kaggle
2018-07-12
注册
使用邮箱注册
安装kaggle-api
a. 安装python的kaggle模块,用于管理项目:
% pip install kaggle
DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future version of pip will drop support for Python 2.7.
Collecting kaggle
Downloading https://files.pythonhosted.org/packages/f4/de/4f22073f3afa618976ee0721b0deb72b5cde2782057e04a815a6828b53f9/kaggle-1.5.4.tar.gz (54kB)
100% |████████████████████████████████| 61kB 572kB/s
Collecting urllib3<1.25,>=1.21.1 (from kaggle)
Downloading https://files.pythonhosted.org/packages/01/11/525b02e4acc0c747de8b6ccdab376331597c569c42ea66ab0a1dbd36eca2/urllib3-1.24.3-py2.py3-none-any.whl (118kB)
100% |████████████████████████████████| 122kB 1.9MB/s
Requirement already satisfied: six>=1.10 in /Users/gongjing/usr/anaconda2/lib/python2.7/site-packages (from kaggle) (1.11.0)
Requirement already satisfied: certifi in /Users/gongjing/usr/anaconda2/lib/python2.7/site-packages (from kaggle) (2018.1.18)
Requirement already satisfied: python-dateutil in /Users/gongjing/usr/anaconda2/lib/python2.7/site-packages (from kaggle) (2.7.3)
Requirement already satisfied: requests in /Users/gongjing/usr/anaconda2/lib/python2.7/site-packages (from kaggle) (2.14.2)
Collecting tqdm (from kaggle)
Downloading https://files.pythonhosted.org/packages/9f/3d/7a6b68b631d2ab54975f3a4863f3c4e9b26445353264ef01f465dc9b0208/tqdm-4.32.2-py2.py3-none-any.whl (50kB)
100% |████████████████████████████████| 51kB 10.7MB/s
Collecting python-slugify (from kaggle)
Downloading https://files.pythonhosted.org/packages/c1/19/c3cf1dc65e89aa999f85a4a3a4924ccac765a6964b405d487b7b7c8bb39f/python-slugify-3.0.2.tar.gz
Collecting text-unidecode==1.2 (from python-slugify->kaggle)
Downloading https://files.pythonhosted.org/packages/79/42/d717cc2b4520fb09e45b344b1b0b4e81aa672001dd128c180fabc655c341/text_unidecode-1.2-py2.py3-none-any.whl (77kB)
100% |████████████████████████████████| 81kB 12.5MB/s
Building wheels for collected packages: kaggle, python-slugify
Building wheel for kaggle (setup.py) ... done
Stored in directory: /Users/gongjing/Library/Caches/pip/wheels/87/ea/09/173986e395d051411b9d547a69fe96cdc26208cb1bcc3e5567
Building wheel for python-slugify (setup.py) ... done
Stored in directory: /Users/gongjing/Library/Caches/pip/wheels/16/7f/c3/6b0582283ad589d68a306da924a78c74546e010d8106b9b3a9
Successfully built kaggle python-slugify
Installing collected packages: urllib3, tqdm, text-unidecode, python-slugify, kaggle
Successfully installed kaggle-1.5.4 python-slugify-3.0.2 text-unidecode-1.2 tqdm-4.32.2 urllib3-1.24.3
You are using pip version 19.0.3, however version 19.1.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
pip install kaggle 5.16s user 2.41s system 36% cpu 20.634 total
b. 在自己的账户下(https://www.kaggle.com/
gongjing@hekekedeiMac ~/.kaggle % pwd
/Users/gongjing/.kaggle
gongjing@hekekedeiMac ~/.kaggle % ls
kaggle.json
下载数据
% kaggle competitions download -c titanic
提交结果
kaggle competitions submit -c titanic -f submission.csv -m "Message"
Read full-text »
SQL例子
2018-07-06
- 表1 (table_1)
- 去重计数
- 聚合函数与group by
- 筛选 where/having
- 排序 order by
- 条件函数 case when
- 窗口函数
- 字符串
- 分组排序 row_number()
- 根据数值列取top,percentile
- 时间函数
- drop、delete、truncate
- 练习
- 易错题
- 参考
表1 (table_1)
| company | id | age | salary | sex |
|---|---|---|---|---|
| A | 001 | 13 | 50000 | F |
| A | 002 | 25 | 100000 | F |
| B | 003 | 50 | 200000 | M |
| C | 004 | 40 | 100000 | M |
| B | 005 | 40 | 150000 | F |
去重计数
# 罗列不同的id
# distinct: 表全部字段去重,不是部分字段
select distinct id from table_1
# 统计不同id个数
select count(distinct id) from table_1
# 优化版本的统计不同id个数
select count(*) from
(select distinct id from table_1) tb
