目录
- 目录
- 为什么是机器学习策略?
- 正交化
- 单一数字评估指标
- 满足指标和优化指标
- 训练集、开发集、测试集的分布
- 开发集和测试集的大小
- 什么时候该改变开发集/测试集合评估指标?
- 为什么跟人的表现进行对比?
- 可避免偏差
- 理解人的表现
- 超越人的表现
- 改善模型表现
- 参考
为什么是机器学习策略?
- 目标:学习如何更快速高效的优化你的机器学习系统
- 例子:
- 目标:猫分类器
- 当前效果:90%准确性;需要改善
- 尝试:
- 收集更多数据
- 更多样化的反例
- 训练更久的梯度下降
- 其他的优化算法如Adam
- 不同规模的神经网络
- dropout或者正则化

- 错误的尝试怎么办?
- 策略:
- 分析机器学习问题的方法
- 指引朝着最有希望的方向前进
正交化
- 正交化:效率很高的机器学习专家有个特点,就是思维清晰,对于要调整什么来达到某个效果,非常清楚,这个步骤就是正交化
- 例子:
- 电视图像的调节:
- 一个按钮调整高度
- 一个按钮调整宽度
- 一个按钮调整旋转角度
- 每一个按钮都有相对明确的功能,只能调整一个性质,这样调整电视图像会容易得多
- 开车:
- 方向盘:左右偏移
- 油门:速度
- 刹车:速度
- 电视图像的调节:
- 正交化概念:某一个维度,只改变某一个性质,这样在理想的情况下和实际想控制的性质一致,调整参数就容易得多。
- 机器学习的正交化:
- 调整模型的按钮,使得满足4点,如果哪点不满足,可以采取对应的能使得满足的策略,而不影响其他已经满足的点:
- 【1】在训练集上结果不错。可能策略:训练更大的网络、更好的优化算法。
- 【2】在开发集上有好的表现。可能策略:引入正则化、增大训练集。
- 【3】在测试集上也有好的表现。可能策略:对开发集过拟合,需要使用更大的开发集。
-
【4】在真实数据集上表现满意。可能策略:改变开发集或者成本函数

- 一般不使用early stop策略:难以分析,早起停止,对于训练集拟合不够好,同时能改善开发集表现,不是绝对的正交化。
单一数字评估指标
- 单实数评估指标:
- 快速告诉你所做的尝试是不是效果更好
- 例子:猫的识别
- 可以使用准确率和召回率评估模型的效果
- 但是如果是两个指标,一个指标在A比B好,另一个指标在B比A好,那么A和B到底谁好?
- F1分数:准确率和召回率的调和平均数(\(F_1=\frac{2}{\frac{1}{P}+\frac{1}{R}}\))
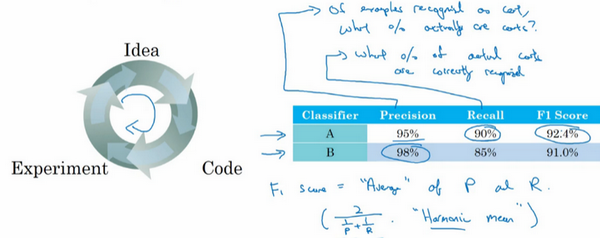
- 最好找一个单实数评估指标,以选择模型,能提高模型迭代的效率
- 例子:分类器在不同的测试集上表现不同
- 在不同的地区错误率不一样
- 哪个分类器效果好?
- 平均值:假设平均值是一个合理的单实数评估指标,通过计算平均值,可以快速判断。
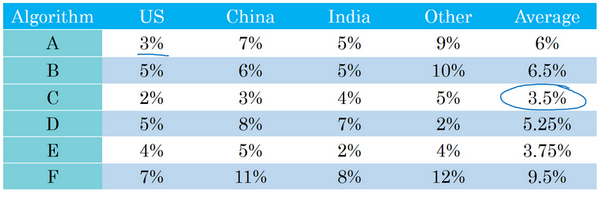
- 可以看到,C分类器的平均错误率最低,可以选用这个算法
满足指标和优化指标
- 所有考虑的因素组合成一个单实数指标不太容易,可设置满足指标和优化指标
- 例子:猫分类器
- 同时考虑准备率和运行时间
- 方案1:线性组合指标,\(cost=accuracy-0.5\times run_time\)。缺点:太刻意
- 方案2:能最大限度提高准确度,但必须满足运行时间要求。
- 优化指标:准确度,想尽可能的准确
- 满足指标:必须足够好,但是在达到足够好之后,不在乎到底有多好。比如100ms的运行时间是满足指标,那么80ms和95ms都是可以的。
- 所以这里,可以选择B分类器,在达到满足指标的情况下,优化指标是最好的

