目录
- 目录
- 进行误差分析
- 清除标注错误的数据
- 快速搭建第一个系统进行迭代
- 使用不同分布的数据进行训练和测试
- 数据分布不匹配时的偏差和方差分析
- 处理数据不匹配问题
- 迁移学习
- 多任务学习
- 端到端的深度学习
- 是否使用端到端的深度学习?
- 参考
进行误差分析
- 误差分析:人工检查一下你的算法犯的错误,可以了解接下来应该做什么
- 例子:猫识别
- 准确率90%,错误率10%。注意到有的狗的图片被错误识别为猫,是否应该花时间处理狗识别错误这个问题?
- 做法:收集100个开发集样本,手动检查,数出总共有多少个样本是狗。
- 假如5%是狗:如果花时间解决,错误率从10%下降到9.5%,错误率相对下降5%。此时改进并不是很大。
- 假如50%是狗:如果花时间解决,错误率从10%可能下降到5%。此时可以花时间解决这个。

- 对于算法改进的性能上限是多少,最好能到哪里,完全解决狗的问题有多少帮助。
- 同时评估多个想法:
- 上面是说错误来自于把狗识别为猫
- 假如同时存在其他的可能性呢?比如猫科动物的错误识别,图像模糊等
- 做法:通过错误分析同时评估这些个想法。
- 具体:建立一个表格,对于想要看的数据集,一个个的看,看是否存在潜在想法的,有就对应栏目+1,最后统计出算法在这个数据集上,每一个想法的错误的百分比。基于此,就知道哪个想法所占的错误比例最大,也是最有可能在进行改进后提升模型效果的。
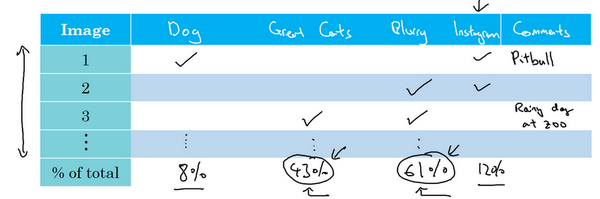
- 中途添加新的想评估的想法:
- 在人工看每个数据集的时候,有时候会出现新的错误原因,可以再列举出来,和其他想法一起查看
- 错误分析:通过快速统计,统计出不同错误标记类型占总数的百分比,可以帮助发现哪些问题需要优先解决(高低的优先级),或者为构思新优化方向提供灵感
清除标注错误的数据
- 如果有的数据标签是错的,是否值得花时间去修正
- 分情况(训练集):
- 随机错误:不用花时间修复,因为深度学习算法对于训练集中的随机错误是很健壮的,如果这些错误标注的样本离随机样本不太远
- 系统错误:学习算法不健壮
- 比如一直把白色的狗标记为猫,这就会带来学习的问题
- 开发集、测试集:
- 使用错误分析,看开发集和测试集中的例子
- 如果错误标记比例大,严重影响开发集上评估算法的能力,需要花时间去修复
-
如果不影响评估,可不花时间去处理
- 例子:
- 错误率10%,6%来自于标记出错,那么10%*6%=0.6%的错误来自于标记,其他原因占比9.4%,应该看其他的什么原因主导错误
- 错误率2%,0.6%来自于标记出错,其他原因1.4%。但是此时0.6%/2%=30%是由于标记出错的,此时去处理这些错误标签是值得的。

- 如何清除:
- 同时修正开发集和测试集:保证来自于统一分布
- 同时检验算法判断正确和错误的样本
- 训练集数据与开发集或者测试集稍微不同,也没关系,模型是比较健壮的

快速搭建第一个系统进行迭代
- 快速建立系统:
- 设立开发集、测试集和评估指标:决定了目标所在,即使目标定错了,也是可以后面更改的
- 训练集进行训练:看效果,理解算法的表现
- 意义:
- 快速而粗糙的实现
- 确定偏差方差范围
- 错误分析:确定优化方向

