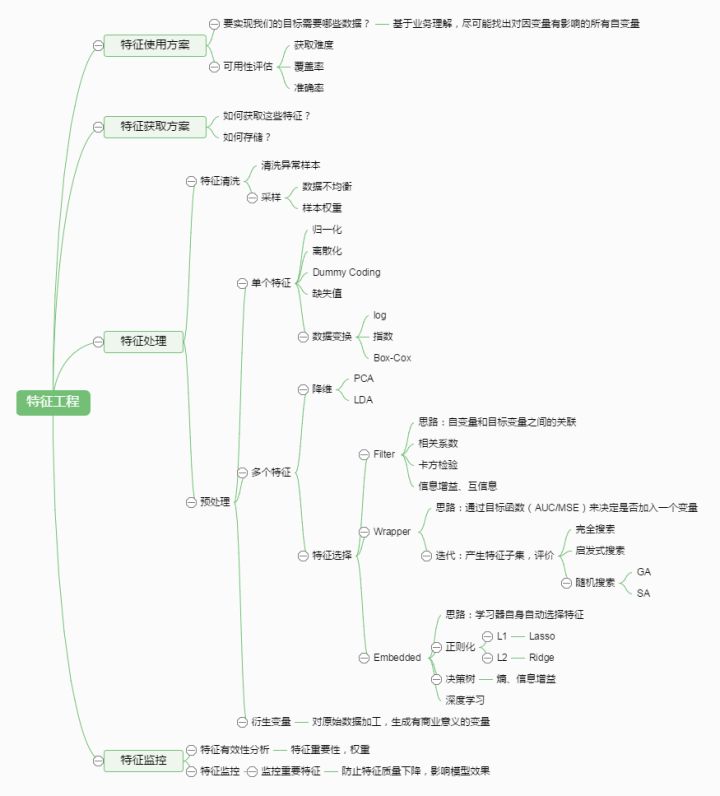
- 相关统计量关于属性j的分量为:\(\delta^j=\sum_{i}-diff(x_i^j,x_{i,nh}^j)^2+diff(x_i^j,x_{i,nm}^j)^2\)
- 属性j离散型:\(x_a^j=x_b^j => diff(x_a^j,x_b^j)=0\)
- 属性j连续型:\(diff(x_a^j,x_b^j)=\|x_a^j-x_b^j\|\)
- 如果样本\(x_i\)与其猜中近邻距离小于与猜错近邻的距离,则属性j对区分同类和异类样本是有益的 =》增大属性j对应的统计量分量
- 如果样本\(x_i\)与其猜中近邻距离大于与猜错近邻的距离,则属性j对区分同类和异类样本是无益的 =》减小属性j对应的统计量分量
- 上面是一个属性的一个样本的
- 推广到所有样本所有属性
- 所有样本得到的估计结果进行平均
- 各个属性的统计分量,分量值越大,对应属性的分类能力越强
- 注意:上面的式子是在给定的i上进行的,所以不一定非得在总的数据集上进行,可以在采样集合上进行
- 多分类:
- 二分类的扩展
- 样本来自\(\|Y\|\)个类别
- 若\(x_i\)属于\(k\)类
- 猜中近邻:在\(k\)类找最近邻
- 猜错近邻:除了\(k\)类之外的每个类中找一个最近邻
- 属性j的统计分量:
过滤式:移除低方差特征
- 函数:VarianceThreshold
- 原理:移除方差不满足一些阈值的特征。默认: 移除所有方差为0(取值不变)的特征。
例子:布尔值类型的的数据聚集,移除0或者1超过80%的特征: 注意:布尔值是伯努利随机变量,方差:\(Var[X] = p(1-p)\),如果选择阈值为0.8,则方差阈值=0.8(1-0.8)=0.8*0.2=0.16。可以看到,第一列特征被移除:
>>> from sklearn.feature_selection import VarianceThreshold
>>> X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
>>> sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
>>> sel.fit_transform(X)
array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])
过滤式:单变量特征选择
原理:对单变量进行统计测试,以选取最好的特征,可作为评估器的预处理步骤
- SelectKBest:只保留得分最高的k个特征
- SelectPercentile:移除指定的最高得分百分比之外的特征
- 常见统计测试量:SelectFpr(假阳性率), SelectFdr(假发现率), SelectFwe(族系误差)