- N个指标:
- 1:设为优化指标,尽可能的优化
- N-1:设为满足指标,需要达到指定阈值
- 例子:语音设备的唤醒
- 准确性:说出唤醒词,多大概率唤醒设备。最大化准确性,【设为优化指标。】
- 假阳性:没说唤醒词,多大概率唤醒设备。满足24小时内最多1词假阳性唤醒,是可以接受的。【设为满足指标。】
训练集、开发集、测试集的分布
- 机器学习工作流程:
- 尝试很多思路
- 训练集训练不同的模型
- 用开发集评估不同的思路,从中选择一个,然后不断迭代改善开发集的性能,直到拿到一个满意的版本
- 用测试集取评估
- 例子:猫分类器,基于不同地区的数据如何划分数据?
- 前4个作为开发集,后4个作为测试集
- 结果:糟糕的,因为开发集和测试集来自不同的分布
- 开发集:设定瞄准的靶心(目标)
- 测试集:因为分布不同,其靶心不是上面已知尝试优化的靶心
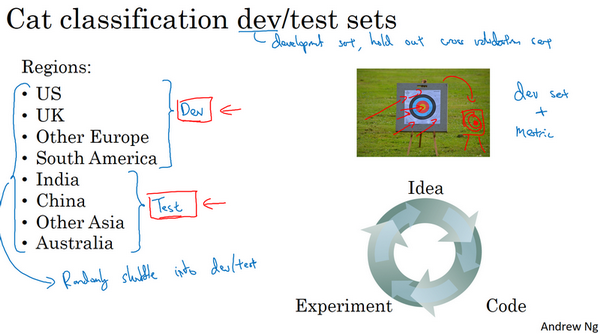
- 如何避免数据分布不同?
- 将所有数据随机洗牌,放入开发集和测试集。此时开发集和测试集都有来自不同地区的数据,并且来自同一分布(所有数据的混合)。
- 真实案例:
- 问题:输入x为贷款申请,输出y是否有还贷能力
- 开发集来自中等收入。基于此输出进行了优化。
- 在低收入的数据上进行一下测试。
开发集和测试集的大小
- 开发集和测试集必须来自同一分布,规模应该多大?
- 大小:
- 机器学习:
- 70/30比例分成训练集和测试集
- 60/20/20比例分成训练集、开发集和测试集
- 在数据集小的时候划分是合理的
- 深度学习:
- 数据集大得多
- 方案1:98/1/1的比例分成训练集、开发集和测试集。如果样本量是1000000,那么1%是10000,足够作为开发集和测试集。
-
方案2:小于20%或者30%的比例作为开发集和测试集
- 测试集大小:
- 如果需要足够的精确指标,可能需要百万数据作为测试集
- 如果不需置信度很高的评估,不需要那么大的测试集
-
测试集数量小于30%
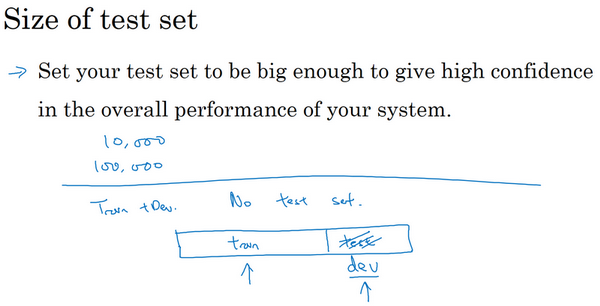
- 不建议省略测试集
- 单独的测试集:不带偏差的数据可以测量系统的性能
- 机器学习:
什么时候该改变开发集/测试集合评估指标?
- 如果项目进行途中,意识到出现了问题,可以采取一些措施进行模型修正,比如修开发集/测试集,或者评估指标
- 修改评估指标例子:
- 分类器:猫图像识别
- 算法A:错误率3%,算法B:错误率5%
- 部署:A某种原因把色情图像分类成猫,所以实际会也会给用户推荐一些色情图片。B错误率高,但是不会错误识别色情图片以作推荐。
- 评价指标+开发集 =》A更好
- 你+你的用户 =》B更好
- 原因:评价指标,也就是错误率的定义存在问题
- 错误率:对所有的图像,比较预测和真实值,算平均。但是这个是认为色情图片和非色情图片都是一样的。
- 做法:引入加权,再求和平均,对于色情图片,其权重可以设置很高,这样如果是色情图片,那么对应的会使得错误率加大。

