[CS229] 04: Linear Regression with Multiple Variables
2018-10-25
04: Linear Regression with Multiple Variables
- 多特征使得fitting函数变得更复杂,多元线性回归。
- 多元线性回归的损失函数:
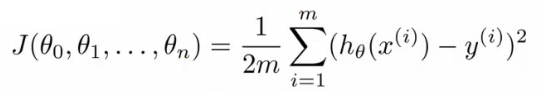
- 多变量的梯度递减:
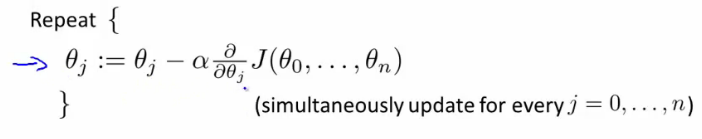
- 规则1:feature scaling。对于不同的feature范围,通过特征缩减到可比较的范围,通常[-1, 1]之间。
- 归一化:1)除以各自特征最大值;2)mean normalization(如下):
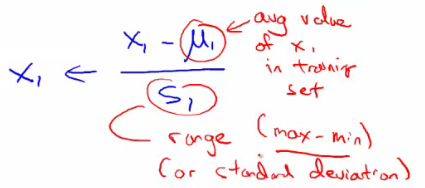
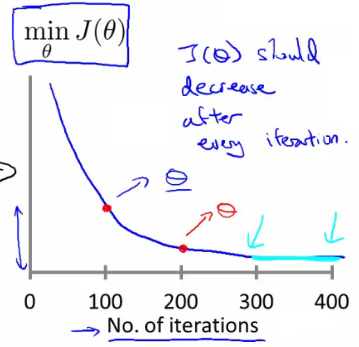
- 规则2:learning rate。选取合适的学习速率,太小则收敛太慢,太大则损失函数不一定会随着迭代次数减小(甚至不收敛)。
- 损失函数曲线:直观判断训练多久时模型会达到收敛
- 特征和多项式回归:对于非线性问题,也可以尝试用多项式的线性回归,基于已有feature构建额外的特征,比如房间size的三次方或者开根号等,但是要注意与模型是否符合。比如size的三次方作为一个特征,随着size增大到一定值后,其模型输出值是减小的,这显然不符合size越大房价越高。
- Normal equation:根据损失函数,求解最小损失岁对应的theta向量的,类似于求导,但是这里采用的是矩阵运算的方式。
- 求解方程式如下:
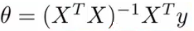
- 这里就直接根据训练集和label值矩阵求解出最小损失对对应的各个参数(权重)。
- 求解方程式如下:
- 什么时候用梯度递减,什么时候用normal equation去求解最小损失函数处对应的theta向量?

Read full-text »
[CS229] 03: linear alegbra
2018-10-23
03: Linear Algebra - review
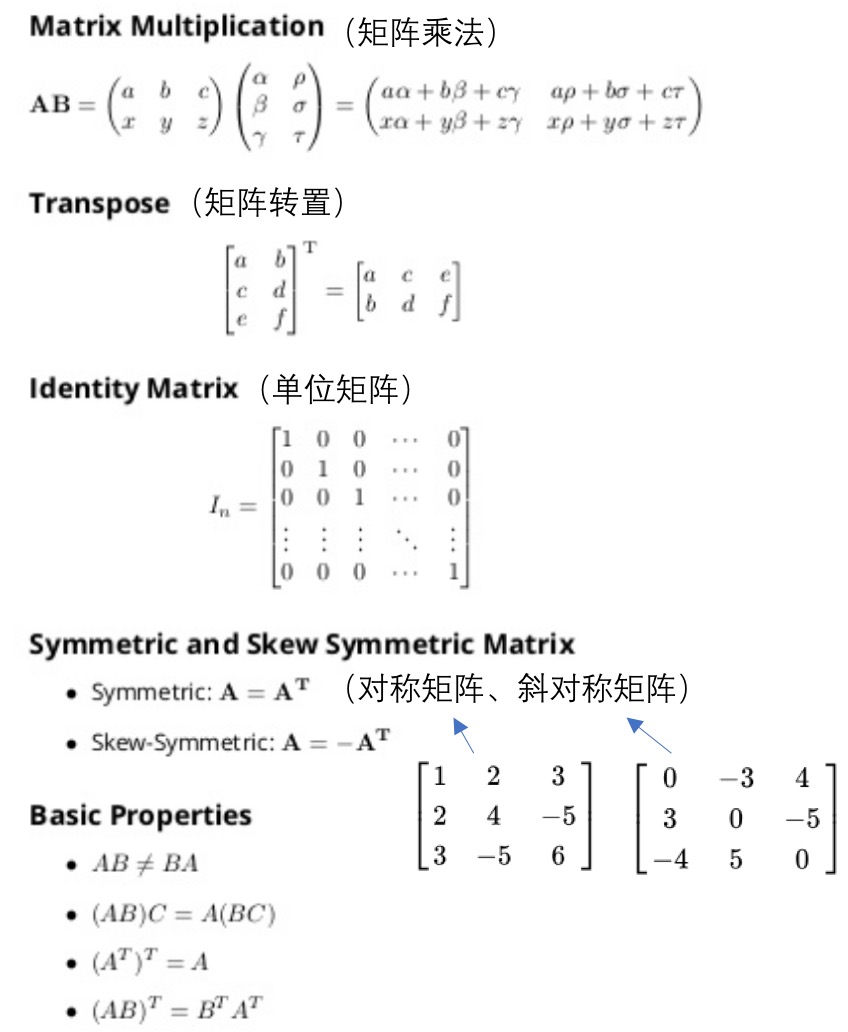
- 概念:
- matrix: rectangular array of numbers: rows x columns
- element: i -> ith row, j -> jth column
- vector: a nx1 matrix
- 操作:
- 加和: 需要相同的维,才能元素级别的相加减。
- 标量乘积
- 混合运算
Read full-text »
[CS229] 01 and 02: Introduction, Regression Analysis and Gradient Descent
2018-10-21
01 and 02: Introduction, Regression Analysis and Gradient Descent
- definition: a computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E . — Tom Mitchell (1998)
- supervised learning:
- supervised learning: “right answers” given
- regression: predict continuous valued output (e.g., house price)
- classification: predict discrete valued output (e.g., cancer type)
- unsupervised learning:
- unlabelled data, using various clustering methods to structure it
- examples: google news, gene expressions, organise computer clusters, social network analysis, astronomical data analysis
- cocktail party problem: overlapped voice, how to separate?
- linear regression one variable (univariate):
- m : number of training examples
- X’s : input variable / features
- Y’s : output variable / target variable
- cost function: squared error function: \(J(\theta) = \frac{1}{2} \sum_i \left( h_\theta(x^{(i)}) - y^{(i)} \right)^2 = \frac{1}{2} \sum_i \left( \theta^\top x^{(i)} - y^{(i)} \right)^2\)
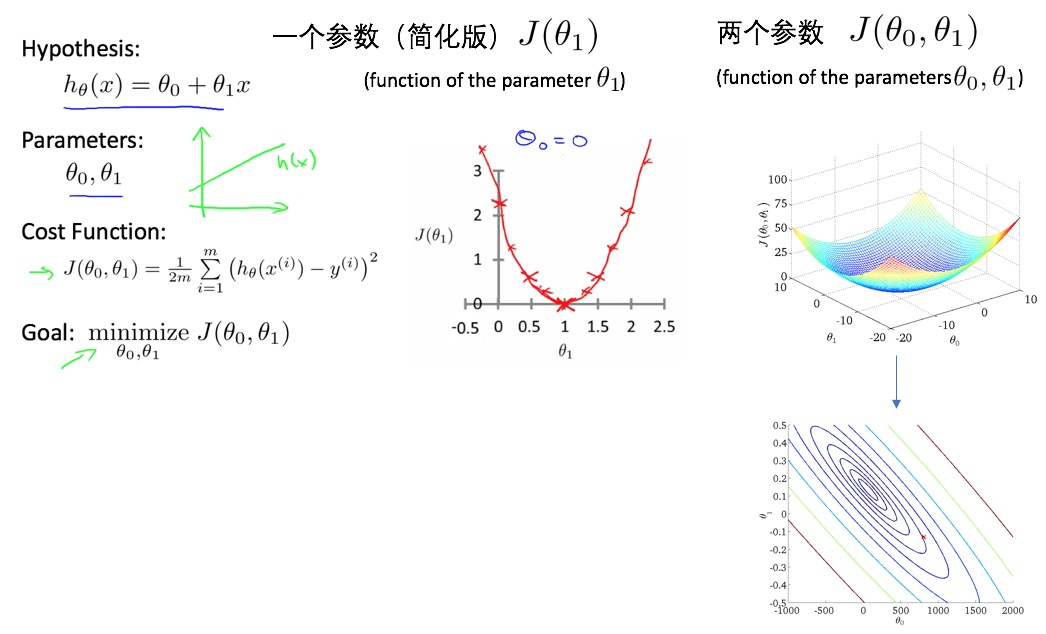
- parameter estimation: gradient decent algorithm

Read full-text »
[CS229] resource
2018-10-16
课程信息
机器学习入门,Coursera的课程内容和CS229的内容相似,但是后者的难度更大,有更多对于公式的推导,可以先看Coursera再补充看CS229的。
- Coursera video: https://www.coursera.org/learn/machine-learning
- Coursera video slides and quiz on Github (fork from atinesh-s): https://github.com/Tsinghua-gongjing/Coursera-Machine-Learning-Stanford
-
Webpage notes: http://www.holehouse.org/mlclass/
- Stanford course material: http://cs229.stanford.edu/syllabus.html
-
Stanford video: https://see.stanford.edu/course/cs229
- CS229 cheatsheet:English & Chinese & @Stanford
课程笔记
- 注意:
很多介绍的内容都很详细,这里只记录一些自己觉得容易忘记或者难以理解的点。
Read full-text »
sklearn: 管道与特征联合
2018-10-15
目录
- 目录
- 1. 管道pipeline
- 2. 管道用法:构造
- 3. 管道用法:访问
- 4. 管道用法:访问和设置评估器的参数
- 5. 缓存转换器
- 6. 目标转换:对预测值y进行转换
- 7. 特征联合
- 8. 异构数据的列转换器
- 参考
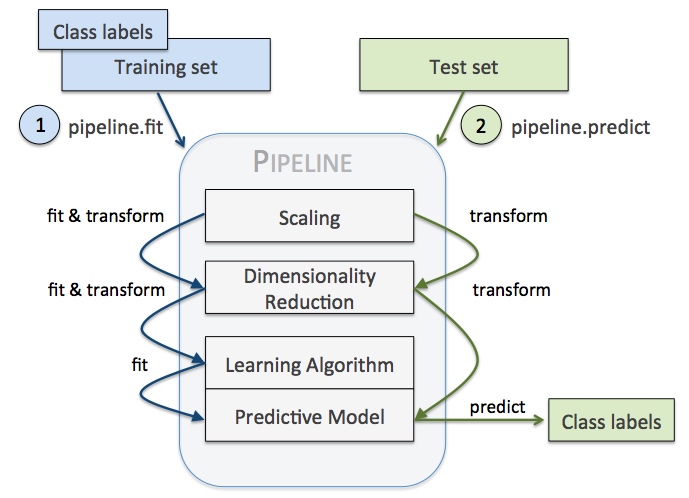
1. 管道pipeline
用途:把多个评估器链接成一个
目的:
- 便捷和封装:只需对数据调用
fit和predict一次,完成所有评估器的适配 - 联合的参数选择:在
grid search时可以一次评估管道中所有评估器的参数 - 安全性:转换与预测都是相同样本,防止测试数据泄露到验证数据中
# 不使用管道
vect = CountVectorizer()