- GenericUnivariateSelect:评估器超参数选择以选择最好的单变量
- 回归:f_regression,mutual_info_regression
- 分类:chi2,f_classif,mutual_info_classif
>>> from sklearn.datasets import load_iris
>>> from sklearn.feature_selection import SelectKBest
>>> from sklearn.feature_selection import chi2
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> X.shape
(150, 4)
>>> X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
>>> X_new.shape
(150, 2)
包裹式
- 包裹式:直接把最终要使用的学习器的性能作为特征子集的评价准则
- 目的:为给定的学习器选择最有利于其性能、量身定做的特征子集
- 一般效果更好
-
计算开销会大得多
- LVW:Las Vegas Wrapper
- 典型的包裹式特征选择方法
- 随机策略进行子集搜索,最终分类器的误差作为特征子集评价准则
- 算法:

- 误差评价:是在特征子集A’上。本来就是要选择最好的子集特征,当然是在这个子集上进行。
- 初始特征数很多、T设置较大:算法运行时间长达不到停止条件
包裹式:递归式特征消除
- 给定一个外部评估器(学习器):所以这个属于包裹式的?
- 对每一个特征,进行重要性评估
- 去除最不重要的特征
- 重复去除步骤,直到剩余特征满足指定特征数量为止
嵌入式
- 嵌入式:将特征选择过程与学习器训练过程融为一体,两者在同一优化过程中完成。学习器训练过程中自动进行了特征选择。
- 例子:
- 线性回归:求解不同属性的权重系数,对应了特征的重要性,求解出来也就决定了哪些特征是有益的
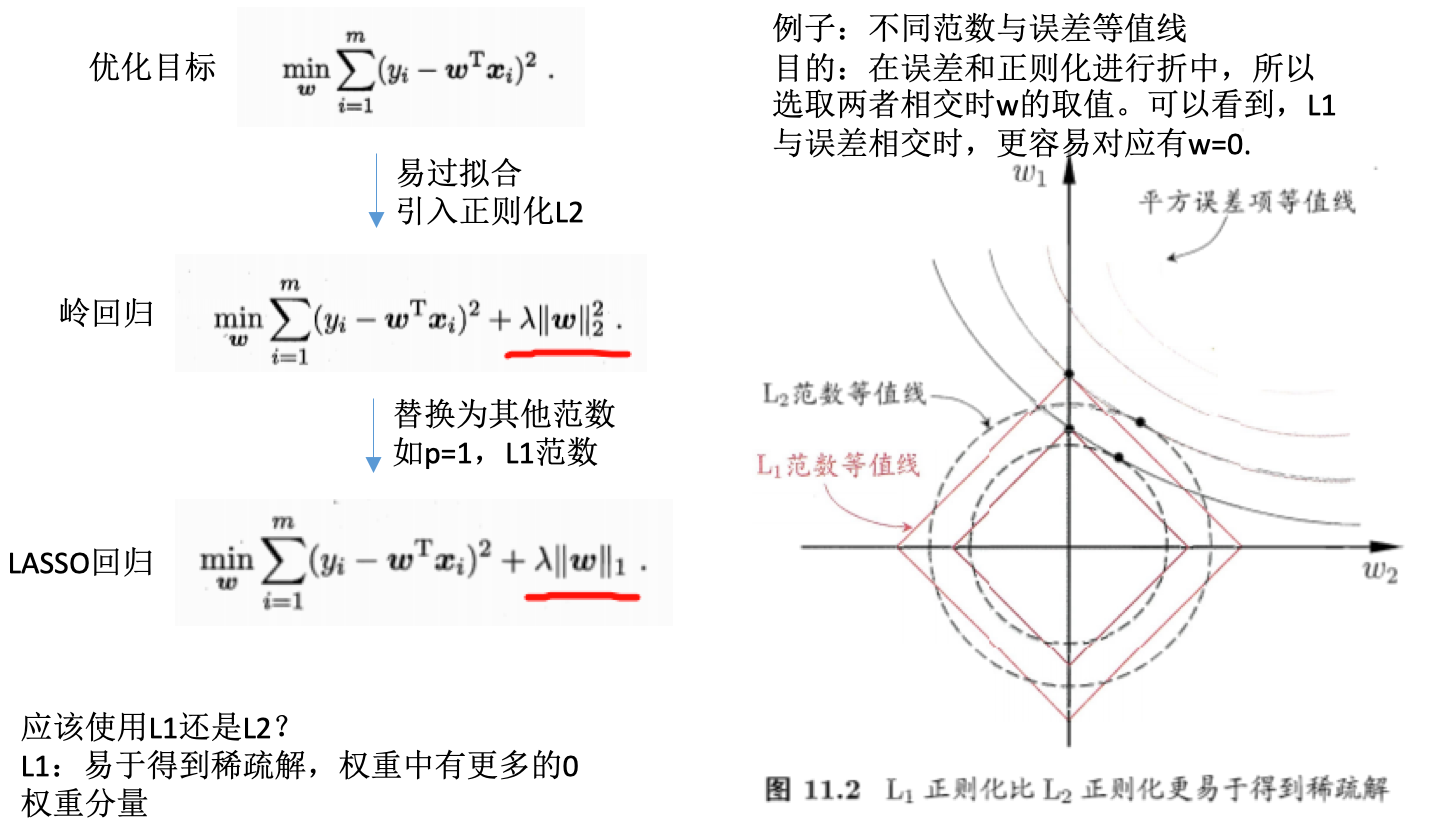
- 基于L1正则化的学习方法就是一种嵌入式的特征选择方法,把特征选择和学习器训练过程融为一体,同时完成。
- 线性回归:求解不同属性的权重系数,对应了特征的重要性,求解出来也就决定了哪些特征是有益的
- L1正则化求解:近端梯度下降PGD(proximal gradient descent)
嵌入式:SelectFromModel+L1的线性回归选取
- L1正则化:模型变得系数,很多系数为0
- 降低数据维度
- 选择非0系数特征
>>> from sklearn.svm import LinearSVC