- 如果评估指标无法正确评估好算法的排名,需要花时间定义一个新的评估指标
- 定义一个更好的指标,算是正交化的例子

- 修改开发测试集:
- 分类器:猫图像识别
- 算法A:错误率3%,算法B:错误率5%
- 部署:算法B效果更好
- 原因:手机用户的图片不是高质量的,而在训练和开发评估时,使用的都是高质量的数据。
- 做法:改变开发测试集,让数据更能反映实际需要处理的数据

为什么跟人的表现进行对比?
- 机器学习系统 vs 人类:
- 深度学习进步,机器学习算法效果更好了
- 机器做人的事情,工作流程效率更高
- 性能比较:
- 当研究一个问题一段时间,机器系统进展很快
- 当表现比人更好时,进展和精确度提升变慢
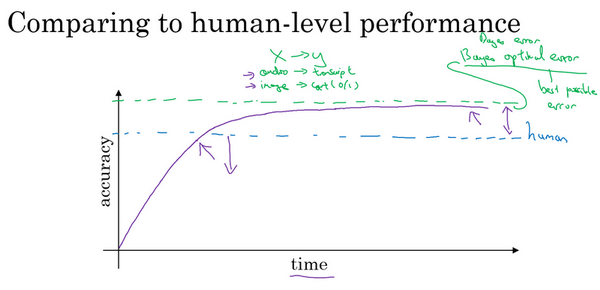
- 贝叶斯最优错误率:
- Bayes optimal error
- 模型越来越大,数据越来越多,但是性能无法超过某个理论上限
- 无论怎样,永远不会超过最优贝叶斯错误率(上面的紫线)
- 为什么超过人后进展变慢?
- 人类水平在很多任务上离最优错误率已经不远,当超越人后没有太多改善空间
- 当比人差时,有很多工具可以来提高性能,但是一旦超越人,这些工具没那么好用

可避免偏差

- 左边:
- 模型的训练集错误率8%,开发集错误率10%,人的错误率是1%,认为这个是接近于贝叶斯最优错误率的。
- 那么此时训练集拟合的并不好,因为训练误差还很大。
- 重点:减少偏差
- 右边:
- 模型的训练集错误率8%,开发集错误率10%,人的错误率是7.5%,认为这个是接近于贝叶斯最优错误率的。
- 那么此时训练集拟合的还可以,因为训练误差很接近于贝叶斯最优误差,虽然整体的错误率仍然是8%。所以模型表现只比人差一点点。
- 方差:训练集和开发集之间的差距,这里是2%,具有更多的改进空间。比如使用正则化或者搜集更多的训练数据,可以将方差减小。
- 可避免偏差:贝叶斯错误率的估计和训练错误率之间的差值。这里是0.5%
- 重点:减少方差
理解人的表现
- 什么是人类水平?
- 在医疗图片诊断中,不同的人会有不同的错误率,应该选择哪一种作为贝叶斯错误率的估计?