tfidf = TfidfTransformer()
clf = SGDClassifier()
vX = vect.fit_transform(Xtrain)
tfidfX = tfidf.fit_transform(vX)
predicted = clf.fit_predict(tfidfX)
# Now evaluate all steps on test set
vX = vect.fit_transform(Xtest)
tfidfX = tfidf.fit_transform(vX)
predicted = clf.fit_predict(tfidfX)
# 使用管道
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', SGDClassifier()),
])
predicted = pipeline.fit(Xtrain).predict(Xtrain)
# Now evaluate all steps on test set
predicted = pipeline.predict(Xtest)
2. 管道用法:构造
两种构造管道的方式:
- 通过键值对直接构造,把不同的评估器放在列表中
- 通过功能函数
make_pipeline构造
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.svm import SVC
>>> from sklearn.decomposition import PCA
# 键值对直接构造
>>> estimators = [('reduce_dim', PCA()), ('clf', SVC())]
>>> pipe = Pipeline(estimators)
# 功能函数`make_pipeline`构造
>>> make_pipeline(PCA(), SVC())
>>> pipe
Pipeline(memory=None,
steps=[('reduce_dim', PCA(copy=True,...)),
('clf', SVC(C=1.0,...))], verbose=False)
3. 管道用法:访问
不同的访问构建的评估器的方法(比如查看不同评估器的先后顺序,某个评估器的具体参数值等):
- 构造的各个评估器作为列表保存在属性
steps中,可索引或名称访问 - 直接对管道进行索引或切片访问
# steps属性索引
>>> pipe.steps[0]
('reduce_dim', PCA(copy=True, iterated_power='auto', n_components=None,
random_state=None, svd_solver='auto', tol=0.0,
whiten=False))
# 管道直接索引
>>> pipe[0]
PCA(copy=True, iterated_power='auto', n_components=None, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
# 管道名称索引
>>> pipe['reduce_dim']
PCA(copy=True, ...)
# 管道切片索引,类似于列表
>>> pipe[:1]
Pipeline(memory=None, steps=[('reduce_dim', PCA(copy=True, ...))],...)
>>> pipe[-1:]
Pipeline(memory=None, steps=[('clf', SVC(C=1.0, ...))],...)
4. 管道用法:访问和设置评估器的参数
参数访问:评估器+两个下划线+参数名称 <estimater>__<parameter>
# 设置评估器clf的参数C
>>> pipe.set_params(clf__C=10)