# count(*): 包括所有列,相当于行数,不忽略值为NULL的
# count(1):与count(*)一样。
# count(列名):值包含列名所在列,统计时会忽略NULL
# count时需要看所在列是否可能存在空值NULL
# 例子
CREATE TABLE `score` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sno` int(11) NOT NULL,
`cno` tinyint(4) NOT NULL,
`score` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ;
A.SELECT sum(score) / count(*) FROM score WHERE cno = 2;
B.SELECT sum(score) / count(id) FROM score WHERE cno = 2;
C.SELECT sum(score) / count(sno) FROM score WHERE cno = 2;
D.SELECT sum(score) / count(score) FROM score WHERE cno = 2;
E.SELECT sum(score) / count(1) FROM score WHERE cno = 2;
F.SELECT avg(score) FROM score WHERE cno = 2;
# ABCE:sum(score)除以行数
# DF:sum(score)除以score不为NULL的行数
# avg(score):会忽略空值
聚合函数与group by
# 聚合函数:基本的数据统计,例如计算最大值、最小值、平均值、总数、求和
# 统计不同性别(F、M)中,不同的id个数
select count(distinct id) from table_1
group by sex
# 统计最大/最小/平均年龄
select max(age), min(age), avg(age) from table_1
group by id
- 聚合函数:
- 作为窗口函数时,与专用窗口函数用法相同,但是函数后括号不能为空,需指定聚合的列名
- 截止到本行数据,统计数据是多少,或者每一行数据对整体统计数据的影响
筛选 where/having
# 统计A公司的男女人数
select count(distinct id) from table_1
where company = 'A'
group by sex
# 统计各公司的男性平均年龄,并且仅保留平均年龄30岁以上的公司
select company, avg(age) from table_1
where sex = 'M'
group by company
having avg(age) >30
排序 order by
# 按年龄全局倒序排序取最年迈的10个人
select id,age from table_1
order by age DESC
limit 10
条件函数 case when
# 将salary转换为收入区间进行分组
# case函数格式:
# case when condition1 value1 condition2 value2 ... else NULL end
select id,
(case when CAST(salary as float)<50000 then '0-5万'
when CAST(salary as float)>=50000 and CAST(salary as float)<100000 then '5-10万'
when CAST(salary as float)>=100000 and CAST(salary as float)<200000 then '10-20万'
when CAST(salary as float)>=100000 then '20万以上'
else NULL and from table_1
窗口函数
- 场景:每组内排名
- 每个部门按照业绩来排名
- 找出每个部门排名前N的员工
- 窗口函数:
- OLAP函数,online analytical processing(联机分析处理)
- 可对数据库数据进行实时分析处理
- 基本语法:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
- 专用窗口函数:rank、dense_rank、row_number。注意:函数后面的括号不需要任何参数,保持()空着就行。
- 聚合函数:sum、avg、count、max、min
-
原则上只能写在select子句中,是对where或者group by子句处理后的结构进行操作
- group by vs partition by:
- group by:分组汇总后改变了表的行数,一行只有一个类别
- partition by:不会改变原表中的函数
- 为什么叫窗口函数?
- partition by分组后的结果称为窗口,表示范围的意思
- 功能1:同时具有分组和排序的功能
- 功能2:不减少原表的函数
- 语法:<窗口函数> over (partition by 分组列名 order by 排序列名)
字符串
拼接 concat
# 将A和B拼接返回
select concat('www', 'iteblog', 'com') from iteblog
切分 split
# 将字符串按照“,”切分,并返回数组
select split("1,2,3", ",") as value_array from table_1
# 切分后赋值
select value_array[0],value_array[1],value_array[2] from (select split("1,2,3", ",") as value_array from table_1) t
提取子字符串
# substr(str,0,len) : 截取从0位开始长度为len的字符串
select substr('abcde', 3, 2) from iteblog # cd
分组排序 row_number()
# 按照字段salary倒序排序
select *,row_number() over (order by salary desc) as row_num from table_1
# 按照字段deptid分组后再按照salary倒序编号
select *,row_number() over (partition by deptid order by salary desc) as rank from table_1
# rank:总数不变,排序相同时会重复,会出现1,1,3这种。并列名次会占用下一名次位置。
# dense_rank:总数减小,排序相同时重复,出现1,1,2这种。并列名次不会占用下一名次位置。
# row_number():排序相同时不重复,会根据顺序排序,不考虑并列名次的情况。
根据数值列取top,percentile
# 获得income字段top10%的阈值
select percentile(CAST(salary as int), 0.9) as income_top10p_threshold from table_1
# 获取income字段的10个百分位点
select percentile(CAST(salary as int), array(0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9)) as income_top10p_thresholds from table_1
时间函数
# 转换为时间格式数据
select to_date('1970-01-01 00:00:00') as start_time from table_1
# 计算数据到当前时间的天数差
select datediff ('2016-12-30','2016-12-29') # 1
# datediff(enddate,stratdate):计算两个时间的时间差(day)
# date_sub(stratdate, interval 2 day) :返回开始日期startdate减少days天后的日期
# date_add(startdate,days) :返回开始日期startdate增加days天后的日期
重要的内置MySQL日期函数(链接):
