机器学习roadmap
2019-04-17
目录
这里列举了一些机器学习的一些知识图谱,主要来源于这里,同时还有如何选用不同的机器学习算法的map,可以参考一下。
Read full-text »
GAN
2019-04-07
目录
概述
生成对抗网络(Generative Adversarial Network, GAN),属于一种生成模型,通过生成样本,以训练模型,直到模型无法区分样本来源(真实 vs 生成)为止。
Read full-text »
深度学习调参技巧
2019-04-03
目录
调参
- 调参:
- trial-and-error
- 没有捷径可走。有人思考后再尝试,有人盲目尝试。
- 快速尝试:调参的关键
大方向
- 【1】刚开始,先上小规模数据,模型往大了放(能用256个filter就别用128个),直接奔着过拟合去(此时都可不用测试集验证集)
- 验证训练脚本的流程。小数据量,速度快,便于测试。
- 如果小数据、大网络,还不能过拟合,需要检查输入输出、代码是否错误、模型定义是否恰当、应用场景是否正确理解。比较神经网络没法拟合的问题,这种概率太小了。
- 【2】loss设计要合理
- 分类问题:softmax,回归:L2 loss。
- 输出也要做归一化。如果label为10000,输出为0,loss会巨大。
- 多任务情况时,各个loss限制在同一个量级上。
- 【3】观察loss胜于观察准确率
- 优化目标是loss
- 准确率是突变的,可能原来一直未0,保持上千代迭代,突变为1
- loss不会突变,可能之前没有下降太多,之后才稳定学习
- 【4】确认分类网络学习充分
- 分类 =》类别之间的界限
- 网络从类别模糊到清晰,可以看softmax输出的概率分布。刚开始,可能预测值都在0.5左右(模糊),学习之后才慢慢移动到0、1的极值
- 【5】学习速率是否设置合理
- 太大:loss爆炸或者nan
- 太小:loss下降太慢
- 当loss在当前LR下一路下降,但是不再下降了 =》可进一步降低LR
- 【6】对比训练集和验证集的loss
- 可判断是否过拟合
- 训练是否足够
- 是否需要early stop
- 【7】清楚receptive field大小
- CV中context window很重要
- 对模型的receptive field要有数
- 【8】在验证集上调参
数据
预处理
- -mean/std zero center已然足够,PCA、白化都用不上
- 注意shuffle
模型本身
- 理解网络的原理很重要,CNN的卷积这里,得明白sobel算子的边界检测
- CNN适合训练回答是否的问题
- google的Inception论文,结构要掌握
- 理想的模型:高高瘦瘦的,很深,但是每层的卷积核不多。很深:获得更好的非线性,模型容量指数增加,但是更难训练,面临梯度消失的风险。增加卷积核:可更好的拟合,降低train loss,但是也更容易过拟合。
- 如果训练RNN或者LSTM,务必保证梯度的norm(归一化的梯度)被约束在15或者5
- 限制权重大小:可以限制某些层权重的最大范数以使得模型更加泛化
参数初始化方法
- 用高斯分布初始化
- 用xavier
- word embedding:xavier训练慢结果差,改为uniform,训练速度飙升,结果也飙升。
- 良好的初始化,可以让参数更接近最优解,这可以大大提高收敛速度,也可以防止落入局部极小。
- relu激活函数:初始化推荐使用He normal
- tanh激活函数:推荐使用xavier(Glorot normal)
隐藏层的层数
节点数目
filter
- 用3x3大小
- 数量:2^n
- 第一层的filter数量不要太少,否则根本学不出来(底层特征很重要)
激活函数的选取
- 给神经网络加入一些非线性因素,使得网络可以解决较为复杂的问题
- 输出层:
- 多分类任务:softmax输出
- 二分类任务:sigmoid输出
- 回归任务:线性输出
- 中间层:优先选择relu,有效的解决sigmoid和tanh出现的梯度弥散问题
- CNN:先用ReLU
- RNN:优先选用tanh激活函数
dropout
- 可防止过拟合,人力成本最低的Ensemble
- 加dropout,加BN,加Data argumentation
- dropout可以随机的失活一些神经元,从而不参与训练
- 例子【Dropout 缓解过拟合】:
- 任务:拟合数据点(根据x值预测y值)
- 构建过拟合网络,比如这里使用了2层,每层节点数=200的网络
- 使用dropout和不使用dropout,看拟合的效果
- 可以看到,对于过拟合(模型对训练集拟合得很好)的情况下,使用dropout,能够降低在测试集上的loss,和真实值预测的更贴近。

损失函数
训练相关
学习速率
- 在优化算法中更新网络权重的幅度大小
- 可以是恒定的、逐渐下降的、基于动量的或者是自适应的
- 优先调这个LR:会很大程度上影响模型的表现
- 如果太大,会很震荡,类似于二次抛物线寻找最小值
- 一般学习率从0.1或0.01开始尝试
- 通常取值[0.01, 0.001, 0.0001]
- 学习率一般要随着训练进行衰减。衰减系数设0.1,0.3,0.5均可,衰减时机,可以是验证集准确率不再上升时,或固定训练多少个周期以后自动进行衰减。
- 有人设计学习率的原则是监测一个比例:每次更新梯度的norm除以当前weight的norm,如果这个值在10e-3附近,且小于这个值,学习会很慢,如果大于这个值,那么学习很不稳定。