Pipeline(memory=None,
steps=[('reduce_dim', PCA(copy=True, iterated_power='auto',...)),
('clf', SVC(C=10, cache_size=200, class_weight=None,...))],
verbose=False)
# 网格搜索时同时指定不同评估器的参数
>>> from sklearn.model_selection import GridSearchCV
>>> param_grid = dict(reduce_dim__n_components=[2, 5, 10],
... clf__C=[0.1, 10, 100])
>>> grid_search = GridSearchCV(pipe, param_grid=param_grid)
5. 缓存转换器
指定memory参数,可以在fit后缓存每个转换器,如果后面参数和数据相同,可以从缓存调用:
>>> from tempfile import mkdtemp
>>> from shutil import rmtree
>>> from sklearn.decomposition import PCA
>>> from sklearn.svm import SVC
>>> from sklearn.pipeline import Pipeline
>>> estimators = [('reduce_dim', PCA()), ('clf', SVC())]
>>> cachedir = mkdtemp()
# 指定缓存目录
>>> pipe = Pipeline(estimators, memory=cachedir)
>>> pipe
Pipeline(...,
steps=[('reduce_dim', PCA(copy=True,...)),
('clf', SVC(C=1.0,...))], verbose=False)
>>> # Clear the cache directory when you don't need it anymore
>>> rmtree(cachedir)
6. 目标转换:对预测值y进行转换
TransformedTargetRegressor:在拟合回归模型之前对目标y进行转换
>>> import numpy as np
>>> from sklearn.datasets import load_boston
>>> from sklearn.compose import TransformedTargetRegressor
>>> from sklearn.preprocessing import QuantileTransformer
>>> from sklearn.linear_model import LinearRegression
>>> from sklearn.model_selection import train_test_split
>>> boston = load_boston()
>>> X = boston.data
>>> y = boston.target
>>> transformer = QuantileTransformer(output_distribution='normal')
>>> regressor = LinearRegression()
>>> regr = TransformedTargetRegressor(regressor=regressor,
... transformer=transformer)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 对目标y进行对数转换作为预测值
>>> regr.fit(X_train, y_train)
TransformedTargetRegressor(...)