| 函数 | 功能 |
|---|---|
| now() | 返回当前的日期和时间 |
| curdate() | 返回当前的日期 |
| curtime() | 返回当前的时间 |
| date() | 提取日期,日期/时间表达式的日期部分 |
| extract() | 返回日期/时间的单独部分 |
| date_add() | 给日期添加指定的时间间隔 |
| date_sub() | 从日期减去指定的时间间隔 |
| datediff() | 返回两个日期之间的天数 |
| date_format() | 用不同的格式显示日期/时间 |
| day() | 取时间字段的天值 |
| month() | 取时间字段的月值 |
| year() | 取时间字段的年值 |
drop、delete、truncate
- drop:完全删除表,包括表结构
- delete:只删除表数据,保留表结构,而且可以加where,只删除一行或者多行
-
truncate:只删除表数据,保留表结构,不能加where
- 清理表数据的速度,truncate一般比delete更快
- truncate只删除表的数据不删除表的结构
练习
例:有3个表S,C,SC:
S(SNO,SNAME)代表(学号,姓名)
C(CNO,CNAME,CTEACHER)代表(课号,课名,教师)
SC(SNO,CNO,SCGRADE)代表(学号,课号,成绩)
问题:
1. 找出没选过“黎明”老师的所有学生姓名。
select sname from s where SNO not in
(
select SNO from SC where CNO in
(
select distinct CNO from C where CTEACHER == '黎明'
)
)
2. 列出2门以上(含2门)不及格学生姓名及平均成绩。
select s.sname, avg_grade from s
join
(select sno from sc where scgrade < 60 group by sno having count(*) >= 2) t1
on s.sno = t1.sno
join
(select sno, avg(scgrade) as avg_grade from sc group by sno ) t2
on s.sno = t2.sno;
3. 既学过1号课程又学过2号课所有学生的姓名。
select SNAME from
(select SNO from SC where CNO = 1) a
join
(select SNO from SC where CNO = 2) b
on a.sno = b.sno
# table A
Order_id User_id Add_time
11701245001 10000 1498882474
11701245002 10001 1498882475
# table B
id Order_id goods_id price
1 11701245001 1001 10
2 11701245001 1002 20
3 11701245002 1001 10
购买过goods_id 为1001的用户user_id:
A. select a.user_id from A a, B b where a.order_id = b.order_id and b.goods_id = '1001'
B. select user_id from A where order_id in (select order_id from B where goods_id = '1001')
C. select A.user_id from A left join B on A.order_id = B.order_id and B.goods_id = '1001'
# 使用SQL语句建个存储过程proc_stu,然后以student表中的学号Stu_ID为输入参数@s_no,返回学生个人的指定信息
CREATE PROCEDURE [stu].[proc_student]
@s_no AS int
AS
BEGIN
select * from stu.student where Stu_ID=@s_no
END
CREATE PROCEDURE [stu].[proc_student]
@s_no int
AS
BEGIN
select * from stu.student where Stu_ID=@s_no
END
易错题
- 下面哪个字符最可能导致sql注入?A: 单引号,B:/, C:双引号,D:$。 SQL注入的关键是单引号的闭合,因此选单引号。
-
select * from user_table where username=’xxx’ and password=’xxx’ or ‘1’=’1’,查询到所有用户信息,是单引号导致逻辑发生变化,达到恶意攻击的效果
- SQL主要四部分:
- 数据定义:DDL,data definition language。定义SQL模式、基本表、视图和索引的创建和撤销操作。
- 数据操纵:DML,data manipulation language。数据查询和更新。更新分为插入、删除和修改。
- 数据控制:DCL,data control language。对表和视图的授权,完整性规则的描述,事务控制等。
- 事务控制语言:TCL,transaction control language。SQL语句嵌入在宿主语言程序中使用的规则。
- 关系型数据库:
- 可以表示实体间的1:1,1:n,m:n关系
- 关系数据模型:使用表格表示实体和实体之间关系的数据模型
- 可以多对多
- SQL与C语言处理记录的方式是不同的。当将SQL语句嵌入到C语言程序时,为了协调两者而引入:游标。不是堆或者栈或者缓冲区。
- 游标:系统开设的一个数据缓冲区,存放SQL语句的执行结果集。每个游标有一个名字,用户可以用SQL语句逐一从游标中获取记录,赋值给主变量,交由主语言处理。
- insert into:向表格中插入新的行
-
select into:从一个表格中选取数据,然后把数据插入到另一个表中。通常用于创建表的备份或者对记录进行存档。
- 关系数据库事务的基本特征:ACID
- 原子性:atomic,事务的操作作为整体执行,要么全部执行,要么全部失败
- 一致性:consistency,数据在事务执行之前和之后,处于一致的状态
- 隔离性:isolation,多个事务之间是隔离的,互不影响
- 永久性:durability,一旦事务提交了,对数据库的修改是永久性的
- 数据库及线程发生死锁的原理:
- 系统资源不足
- 进程运行推进的顺序不合适
- 资源分配不当
- where分组前过滤,having分组后过滤,两者不冲突,可同时使用
- having子句必须与groupby子句同时使用,不能单独使用
- group by限定分组条件,对应列进行分组,相同值的被分为一组。当一个sql语句没有groupby时,整张表会自成一组
- 没有聚合函数的使用也可以用having过滤
参考
Read full-text »
sklearn: 官方例子
2018-07-05
目录
- 目录
- Miscellaneous
- Compact estimator representations [notebook]
- Isotonic Regression [notebook]
- Face completion with a multi-output estimators [notebook]
- Multilabel classification [notebook]
- Comparing anomaly detection algorithms for outlier detection on toy datasets [notebook]
- The Johnson-Lindenstrauss bound for embedding with random projections
- Comparison of kernel ridge regression and SVR [notebook]
- Explicit feature map approximation for RBF kernels [notebook]