- 贝叶斯最优错误率应该是低于0.5%的,所以可以使用0.5%作为估计
- 实际部署中,也可使用其他的值,比如普通医生的1%作为贝叶斯错误率估计
- 在医疗图片诊断中,不同的人会有不同的错误率,应该选择哪一种作为贝叶斯错误率的估计?
- 例子:
- 医疗图像识别

- 左边:训练集错误率5%,开发集错误6%,贝叶斯错误率0.5%-1%。可避免偏差:4%-4.5%,方差:1%。偏差一定比方差大,所以重点是减少偏差(比如训练更大的网络)
- 中间:训练集错误率1%,开发集错误5%,贝叶斯错误率0.5%-1%。可避免偏差:4%-4.5%,方差:4%。方差一定比偏差大,所以重点是减少方差(比如正则化或者获取更大的数据集)
- 右边:
- 训练集错误率0.7%,开发集错误0.8%,贝叶斯错误率0.5%。可避免偏差:0.2%,方差:0.1%。可避免偏差更严重。
- 训练集错误率0.7%,开发集错误0.8%,贝叶斯错误率0.7%。可避免偏差:0%,方差:0.1%。方差更严重。
- 所以当你的模型效果越接近于人类时,取的进展会越来越难。
- 医疗图像识别
- 偏差和方差:
- 以前:比较训练错误率和0%,用这个估计偏差
- 现在:比较训练错误率和贝叶斯错误率,估计可避免偏差。

- 对人类水平有大概的估计可以让你做出对贝叶斯错误率的估计,更快的决定是否应该专注于减少算法的偏差或者方差。
超越人的表现
- 机器学习系统在接近或者超越人类水平的时候会变得越来越慢,为什么?
- 例子:
- 医疗图像识别
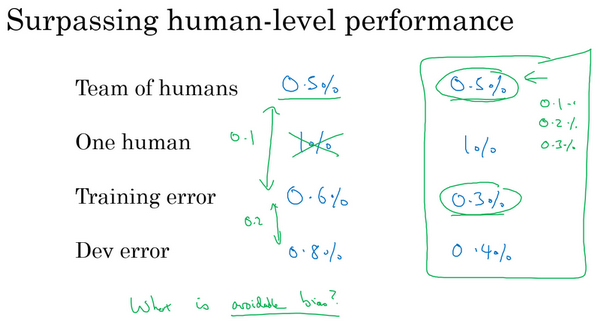
- 左边:训练集错误率0.6%,开发集错误0.8%。团队错误率0.5%,个人错误率1%。这里以0.5%作为贝叶斯错误率估计,那么可避免偏差是0.1%,方差是0.2%。所以减少方差空间更大。
- 右边:训练集错误率0.3%,开发集错误0.4%。团队错误率0.5%,个人错误率1%。
- 模型错误率比团队和个人的更低?模型错了?贝叶斯错误率其实是更低的(比如0.1%,0.2%)?
- 此时很难判断算法的优化方向到底是方差还是偏差了
- 没有明确的选项或者前进的方向
- 医疗图像识别
- 人:在自然感知任务中表现非常好
- 计算机:从结构化的数据中学习更具优势
- 广告点击
- 商品推荐等

改善模型表现
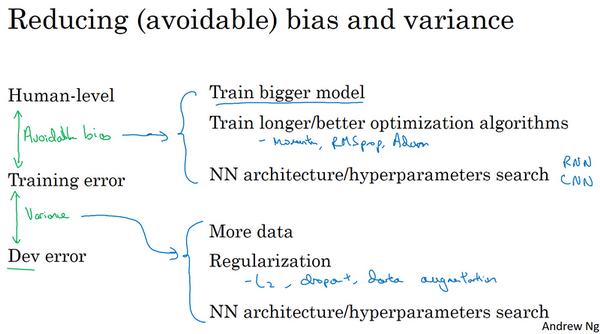
- 监督学习的两个本质假设:
- 对训练集拟合的很好,能做到可避免偏差很低。
- 推广到开发集和测试集也很好,就是方差不太大
- 如何提高模型效果:
- 降低可避免偏差:
- 更大的模型
- 训练更久
- 更好的优化算法
- 更好的网络、超参数:激活函数、层数、隐藏单元数等
- 。。。
- 降低方差:
- 收集更多数据
- 正则化:L2,dropout,数据增强
- 。。。
- 降低可避免偏差:
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/structuring-machine-learning-projects-3-strategy1.html
Previous:
【2-3】深度学习的超参数优化、batch归一化
Next:
【3-2】机器学习(ML)策略(2)
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me