使用不同分布的数据进行训练和测试
- 例子:
- 任务:猫识别任务
- 数据:20000网络抓取(高质量),10000用户提供(低质量)
- 核心:最后app是处理用户新提供的数据的,所以这里和最后实际的而应用场景相同的数据分布的就只有10000个样本,其余200000网络的样本不是相同分布,如何做?
- 问题:如何进行数据的划分?
- 方案1:总共210000张,合并后随机打乱,分成训练、开发和测试集:205000,2500,2500。
- 不好:2500个样本,平均有多少个用户上传的图片:2500-2500*(200k/210k)=119。这个样本数量的开发集中含有的靶标数据(用户上传的图片)太小了,所以实际是在对不关心的数据分布做优化。
- 方案2:训练集:200000+5000用户,开发和测试各2500,此时开发集包含的数据全部来自于用户,而这正是需要真正关心的图片的分布。
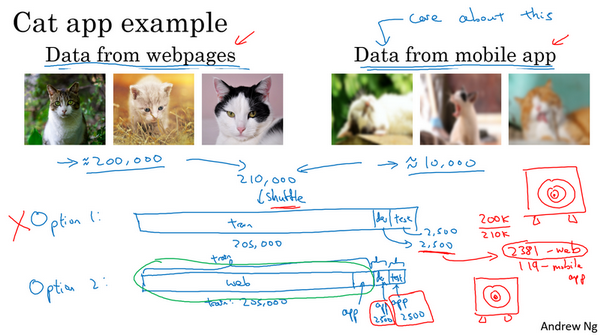
- 虽然此时训练集和开发集、测试集分布不一样,但是事实证明这样的划分,在长期能带来更好的性能
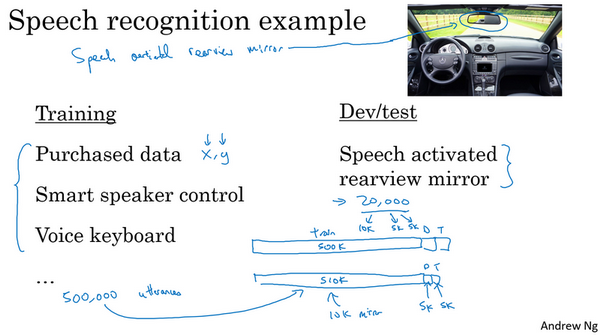
- 例子:
- 任务:语音后视镜激活
- 训练集:可以来自不同的来源,购买的,其他设备的
- 开发和测试集:必须是语音激活的数据集,这个是和任务最相关的,也是设定的目标
数据分布不匹配时的偏差和方差分析
- 数据同分布:
- 贝叶斯错误率:0%
- 训练误差:1%
- 开发误差:10%
- 结论:这里方差很大,模型泛化能力不好。能很好的处理训练集,但是在开发集上效果很差。
- 数据不同分布:
- 贝叶斯错误率:0%
- 训练误差:1%
- 开发误差:10%
- 结论:不能得出方差很大的结论。
- 原因:可能训练集图片更容易识别,所以训练集效果好,开发集差
- 核心:两件事情变了
- 算法只见过训练数据,没见过开发数据
- 开发集数据来自于不同的分布
- 所以难以判断增加的9%的误差,是因为没见过开发数据(泛化能力),还是因为开发集数据分布本身就不一样。
- 哪个因素影响更大?
- 解决:引入训练-开发集
- 训练-开发集:
- 随机打散训练集,然后拿出一部分训练集作为训练-开发集
- 此时训练集、训练-开发集来自同一分布
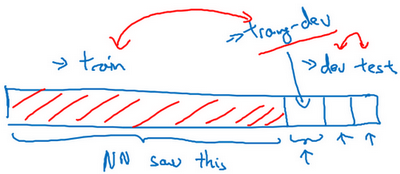
- 例子:
- 左边:训练误差1%,训练-开发误差9%,开发误差10%【存在方差问题,因为训练-开发错误率是和训练同一分布得到的,泛化能力本身就不好】
- 右边:训练误差1%,训练-开发误差1.5%,开发误差10%【数据不匹配问题,因为在同分布的训练-开发上错误率很小,但是在不同分布的开发上错误率很高】
-
数据不匹配问题:算法擅长处理和你关心的数据不同的分布