>>> print('R2 score: {0:.2f}'.format(regr.score(X_test, y_test)))
R2 score: 0.67
# 直接原始的预测值
>>> raw_target_regr = LinearRegression().fit(X_train, y_train)
>>> print('R2 score: {0:.2f}'.format(raw_target_regr.score(X_test, y_test)))
R2 score: 0.64
7. 特征联合
用途:合并多个转换器形成一个新的转换器
>>> from sklearn.pipeline import FeatureUnion
>>> from sklearn.decomposition import PCA
>>> from sklearn.decomposition import KernelPCA
>>> estimators = [('linear_pca', PCA()), ('kernel_pca', KernelPCA())]
>>> combined = FeatureUnion(estimators)
>>> combined
FeatureUnion(n_jobs=None,
transformer_list=[('linear_pca', PCA(copy=True,...)),
('kernel_pca', KernelPCA(alpha=1.0,...))],
transformer_weights=None, verbose=False)
8. 异构数据的列转换器
用途:
- 对数据不同的特征(列)进行不同的变换
- 不存在数据泄露
- 参数化评估
下面的例子是将数据X的
city列进行类别编码title列进行单词向量化
>>> import pandas as pd
>>> X = pd.DataFrame(
... {'city': ['London', 'London', 'Paris', 'Sallisaw'],
... 'title': ["His Last Bow", "How Watson Learned the Trick",
... "A Moveable Feast", "The Grapes of Wrath"],
... 'expert_rating': [5, 3, 4, 5],
... 'user_rating': [4, 5, 4, 3]})
>>> from sklearn.compose import ColumnTransformer
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> column_trans = ColumnTransformer(
... [('city_category', CountVectorizer(analyzer=lambda x: [x]), 'city'),
... ('title_bow', CountVectorizer(), 'title')],
... remainder='drop')
# 这里使用的remainder='drop'
# 那么其他的特征列是不输出的
# 通常情况并不想这样的
>>> column_trans.fit(X)
ColumnTransformer(n_jobs=None, remainder='drop', sparse_threshold=0.3,
transformer_weights=None,
transformers=...)
>>> column_trans.get_feature_names()
...
['city_category__London', 'city_category__Paris', 'city_category__Sallisaw',
'title_bow__bow', 'title_bow__feast', 'title_bow__grapes', 'title_bow__his',
'title_bow__how', 'title_bow__last', 'title_bow__learned', 'title_bow__moveable',
'title_bow__of', 'title_bow__the', 'title_bow__trick', 'title_bow__watson',
'title_bow__wrath']
>>> column_trans.transform(X).toarray()
...
array([[1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0],
[0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1]]...)
将ColumnTransformer的remainder=’passthrough’,可以在对某些列特征进行变换的同时,保留其他的特征列的数据(非原位的,其他的列加在转换的末尾),这通常是我们想要的:
>>> column_trans = ColumnTransformer(
... [('city_category', OneHotEncoder(dtype='int'),['city']),
... ('title_bow', CountVectorizer(), 'title')],
... remainder='passthrough')
>>> column_trans.fit_transform(X)
...
array([[1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 5, 4],
[1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 3, 5],
[0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 4, 4],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 5, 3]]...)
也可以将某个变换应用于所有非指定的列,比如下面对其他的列都进行MinMaxScaler变换:
>>> from sklearn.preprocessing import MinMaxScaler
>>> column_trans = ColumnTransformer(
... [('city_category', OneHotEncoder(), ['city']),
... ('title_bow', CountVectorizer(), 'title')],
... remainder=MinMaxScaler())
>>> column_trans.fit_transform(X)[:, -2:]
...
array([[1. , 0.5],
[0. , 1. ],
[0.5, 0.5],
[1. , 0. ]])
函数make_column_transformer也可以用于构造列转换:
>>> from sklearn.compose import make_column_transformer
>>> column_trans = make_column_transformer(
... (OneHotEncoder(), ['city']),
... (CountVectorizer(), 'title'),
... remainder=MinMaxScaler())
>>> column_trans
ColumnTransformer(n_jobs=None, remainder=MinMaxScaler(copy=True, ...),
sparse_threshold=0.3,
transformer_weights=None,
transformers=[('onehotencoder', ...)