- Examples based on real world datasets
- Datasets
- Classification
- Clustering
- Ensemble methods
- Discrete versus Real AdaBoost [notebook]
- Multi-class AdaBoosted Decision Trees [notebook]
- Decision Tree Regression with AdaBoost [notebook]
- Two-class AdaBoost [notebook]
- OOB Errors for Random Forests [notebook]
- Feature transformations with ensembles of trees [notebook]
- Feature importances with forests of trees [notebook]
- Pixel importances with a parallel forest of trees [notebook]
- Plot the decision surfaces of ensembles of trees on the iris dataset [notebook]
- Early stopping of Gradient Boosting [notebook]
- Gradient Boosting Out-of-Bag estimates [notebook]
- Prediction Intervals for Gradient Boosting Regression [notebook]
- Gradient Boosting regression [notebook]
- Gradient Boosting regularization [notebook]
- IsolationForest example [notebook]
- Hashing feature transformation using Totally Random Trees [notebook]
- Comparing random forests and the multi-output meta estimator [notebook]
- Plot the decision boundaries of a VotingClassifier [notebook]
- Plot class probabilities calculated by the VotingClassifier [notebook]
- Plot individual and voting regression predictions [notebook]
- Tutorial exercises
- 参考
Miscellaneous
Compact estimator representations [notebook]
- 目标:打印模型及参数,可以设置只打印非默认参数值的参数,否则会把全部的参数及其值打印出来。在
0.21.及之后的版本采用,之前的版本没有。 - 数据集:无
- 模型:无
Isotonic Regression [notebook]
- 目标:在生成数据集中,用线性回归和保序回归对数据进行拟合。保序回归不假设其预测是线性的,所以可以预测非线性的关系。
- 数据集:随机生成的二维数据点
- 模型:Isotonic regression(保序回归),线性回归
Face completion with a multi-output estimators [notebook]
- 目标:预测脸图像的下半部分。根据上半部分的像素数据进行模型训练,预测下半部分图像的像素值。图像的下半部分是很多的像素矩阵,所以预测的输出值是一个矩阵,属于multi-output的
- 数据集:fetch_olivetti_faces
- 模型:ExtraTreesRegressor,KNeighborsRegressor,LinearRegression,RidgeCV
Multilabel classification [notebook]
- 目标:对于多label的数据集先进行降维(PCA非监督降维,CCA是监督的降维),再进行分类,多标签的可以训练多个分类器。
- 数据集:随机产生
- 模型:PCA、CCA用于降维,OneVsRestClassifier的两个SVC线性内核的分类器
Comparing anomaly detection algorithms for outlier detection on toy datasets [notebook]
- 目标:评估不同的异常检测的算法
- 数据集:随机产生的二维数据,从单一的到多modal的分布
- 模型:robust covariance,one-class SVM,isolation forest,local outliner factor
The Johnson-Lindenstrauss bound for embedding with random projections
- 目标:
- 数据集:fetch_20newsgroups_vectorized
- 模型:
Comparison of kernel ridge regression and SVR [notebook]
- 目标:比较在随机数据上,核岭回归和SVR的效果
- 数据集:随机产生
- 模型:kernel ridge regression(KRR,核脊回归)vs SVR
- KRR:Ridge Regression(RR,脊回归)的kernel版本,与Support Vector Regression(SVR,支持向量回归)类似。引入kernel的RR,也就是KRR,能够处理非线性数据,即,将数据映射到某一个核空间,使得数据在这个核空间上线性可分。
- SVR:支持向量回归
Explicit feature map approximation for RBF kernels [notebook]
- 目标:通过不同的特征映射(变换)近似高斯内核。
- 数据集:digitals
- 模型:内核近似函数
RBFSampler,Nystroem
Examples based on real world datasets
Outlier detection on a real data set
- 目标:
- 数据集:
- 模型:
Compressive sensing: tomography reconstruction with L1 prior (Lasso)
- 目标:
- 数据集:
- 模型:
Topic extraction with Non-negative Matrix Factorization and Latent Dirichlet Allocation
- 目标:
- 数据集:
- 模型:
Datasets
The Digit Dataset [notebook]
原始的数据集在UCI machine learning reposity,包含10992个样本,sklearn这个版本是只去了其中的部分样本:
- 样本数目:1797
- 样本类别:0-9的手写数字图片
-
特征数目:64(8x8)
- 目标:选取了其中的一个数字例子,画了出来。
- 数据集:Handwritten Digits
- 模型:无
The Iris Dataset [notebook]
维基百科也关于鸢(yuān)尾花卉数据集(Anderson’s Iris data set)有详细的介绍:
- 样本数目:150
- 样本类别:3类,鸢(yuān)尾花卉的属,每一类50个数据。分别是山鸢尾(Setosa)、变色鸢尾(Versicolour)和维吉尼亚鸢尾(Virginica)
- 特征数目:4。花萼长度(Sepal.Length),花萼宽度(Sepal.Width),花瓣长度( Petal.Length),花瓣宽度(Petal.Width),单位:厘米
-
用途:预测花卉属于哪一类
- 目标:展示Iris数据集两个特征的分布餐点图,应用PCA做了数据的降维展示,原本有4个特征,降到3维进行展示(降维后的数据)。
- 数据集:Iris数据集
- 模型:PCA