- 左边:存在可避免偏差,算法比人的水平差很多
-
右边:可避免偏差+数据不匹配问题

- 原则:查看人类平均错误率、训练集错误率、训练-开发集错误率,以确定可避免偏差、方差、数据不匹配问题大小

- 开发测试错误率比人的更低?
- 人4%,开发测试6%,为什么?
- 如果开发测试集分布比应用实际处理的数据要容易得多,那么这些错误率可能会降低。
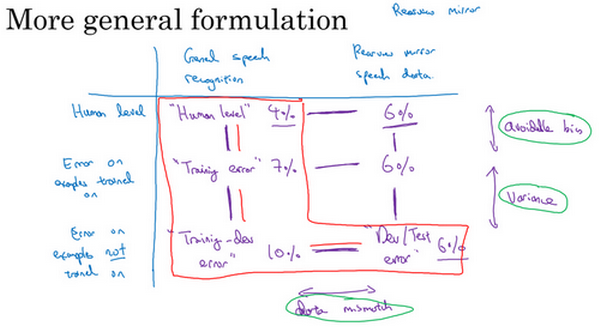
- 偏差方差分析:
- 普适的分析
- 建立表格:水平轴是不同的数据,纵轴是标记数据的方式或者算法(比如这里是语音数据的不同来源)。然后看不同的数据在不同的数据集上的错误率大小。
- 可避免偏差:human vs train
- 方差:train vs train-dev
- 数据不匹配:train-dev vs dev/Test
- 系统解决数据不匹配的方法不存在,但是可以做一些尝试
处理数据不匹配问题
- 如何处理数据不匹配?
- 错误分析:
- 了解训练集和开发测试集的具体差异
- 为了避免对测试集过拟合,要做错误分析,应该人工去看开发集而不是测试集
- 收集更多的数据,使得训练数据和开发集数据越来越像
- 如何做到?
- 策略:人工合成数据
- 比如知道训练集其实是更干净的数据,可以人工合成具有噪声的数据作为训练集
- 有名的语音例子:The quick brown fox jumps over the lazy dog。【含有a-z的所有字母】
- 人工合成风险:
- 数据对于噪声的过拟合
-
如果语音的数据很多,但是真实的噪声数据很少,在组合之后,其实噪声数据集还是小,只模拟了全部数据空间的一小部分,容易使得模型过拟合。