参考
Read full-text »
SQL常见问题
2018-10-14
left join时的on和where- 相同的id根据其他列的值选择最大或者最小的
- 查询语句执行顺序
LIMIT的用法OFFSET的用法case...when...用法- 计算每个类别的数目及占比
- hive中时间与字符串的转换
with as用法- SQL书写规范
- hive使用变量
- hive保存与更新表
- 字符串切分
- 提取json array中的某个属性
left join时的on和where
- 参看SQL中的Join和Where的区别
- left join + on + where
- 在查询多张表的时候,会生成一张中间表
- on:在生成临时表的时候使用的条件,不管此条件是否为真,都会返回左表的记录(这是left join的特性所决定的)
- where:在得到临时表的结果之后,对临时表进行过滤的条件,条件不满足的记录就被过滤掉了
- 具体参见上述链接页面的例子
相同的id根据其他列的值选择最大或者最小的
# 表格
ID Uname Price BuyDate
1 张三 180 2017-12-1
2 张三 280 2017-12-7
3 李四 480 2017-12-10
4 李四 280 2017-12-11
5 王武 280 2017-12-1
6 王武 880 2017-12-11
7 王武 380 2017-12-15
# 想要
ID Uname Price BuyDate
2 张三 280 2017-12-7
3 李四 480 2017-12-10
6 王武 880 2017-12-11
# 语句
SELECT * FROM (
SELECT *,ROW_NUMBER()OVER(PARTITION BY Uname ORDER BY Price DESC ) AS rn FROM #t
) AS t WHERE t.rn=1
# 使用降序或者升序配合n=1,可以选择最小或者最大的
# 配合类似n<=5,可以选择最小或者最大的5个
查询语句执行顺序
需要遵循以下顺序:
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或者表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表中选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
LIMIT的用法
- 用法:
select * from tableName limit i,n i:查询结果的索引值,默认从n开始n:查询结果返回的数量
--检索前10行数据,显示1-10条数据
select * from Customer LIMIT 10;
--检索从第2行开始,累加10条id记录,共显示id为2....11
select * from Customer LIMIT 1,10;
--检索从第6行开始向前加10条数据,共显示id为6,7....15
select * from Customer limit 5,10;
--检索从第7行开始向前加10条记录,显示id为7,8...16
select * from Customer limit 6,10;
OFFSET的用法
- 用法:
OFFSET n n:表示跳过n个记录- 注意:当 limit和offset组合使用的时候,limit后面只能有一个参数,表示要取的的数量,offset表示要跳过的数量。
-- 跳过第一个记录
select * from article OFFSET 1
-- 跳过第一个记录,提取接下来的3个记录
-- 当LIMIT和OFFSET联合使用的时候,limit后面只能有一个参数
select * from article LIMIT 3 OFFSET 1
-- 跳过第一个记录,从index=1开始,提取接下来的3个记录
select* from article LIMIT 1,3
case...when...用法
条件表达式函数:
CASE WHEN condition THEN result
[WHEN...THEN...]
ELSE result
END
例子:
SELECT
STUDENT_NAME,
(CASE WHEN score < 60 THEN '不及格'
WHEN score >= 60 AND score < 80 THEN '及格' ---不能连续写成 60<=score<80
WHEN score >= 80 THEN '优秀'
ELSE '异常' END) AS REMARK
FROM
TABLE
计算每个类别的数目及占比
参考这里:Percentage from Total SUM after GROUP BY SQL Server:
--- count based
--- 要加和的是总entry数目
SELECT
t.device_model,
COUNT(t.device_model) AS num,
COUNT(t.device_model)/SUM(COUNT(t.device_model)) OVER () AS Percentage
--- sum based
--- 要加和是另外一列
SELECT P.PersonID, SUM(PA.Total),
SUM(PA.Total) * 100.0 / SUM(SUM(PA.Total)) OVER () AS Percentage
hive中时间与字符串的转换
参考这里,注意不用于直接sql中的函数:
--方法1: from_unixtime+ unix_timestamp
--20171205转成2017-12-05
select from_unixtime(unix_timestamp('20171205','yyyymmdd'),'yyyy-mm-dd') from dual;
--2017-12-05转成20171205
select from_unixtime(unix_timestamp('2017-12-05','yyyy-mm-dd'),'yyyymmdd') from dual;
--方法2: substr + concat
--20171205转成2017-12-05
select concat(substr('20171205',1,4),'-',substr('20171205',5,2),'-',substr('20171205',7,2)) from dual;
--2017-12-05转成20171205
select concat(substr('2017-12-05',1,4),substr('2017-12-05',6,2),substr('2017-12-05',9,2)) from dual;
with as用法
- 子查询部分(subquery factoring),是用来定义一个SQL片断,该SQL片断会被整个SQL语句所用到。这个语句算是公用表表达式(CTE)
- 尤其是多表查询,后面跟随多个join时,比如先确定需要查询哪些用户或者设备
- 支持多个子查询
--后面就可以直接把query_name1,query_name2当做表格来用了
WITH query_name1 AS (
SELECT ...