>>> from sklearn.datasets import load_iris
>>> from sklearn.feature_selection import SelectFromModel
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> X.shape
(150, 4)
>>> lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
>>> model = SelectFromModel(lsvc, prefit=True)
>>> X_new = model.transform(X)
>>> X_new.shape
(150, 3)
嵌入式:SelectFromModel+树的选取
- 计算特征的相关性
- 消除不相关特征
>>> from sklearn.ensemble import ExtraTreesClassifier
>>> from sklearn.datasets import load_iris
>>> from sklearn.feature_selection import SelectFromModel
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> X.shape
(150, 4)
>>> clf = ExtraTreesClassifier()
>>> clf = clf.fit(X, y)
>>> clf.feature_importances_
array([ 0.04..., 0.05..., 0.4..., 0.4...])
>>> model = SelectFromModel(clf, prefit=True)
>>> X_new = model.transform(X)
>>> X_new.shape
(150, 2)
特征选取放在管道中
作为预处理的步骤:
clf = Pipeline([
('feature_selection', SelectFromModel(LinearSVC(penalty="l1"))),
('classification', RandomForestClassifier())
])
clf.fit(X, y)
参考
- 机器学习周志华:特征选择与稀疏学习
- sklearn 中文
- 机器学习中,有哪些特征选择的工程方法?@知乎
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/feature_selection.html
Previous:
判别生成模型、朴素贝叶斯、高斯判别分析
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me