- 汽车识别例子:
- 后两个汽车图片是合成的,如果汽车是有限的,也容易陷入过拟合


迁移学习
- 深度学习概念:神经网络从一个任务中析得知识,并将这些知识应用到另一个独立的任务中
- 例子:
- 动物图像识别 =》 X射线图像识别
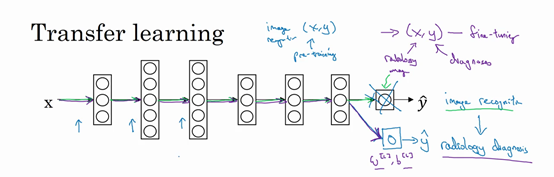
- 如何做?
-
把神经网络最后的输出层拿走,以及进入最后一层的权重删掉,然后为最后一层重新赋予随机权重,让它在X射线图像数据上训练
- 经验:
- 如果有一个小数据集,就只训练输出层前的最后一层,或者最后一两层
-
如果有足够多的数据,可以重新训练网络中的所有参数
- 预训练:pre-training,如果重新训练神经网络的所有参数,那么这个在图像识别数据的初期训练阶段,称为预训练。用图像识别数据去预先初始化神经网络的权重。
- 微调:fine tuning,如果以后更新所有权重,然后在X射线数据上训练,这个过程就是微调。
- 动物图像识别 =》 X射线图像识别
- 为什么可以迁移?
- 低层次特征能够学习到:边缘检测、曲线检测、阳性对象检测
- 可以帮助学习更快或者只需要更少的数据
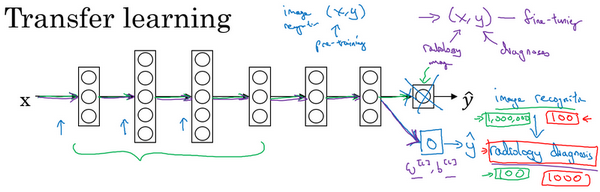
- 应用场景:
- 在迁移来源问题中有很多数据,但是迁移目标问题没有那么多数据
- 比如图像识别有1000000样本,X射线识别只有100个样本
- 语音识别有10000小时样本,唤醒词检测只有1小时数据
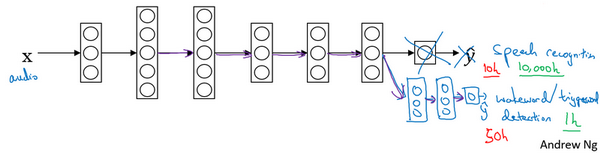
- 注意:反过来可能不起作用,即数据量少的问题迁移到数据量很多的问题。样本不能cover到,有用的样本训练时没有用上。
- 什么时候迁移学习是有效的?
- 两个学习任务的输入是一样的
- 任务A的数据比任务B多得多
- 任务A的低层次特征,可以帮助任务B的学习
多任务学习
- 迁移学习:串行的,从任务A中学习知识然后迁移到任务B上
- 多任务学习:试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮助到其他所有任务
- 例子:
- 研发无人驾驶车辆
- 同时检测:行人、车辆、停车标志、交通灯
-
这本可以是四个不同的检测任务