Plot randomly generated classification dataset [notebook]
- 目标:在sklearn中产生用于分类的数据集,主要使用的是模块
sklearn.datasets,演示的函数包括:make_classification,make_blobs,make_gaussian_quantiles - 数据集:随机产生
- 模型:无
Plot randomly generated multilabel dataset [notebook]
- 目标:使用模块
sklearn.datasets中的函数make_multilabel_classification生成多标签的数据。 - 数据集:随机生成
- 模型:无
Classification
Recognizing hand-written digits [notebook]
- 目标:预测手写数字,前一半数据用于训练,预测后一半数据,画出了几个例子
- 数据集:digital数据集
-
模型:SVM高斯内核
- 图像数据转换:
data = digits.images.reshape((n_samples, -1)),把原来的(1797, 8, 8)数据转换为(1797, 64)维,进行训练 - 使用了评估量:classification_report+confusion_matrix
Clustering
Feature agglomeration [notebook]
- 目标:对于手写数字数据集,合并相似的特征,进行特征聚集。这里是将原始的数据集经过特征聚集从64变为32(reduced),基于这个数据也可以重建回原来的数据集(restored)。
- 数据集:digitals
- 模型:特征聚集
cluster.FeatureAgglomeration
Demo of DBSCAN clustering algorithm [notebook]
- 目标:在生成的数据集上进行DBSCAN聚类,并计算不同的评估聚类效果的统计量
- 数据集:生成数据集,750x2
- 模型:DBSCAN聚类
Color Quantization using K-Means [notebook]
- 目标:对一个RGB图片(427x640x3),用kmeans对颜色进行聚类,得到64个新的颜色中心值,然后预测原来图片的每个像素点的新的RGB值(从这64个选取一个),然后就可以画新的只有64个颜色值所表示的图片了。实现了用64个颜色表示原来的96615个颜色的,可以极大的降低了图片存储的大小。
- 数据集:一张图片(china.jpg),427x640x3
- 模型:kmeans聚类
Ensemble methods
Discrete versus Real AdaBoost [notebook]
- 目标:
- 数据集:
- 模型:
Multi-class AdaBoosted Decision Trees [notebook]
- 目标:
- 数据集:
- 模型:
Decision Tree Regression with AdaBoost [notebook]
- 目标:
- 数据集:
- 模型:
Two-class AdaBoost [notebook]
- 目标:
- 数据集:
- 模型:
###============================================================ [notebook]
- 目标:
- 数据集:
- 模型:
OOB Errors for Random Forests [notebook]
- 目标:
- 数据集:
- 模型:
Feature transformations with ensembles of trees [notebook]
- 目标:
- 数据集:
- 模型:
Feature importances with forests of trees [notebook]
- 目标:
- 数据集:
- 模型:
Pixel importances with a parallel forest of trees [notebook]
- 目标:
- 数据集:
- 模型:
Plot the decision surfaces of ensembles of trees on the iris dataset [notebook]
- 目标:
- 数据集:
- 模型:
Early stopping of Gradient Boosting [notebook]
- 目标:
- 数据集:
- 模型:
Gradient Boosting Out-of-Bag estimates [notebook]
- 目标:
- 数据集:
- 模型:
Prediction Intervals for Gradient Boosting Regression [notebook]
- 目标:
- 数据集:
- 模型:
Gradient Boosting regression [notebook]
- 目标:
- 数据集:
- 模型:
Gradient Boosting regularization [notebook]
- 目标:
- 数据集:
- 模型:
IsolationForest example [notebook]
- 目标:
- 数据集:
- 模型:
Hashing feature transformation using Totally Random Trees [notebook]
- 目标:
- 数据集:
- 模型:
Comparing random forests and the multi-output meta estimator [notebook]
- 目标:
- 数据集:
- 模型:
Plot the decision boundaries of a VotingClassifier [notebook]
- 目标:
- 数据集:
- 模型:
Plot class probabilities calculated by the VotingClassifier [notebook]
- 目标:
- 数据集:
- 模型:
Plot individual and voting regression predictions [notebook]
- 目标:
- 数据集:
- 模型:
Tutorial exercises
Digits Classification Exercise [notebook]
- 目标:对digital数据进行分类预测,前90%数据集训练,后10%用于测试
- 数据集:digital数据集
- 模型:KNN,logistic regression
Cross-validation on Digits Dataset Exercise [notebook]
- 目标:对digital数据使用SVM进行分类预测,并进行cross validation,所以这里不像上面的那样,自行拆分训练集和测试集。同时,还测试了模型SVC中的参数
C(Penalty parameter C of the error term.)取不同的数值大小时,随对应的cross_val_score。 - 数据集:digital数据集
- 模型:SVM
SVM Exercise [notebook]
- 目标:对Iris数据进行分类预测,使用SVM模型,并尝试不同的内核(参数
kernel指定)比较效果。 - 数据集:Iris数据集
- 模型:SVM的3个不同内核函数(linear线性,rbf高斯(默认),poly多项式)
Cross-validation on diabetes Dataset Exercise [notebook]
- 目标:对diabetes数据进行多分类预测,使用交叉检验
- 数据集:diabetes数据集
-
模型:线性模型LassoCV和Lasso
- 数据集diabetes
- 样本数目:442
- 特征数目:10,-.2 < x < .2之间的实数
- 类别数目:25 - 346,整数,所以是多分类的,不是二分类的
参考
Read full-text »
Data structure and algorithms
2018-07-05
数据结构与算法
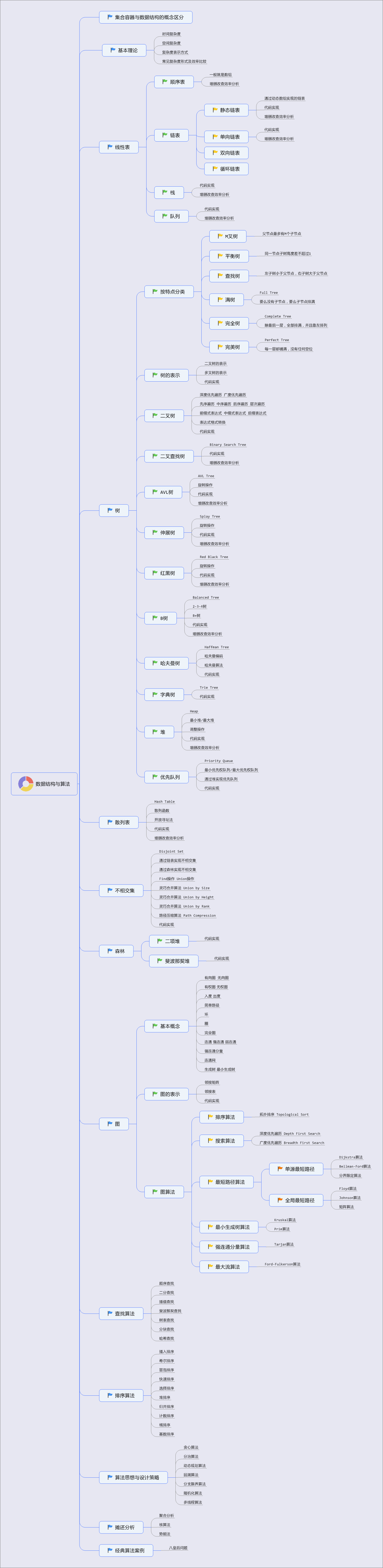
参考
Read full-text »
Think Stats: continuous distribution?