)
, query_name2 AS (
SELECT ...
FROM query_name1
...
)
SELECT ...
SQL书写规范
- 所有表名、字段名全部小写,系统保留字、内置函数名、Sql保留字大写
- 对较为复杂的sql语句加上注释
- 注释单独成行、放在语句前面,可采用单行/多行注释。(– 或 /* */ 方式)
- where子句书写时,每个条件占一行,语句令起一行时,以保留字或者连接符开始,连接符右对齐
- 多表连接时,使用表的别名来引用列
参考:SQL书写规范
hive使用变量
-- 获取1-2号的新设备
-- SET时不用添加引号,使用时添加引号
SET date1 = 20180701;
SET date2 = 20180702;
SET app = app_name;
WITH new_did AS (
SELECT
p_date,
device_id
FROM
your_table
WHERE
p_date BETWEEN '${hiveconf:pdate1}'
AND '${hiveconf:pdate2}'
AND product = '${hiveconf:app}'
AND is_today_new = 1
)
hive保存与更新表
-- 设置变量名称,放在最前面
SET pdate1 = 20200701;
SET pdate1 = 20200702;
-- DROP TABLE IF EXISTS `save_table_name`; -- 不允许有drop操作
-- CREATE TABLE IF NOT EXISTS `save_table_name ` AS -- 建表时放在这with...as前
WITH new_did AS (
-- 每日新设备
SELECT
p_date,
device_id
FROM
tA
WHERE
p_date BETWEEN '${hiveconf:pdate1}'
AND '${hiveconf:pdate2}'
)
INSERT OVERWRITE TABLE `save_table_name` -- 更新表时放在select前
SELECT
tA.p_date,
......
字符串切分
SELECT split('919.99&usd', '&')[0],split('919.99&usd', '&')[1],split('919.99&usd', '&')[2]
# 切分的结果index从0开始,不是1
_c0 _c1 _c2
919.99 usd
提取json array中的某个属性
参考这里:
-- 字段信息
[{"userId":89224,"contactName":"","contactPhone":"+","originPhone":"+"},
{"userId":89223,"contactName":"","contactPhone":"+","originPhone":""},
{"userId":89221,"contactName":"","contactPhone":"+","originPhone":"+"}]
-- sql
select user_id, get_json_object(contacts,'$[*].userId') as cons
from XXXX
-- 提取后
user_id cons
1 107521212 [8397213,85,7418687,304388953,198708241,148,111920,5285539,97773639]
Read full-text »
Python2 vs Python3
2018-10-13
目录
区别列表
| 内容 | Python2 | Python3 |
|---|---|---|
| (1) 语句:print ‘abc’ (2) from __future__ import print_function 实现python3的功能 |
函数:print(‘abc’) | |
| 编码 | 默认是asscii,经常遇到编码问题 | 默认是utf-8,不用在抬头指定:# coding=utf-8 |
| 字符串 | (1) str:字节序列 (2) unicode:文本字符串 两者没有明显的界限 |
(1) byte:字节序列(新增) (2) str:字符串 对两者做了严格区分 |
| 数据类型 | (1) long (2) int |
int:行为类似于python2中的long |
| 除法运算 | (1) 除法结果是整除 (2) 1/2结果是0(两个整数相除) (3) 使用from __future__ import division实现该特性 |