- 网络结构:预测的输出就是一个多维向量,比如这里是4x1的向量
-
损失函数:单个样本时,是对这四个分量的求和
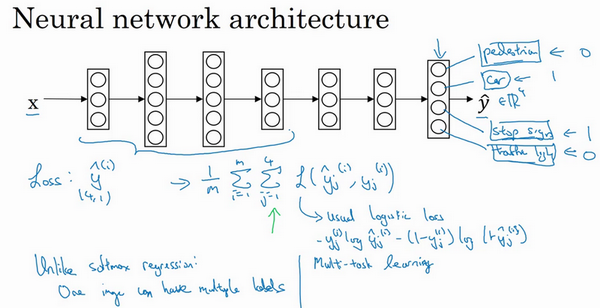
- 做法:建立单个神经网络,观察每张图,解决四个问题,告诉每个图里有没有这四个物体
- 早期特征,在识别四个物体中都是用到的,所以一个神经网络比单独训练四个完全独立的性能要好
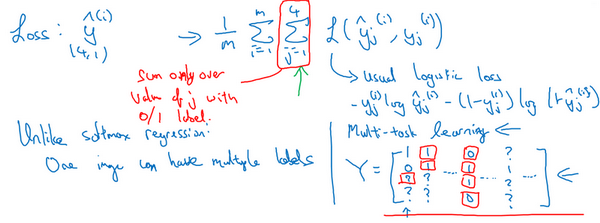
- 多任务学习的确实数据?
- 对于训练数据,不一定每个任务都有对应的标签
- 此时这些数据也是可以进行多任务学习的
- 在损失求和时,对于那些确实的(问号的)项,忽略掉即可
- 什么时候多任务学习有效?
- 这组任务可以共用低层次特征。比如上面的无人驾驶,物体的识别具有一些相似的低级特征
- 每个任务的数量很接近,或者说其他任务加起来的数据量比单个任务大得多。这样,学习的时候其实是无形中增大了数据集。
- 可以训练一个足够大的网络。
- 多任务学习性能低于单个任务的情况:训练的神经网络不够大。当足够大时,多任务学习肯定不会降低性能。
- 迁移学习 vs 多任务学习:
- 迁移学习:使用频率更高
- 多任务学习:使用频率较低。难以找到那么多相似数据量对等的任务可以用单一神经网络训练。例外:物体检测任务。
端到端的深度学习
- 传统机器学习 vs 端到端:
- 传统:需要多个阶段
- 端到端:忽略所有不同的阶段,用单个神经网络代替它
- 例子:语音识别
- 传统:语音,提取特征,音位,单词,文本
- 端到端:直接从语音到文本
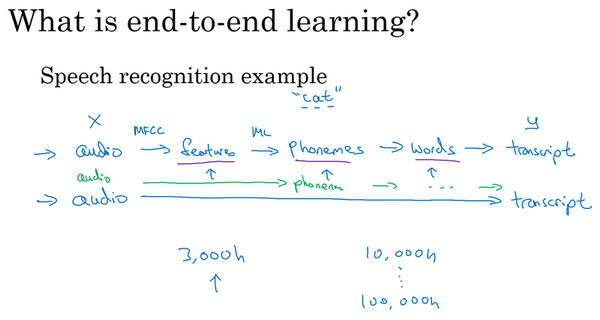
- 挑战:
- 需要大的数据量
- 如果语音识别,数据量不大,比如2000小时,可能流水线的方式更好
- 如果语音识别,数据量很大,比如100000小时,那么端到端的效果通常更好
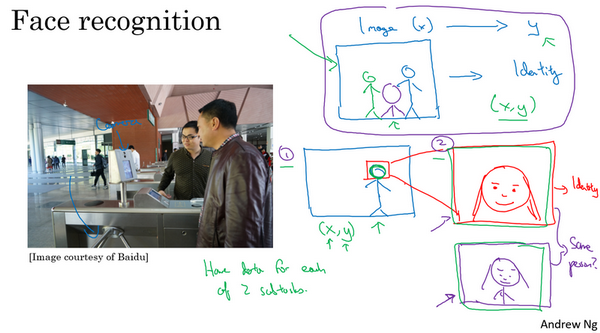
- 例子:
- 百度的门禁系统
- 分步:定位人脸+判断人脸身份,每一步的数据量都很多,问题也很明确简单。所以现在采用这种分步的方法效果更好。
- 端到端:拍照到身份,数据量太少
是否使用端到端的深度学习?
- 优点:
- 只看数据。数据很多时,可以捕捉任何的统计信息,不会被迫引入人类的偏见。
- 所需手动设计的组件更少。简化设计流程。
- 缺点:
- 需要大量的数据
- 排除了可能有用的手工设计组件
- 核心问题:
- 是否有足够的数据能够学到从x映射到y的足够复杂的函数?
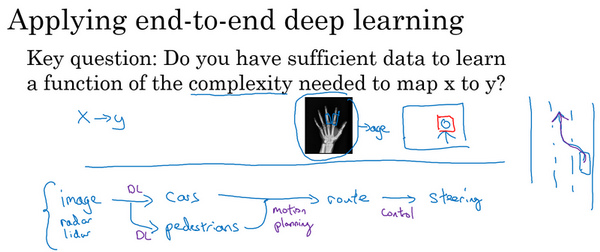
- 是否有足够的数据能够学到从x映射到y的足够复杂的函数?
- 例子:
- 无人驾驶
- 拍照,检测物体,规划路线等多个步骤
- 前面的检测也许深度学习可以做的很好,但是后面的运动路径不是深度学习能完成的。
- 多步的方法比端到端更好
- 纯粹的端到端的深度学习,前景不如更复杂的多步方法,目前收集的数据,训练神经网络的能力是有限的。
参考
If you link this blog, please refer to this page, thanks!
Post link:https://tsinghua-gongjing.github.io/posts/structuring-machine-learning-projects-3-strategy2.html
Previous:
【3-1】机器学习(ML)策略(1)
Next:
损失函数
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me