2018-07-02
连续分布:
- 经验分布(empirical distribution):基于观察,样本有限。对应的是连续分布(continuous distribution),更为常见。
- 指数分布(exponential distribution):观察一系列事件之间的间隔时间(interarrival time)。若事件在每个时间点发生的概率相同,那么间隔时间的分布就近似于指数分布。\(\begin{align} CDF(x) = 1 - e^{-\lambda x} \end{align}\)。指数分布的均值:1/λ,中位数是log(2)/λ。
- 判断分布是否符合指数分布:画出取对数后的互补累积分布函数(Complementary CDF,CCDF):1 - CDF(x), \(\begin{align} 1-CDF(x) = e^{-\lambda x} \end{align}\),取对数, \(\begin{align} logy = -\lambda x \end{align}\),在y取对数之后,整体是一条直线(斜率为-λ)。
- 帕累托分布:描述财富分布情况。CDF: \(\begin{align} CDF(x) = 1 - {\frac{x}{x_m}}^{-\alpha} \end{align}\),其中xm是最小值。比如城镇人口分布。
- 判断分布是否符合帕累托分布:对两条数轴都取对数后,其CCDF应该基本上是一条直线。\(\begin{align} logy ≈ −\alpha(logx−logx_m) \end{align}\)。
- 威布尔分布是一个广义上的指数分布,源自故障分析。\(\begin{align} CDF(x) = 1−e^{−(x/λ)k} \end{align}\)。
- 正太分布(高斯分布):正态分布的CDF还没有一种准确的表达,最常用的一种形式是以误差函数(error function):
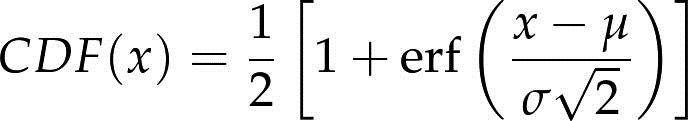
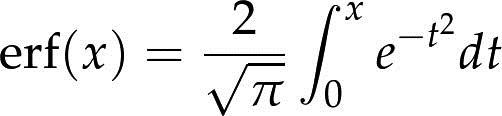
参数μ和σ决定了分布的均值和标准差。其CDF是S形的曲线。
- 正太分布不能像其他的分布一样,通过转换,判断是否属于正太分布。可用正态概率图(normal probability plot)的方法,它是基于秩变换(rankit)的,所谓秩变换就是对n个服从正态分布的值排序,第k个值分布的均值就称为第k个秩变换。
- 对数正太分布:一组数值做对数变换后服从正态分布。人的体重服从对数正太分布。
术语:
- 连续分布(continuous distribution) 由连续函数描述的分布。
- 语料库(corpus) 特定语言中用做样本的正文文本。
- 经验分布(empirical distribution) 样本中值的分布。
- 误差函数(error function) 一种特殊的数学函数,因源自误差度量研究而得名。
- 一次频词(hapaxlegomenon) 表示语料库中只出现一次的词。这个单词在本书中迄今出现了两次。
- 间隔时间(interarrival time) 两个事件的时间间隔。
- 模型(model) 一种有效的简化。对于很多复杂的经验分布,连续分布是不错的模型。
- 正态概率图(normal probability plot) 一种统计图形,用于表示样本中排序后的值与其服从正态分布时的期望值之间的关系。
- 秩变换 (rankit) 元素的期望值,该元素位于服从正态分布的已排序列表中。
Read full-text »
Adobe Illustrator usage
2018-06-28
Adobe Illustrator (AI)
Install:
Refer to Adobe Illustrator CC 2017 MAC中文破解版
AI 官方用户指南 (中文版)
简介
工作区
绘图
常规操作
- 裁剪图片:
- 操作:先在图片上画一个形状(比如长方形、圆圈等),然后同时选择该形状和图片,再
command+7快捷键,即完成剪切操作。
- 操作:先在图片上画一个形状(比如长方形、圆圈等),然后同时选择该形状和图片,再
- 改变点的大小:
- 操作:可以改变对象的大小、旋转角度等,比如可以用来改变散点图中点的大小
- 路径:
object -> transform -> transform each - 快捷键:
shift+option+cmd+d
- 更改某个部分的对象:
- 操作:对于某个图像的局部进行更改,比如更改某个panel的图的点的大小
- 具体:以改变某个三店图为例,首先选取要更改的部分,然后成组。再选中这个组,此时整体图上的其他部分应该是不可选的。接着选取此组中的某个点,选择相同的对象,则只会选中此组中的点对象,从而可以进行颜色更改、大小控制等操作。