(1) 除法结果是浮点数 (2) 1/2结果是0.5(两个整数相除) |
| 输入 | (1) input()只接收数字 (2) raw_input()得到的是str类型(为了避免在读取非字符串类型的危险行为) |
input()得到str |
| 内置函数及方法 (filter,map,dict.items等) |
大部分返回列表或者元组 | 返回迭代器对象 |
| range | (1) range:返回列表 (2) xrange:返回迭代器 |
range:返回迭代器,取消xrange |
| True/False | (1) 是全局变量,可指向其他对象 (2) True对应1,False对应0 |
(1) 变为两个关键字 (2) 永远指向两个固定的对象,不允许再被重新赋值 |
| nonlocal | 没有办法在嵌套函数中将变量声明为一个非局部变量,只能在函数中声明全局变量 | 可在嵌套函数中什么非局部变量,使用nonlocal实现 |
| 类 | (1) 默认是旧式类 (2) 需要显式继承新式类(object)来创建新式类 |
(1) 完全移除旧式类 (2) 所有类都是新式类,但仍可显式继承object类 |
| 写文件 | print»SAVEN,’\t’.join() | SAVEFN.write(‘\t’.join()+’\n’) |
参考
Read full-text »
Xgboost
2018-10-12
目录
XGBoost 简介
- XGBoost:Extreme Gradient Boosting,极限梯度提升
- 2014年诞生
- 大规模并行boosted tree的工具:复合树(tree ensemble)模型
- 专注于梯度提升算法
- 优良的学习效果及高效的训练速度
- 2015 kaggle比赛,29个获胜,17个使用XGBoost库,11个使用神经网络
- 解决监督学习问题
GBDT:梯度提升决策树
- XGBoost实现的是通用的tree boosting算法,次方法的代表是GBDT
- GBDT训练原理:
- 使用训练集和真实值训练一棵树,用这棵树预测训练集,得到预测值
- 计算预测值和真实值之间的残差
- 训练第二颗树,此时不使用真实值作为标准答案,而使用残差作为标准答案,得到这颗树的预测值
- 计算此时的预测值和真实值之间的残差
- 以此类推
- GBDT预测:对于新的样本,每棵树否有一个预测值,将这些值相加,即得到最终预测值。
- GBDT核心:
- 第二颗树开始,拟合的是前面预测值的残差
- 可一步步逼近真值
- 使用了平方损失作为损失函数: \(l(y_i, \hat{y_i})=(y_i - \hat{y_i})^2\)
-
如果使用其他损失,则残差不能再保证逼近真值
- 方案:从平方损失推广到二阶可导的损失?
- XGBoost
XGboost:GBDT的推广
GBDT是XGboost的一个特例:
- XGBoost:将任意的损失函数做泰勒展开到第二阶,使用前两阶作为改进的残差
- 可证明:GBDT使用的残差是泰勒展开到一阶的结果
- GBDT是XGBoost的一个特例
XGBoost:引入正则化项
- 防止模型过拟合,一般需引入正则化项
- 决策树的复杂度:树的深度
- XGBoost的复杂度:叶子节点的个数
- 加入L2正则化,平滑各叶子节点的预测值
支持列抽样
- 每棵树训练时,不使用所有特征
XGBoost vs GBDT
- GBDT以CART作为基分类器,xgboost还支持线性分类器(相当于带L1和L2正则项的逻辑回归或者线性回归)
- GBDT只用一阶导数信息,xgboost同时使用一阶和二阶导数(二阶泰勒展开)
- xgboost引入了正则项,可防止模型过拟合
- 缩减(shrinkage):迭代完一次后,将叶子节点的权重乘以该系数,以削减每棵树的影响。相当于学习速率。
- xgboost支持列抽样,借鉴随机森林的做法,降低过拟合,减少计算量。
- 缺失值处理。xgboost可自动学习出缺失值的分裂方向。
- xgboost支持并行。boosting是一个串行结构,学习一个,再学习另一个。所以这里的并行不是tree学习的并行,是在特征粒度上的。
参考
- KAGGLE ENSEMBLING GUIDE
- XGBoost简介
- chen tianqi: Introduction to Boosted Trees, 中文版翻译:XGBoost入门系列第一讲
- XGBoost浅入浅出@wepon
Read full-text »
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me