- 释放剪切模板:
- 操作:对于一些点对象,看起来是个点,其实很能还有正方形的外圈等对象,这些对象容易影响后面对于点对象的操作,可以先去除这些对象。一般先选择某个点,然后释放剪切模板,拖拉把除了点以外的对象选中,选择具有相同属性的其他对象,全部去除。
- 路径:
select -> same -> fill & stroke - 快捷键:
option+cmd+7。
- 成组:
- 操作:把不同的对象group起来进行变换等
- 路径:
object -> group - 快捷键:
cmd+g
- 解组:
- 操作:把成组的对象进行解组
- 路径:
object -> ungroup - 快捷键:
shift+cmd+g
- 画透明的圆圈:
- 操作:画一个圆圈,或者其他形状,设置为透明的,方便相互重叠,比如画韦恩图
- 方案1:直接用shaper tool手动画一个椭圆,会自动识别生成一个圆圈。设置填充为None,线条选定颜色即可。
- 方案2:直接用shaper tool手动画一个椭圆,会自动识别生成一个圆圈。在工作区上方有个不透明度(Opacity),可根据需要阈值进行设置,这个与上面的区别是线条也会受到这个阈值的调控,所以当设置不透明度为0(即完全透明)时,线条也是看不见的,即使设置线条很粗也没用。
- 方案3:直接用shaper tool手动画一个椭圆,会自动识别生成一个圆圈。在右侧工具栏使用透明(transparent)工具,这个的问题和上面的不透明度(Opacity是一样的。
- 吸管工具:
- 【填充 -> 填充】吸取一个对象1的填充色作为对象2的填充色:按下
V键,切换到选择工具,单击待填充对象2,然后按下I键,切换到吸管工具,鼠标变为一支吸管,在对象1单击,就可以将对象1的填充颜色复制填充到对象2上。 - 【填充 -> 轮廓】吸取一个对象1的填充色作为对象2的轮廓色:按下
V键,切换到选择工具,单击待填充对象2,单击工具箱中的轮廓,将轮廓色放在上方。按下I键,切换到吸管工具,鼠标变为一支吸管,按着Shift键,在对象1单击吸取颜色,这样就可以将吸取的颜色放在对象2的轮廓上了。 - 【文字 -> 文字】:类似于上面的【填充 -> 填充】操作,只不过对象全部换为文字,可以吸取文字的大小、颜色、字体等熟悉。
- 【吸取界面之外的颜色】:按下
V键,切换到选择工具,单击待填充对象,然后按下I键,切换到吸管工具,鼠标变为一支吸管,按住鼠标左键不放,将光标移到AI界面之外的任意目标颜色处,释放鼠标,即可将吸取的颜色填充到需要改变颜色的图像上面。
- 【填充 -> 填充】吸取一个对象1的填充色作为对象2的填充色:按下
- 设置同一行换行文字间距:
- 选中要设置的文字,然后调成文本属性(
command+t),设置文字:VA加下划线的,即可调整间距。可参考这里
- 选中要设置的文字,然后调成文本属性(
- 文本框自动换行:
- 如果是正常的文字,是不能自动换行的。需要
画一个文本框,具体就是:选中文本按钮,在画布中拖出一个一定长宽的文本框,那么这个框里面的文字是会自动换行的。
- 如果是正常的文字,是不能自动换行的。需要
- 设置不同行文字间距(段落间距):
- 选中要设置的文字段落,然后选择
段落(Paragraph)属性,在这里可以设置文字的对齐方式,一般选择中间的两段对齐,多余行左对齐。在下方可以设置段落间距(类似于word里面的行间距)。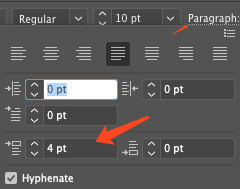
- 选中要设置的文字段落,然后选择
- 整个画板变为灰色网格?
- 因为其默认的快捷键是
shift+cmd+D - 有时候想想设置元素大小,使用快捷键
shift+option+cmd+d,但是不小心点错了 - 具体效果可以参考这里:ai画板与背景整个变成灰色格子了?
- 因为其默认的快捷键是
- 更改画布大小
- 在右侧artboard里面选择画布
- artboard界面中,右上角列表按钮下拉,选择
artboard options - 设置宽和高
- 也可以在顶部断则
Document Setup,有edit board选项,也可设置 - 具体可以参考这里:ai怎么调整画布尺寸? ai设置画布大小的两种方法
- 统一多个长方形的大小
- 选择要选取的多个长方形
- 先把这些选择的对象转换为形状:
对象=>形状=>转换为形状 - 然后设置形状的长宽,即可统一所有的大小
- 调整一段文字的行间距
- 选择要调整的文字
- MAC下面:
option+→:扩展字间距,option+←:缩小字间距,option+↑:缩小行距,option+↓:扩展行距 - 参考这里
快捷键
官方博客图片:
Read full-text »
Think Stats: cumulative disribution function?
2018-06-21
累积分布函数:
- PMF缺点:如果要处理的数据比较少,PMF很合适。但随着数据的增加,每个值的概率就会降低,而随机噪声的影响就会增大。解决策略:1)根据bin划分区间,如何确定bin的数目比较难;2)累计分布函数(Cumulative Distribution Function,CDF)。
- 百分位数(percentile):不高于某个值所占的比例再乘以100。转换:给定值,计算百分位数;对于给定的百分位数,计算对应的值。
- CDF:值到其在分布中百分等级的映射。如果x比样本中最小的值还要小,那么CDF(x)就等于0。如果x比样本中的最大值还要大,那么CDF(x)就是1。
- 条件分布:根据某个条件选择的数据子集的分布。通常不同的实验,条件不同,不能直接的相互比较。可以通过转换为对应组别的百分位数进行比较。
- 再抽样(resampling):根据已有的样本生成随机样本的过程。有放回和无放回:取球问题。
- CDF推出:中位数(median)就是百分等级是50的值;25和75百分等级通常用来检查分布是否对称,这两者间的差异称为四分差(interquartile range),表示分布的分散情况。
术语:
- 条件分布 (conditional distribution) 在满足一定前提条件下计算出的分布。
- 累积分布函数(Cumulative Distribution Function,CDF) 将值映射到其百分等级的函数。
- 四分差 (interquartile range) 表示总体分散情况的值,等于75和25百分等级之间的差。
- 百分位(percentile) 与百分等级相关联的数值。
- 百分等级 (percentile rank) 分布中小于或等于给定值的值在全部值中所占的百分比。
- 放回 (replacement) 在抽样过程中,“有放回”表示对于每次抽样,总体都是不变的。“无放回”表示每个元素只能选择一次。
- 再抽样 (resampling) 根据由样本计算得到的分布重新生成新的随机样本的过程。
Read full-text »
Think Stats: hypothesis testing
2018-06-20
假设检验:
- 效应具有统计显著性,指这种情况在一次试验中不大可能发生。
- 原假设:null hypothesis,观测到的由偶然因素造成;p值:p-value,在原假设下,出现直观效应的概率;解释:interpretation。
- 发现第一胎婴儿(m)怀孕周期的均值略长于非第一胎婴儿(n)怀孕周期的均值,检验:
- 把所有数据混合在一起
- 随机分成两组,一组等于m,另一组等于n,计算两组之间平均值的差异
- 重复1000次,计算均值的分布
- 选定阈值(比如一个方差),计算位于之外的概率(17%)
- 这里使用的是重抽样(resampling)的方法
- I类错误(type I error, 假阳性,false positive):接受本质为假的假设
- II类错误(type II error,假阴性,false negative):推翻本质为真的假设
- 假设检验中最常用的方法是为p值选择一个阈值α,通常为5%。
- 同时降低两类错误的方法:增加样本量。
- 效应:在NSFG数据中,我们将效应定义为“两个分组的均值差(不分正负)大于等于δ”。所以效应是指需要评估的具体的定义?
- 双边检验:不关注相对大小;单边检验:只关注某一边的大小,通常p值比双边检验更低。
- 解释统计结果:1)古典解释:比较p值和阈值;2)实际解释:只求越低越好;3)贝叶斯统计解释。
- 交叉验证:构建不同的数据集来计算条件概率。避免抽样引入的误差:即使原假设是真的,也可能因为随机抽样的缘故而导致两个分组的均值有差别(δ)。
- 似然比(likelyhood ratio) P(E|HA)/P(E|H0),报道贝叶斯概率时采用这个,而不再关注后验概率。
- 卡方检验:场景:均值可能没有差异,但是分布的方差可能存在差异,但是通常方差的鲁棒性较差,统计检验通常表现较差。卡方统计量:检验观测值和期望值的离差平方和的均值。
- 高效再抽样:通过运用部分的计算的性质,从理论推导结果。
- 统计功效(statistical power)指的是在原假设为假的情况下,检验的结果为阳性的概率。一般地,一个统计检验的功效依赖于样本数量、效应的大小和我们设置的阈值α。
术语:
- 单元格(cell) 在卡方检验中,将观测按一定的标准分到各个单元格里,每个单元格代表一种分类。
- 卡方检验(chi-square test) 用卡方统计量做统计量的统计检验 。
- 交叉验证(cross-validation) 交叉验证使用一个数据集进行探索性数据分析,然后用另一个数据集进行测试。
- 假阴性(false negative) 在效应真实存在的情况下,我们认为这个效应是由偶然因素引起的。
- 假阳性(false positive) 在原假设为真的情况下,我们拒绝了原假设的结论。
- 假设检验(hypothesis testing) 判定出现的效应是否具有统计显著性的过程。
- 似然比(likelihood ratio) 一种概率的比值, P(E|A)/P(E|B),这里A和B是两种假设。似然比不依赖于先验概率,可以用来报道贝叶斯统计推断的结果。
- 原假设(null hypothesis) 一种基于以下假设的模型系统:我们观测到的效应只是由偶然因素引起的。
- 单边检验(one-sided test) 一种检验类型,关注的是出现比观测到的效应更大(或小)的效应的概率。
- p值(p-value) 在原假设成立的情况下,出现我们观测到的效应的概率。
- 功效 (power) 在原假设为假的情况下,检验推翻原假设的概率。
- 显著性(significant) 我们说某个效应具有统计显著性指的是这种情况不大可能是由偶然因素引起的。
- 检验统计量(test statistic) 衡量观测到的效应与原假设下期望的结果之间偏差的统计量。
- 测试集(testing set) 用做测试的数据集。
- 训练集(training set) 用做训练的数据集。
- 双边检验(two-sided test) 一种检验类型,关注的是出现比观测到的效应更大的效应的概率,不考虑正负。
Read full-text »
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me