- 红线:初始学习率太大,导致振荡,应减小学习率,并从头开始训练
- 紫线:后期学习率过大导致无法拟合,应减小学习率,并重新训练后几轮
- 黄线:初始学习率过小,导致收敛慢,应增大学习率,并从头开始训练
batch size大小
- 每一次训练神经网络送入模型的样本数
- 可直接设置为16或者64。通常取值为:[16, 32, 64, 128]
- CPU讨厌16,32,64,这样的2的指数倍(为什么?)。GPU不会,GPU推荐取32的倍数。
momentum大小
- 使用默认的0.9
迭代次数
- 整个训练集输入到神经网络进行训练的次数
- 当训练集错误率和测试错误率想相差较小时:迭代次数合适
- 当测试错误率先变小后变大:迭代次数过大,需要减小,否则容易过拟合
优化器
- 自适应:Adagrad, Adadelta, RMSprop, Adam
- 整体来讲,Adam是最好的选择
- SGD:虽然能达到极大值,运行时间长,可能被困在鞍点
- Adam: 学习速率3e-4。能快速收敛。
残差块和BN
- 残差块:可以让你的网络训练的更深
- BN:加速训练速度,有效防止梯度消失与梯度爆炸,具有防止过拟合的效果
- 构建网络时最好加上这两个组件
案例:人脸特征点检测
这篇文章(Using convolutional neural nets to detect facial keypoints tutorial)是14年获得kaggle人脸特征点检测第二名的post,详细的描述了如何构建模型并一步步的优化,里面的一些思路其实很直接干脆,可以参考一下。
- 任务:人脸特征点检测
- 样本:7049个96x96的灰度图像,15个特征点坐标(15x2=30个坐标值)
- 探索:
- 全部特征点都有label的样本有多少?
- 每个特征点对应的有label的样本有多少?
- 预处理:
- 灰度图像归一化:[0,1]
- 坐标值(y值)归一化:[-1,1]
- 构建简单的单层网络【net1】,发现是过拟合的(训练集的loss比验证集的loss低很多)
- 网络过于简单?使用卷积神经网络【net2】。卷积神经网络效果好很多此时对应的训练集和验证集的loss都比【net1】低很多,且loss比较平滑,但是模型还是过拟合的。
- 预防过拟合?使用更多的数据,这里是kaggle提供的数据集,没办法获得更多的数据,又是图像数据,可以使用数据增强【net3】。
- 比如最简单的是图像水平翻转
- 这里检测特征点,注意翻转前后特征点也要变化,比如原来的左眼左角,水平翻转之后变成了右眼的右角。
- 这里的翻转不需要重新生成数据集,可在load batch数据时做
 transformation转换(很方便)
transformation转换(很方便)
- 网络本身的可调参数,比如学习率或者动量大小,之前用的是默认值,是否还有优化的余地?学习率和动量的动态变化,对于上面的网络都进行这两个参数修改的尝试:卷积+学习率/动量【net4】,卷积+数据增强+学习率/动量【net5】
- 学习率:开始学习使用大的学习率,然后在训练过程中慢慢较小。比如:回家先坐火车,快到家门时改用走路。
- 动量大小:在训练过程中增加动量的大小

- dropout【net6】是否能进一步减小过拟合?
- 一定要先训练得好,最好过拟合,然后再做正则化
- 注意此时训练集和验证集的loss的比值,前者是带有dropout计算出来的loss,后者的loss是没有的
- 增大训练的次数似乎可以降低loss【net7】?
- dropout之后,其实loss可以进一步减小的

Name | Description | Epochs | Train loss | Valid loss
-------|------------------|----------|--------------|--------------
net1 | single hidden | 400 | 0.002244 | 0.003255
net2 | convolutions | 1000 | 0.001079 | 0.001566
net3 | augmentation | 3000 | 0.000678 | 0.001288
net4 | mom + lr adj | 1000 | 0.000496 | 0.001387
net5 | net4 + augment | 2000 | 0.000373 | 0.001184
net6 | net5 + dropout | 3000 | 0.001306 | 0.001121
net7 | net6 + epochs | 10000 | 0.000760 | 0.000787
- 单独的训练?
- 上面训练时是并行的,同时检测15个特征点
- 只使用了15个特征点都有坐标值的样本,其他数据(70%)都被丢掉了,这是很影响最后模型的泛化效果的,尤其是当去预测测试集样本的时候
- 可以每个特征点单独进行分类器训练,就使用上面最好的模型,此时对应的样本数目也是更多的
- 这里用了一个训练时设置的字典型变量,遍历特征点训练,可以参考
- 此时,对于每个特征,可能需要训练的次数不用那么多,那么可以设置early stopping(这里n=200)
- 最后拿到了2.17的RMSE,直接飙升到底2名

- 使用pre-train的模型?
- 网络参数的初始化也很重要
- 可以使用上面训练好的网络,比如net6或者net7的参数进行初始化
- 这也是一个正则化的效果
- 此时的RMSE降低了一点到2.13,仍然是第2名

参考
- 总结知乎深度学习调参技巧
- 深度学习调参技巧
- A Recipe for Training Neural Networks @Karpathy
- Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei)
- Training Tips for the Transformer Model
- Bag of Tricks for Image Classification with Convolutional Neural Networks
Read full-text »
Auto encoder
2019-03-29
目录
概述
自编码(auto encoder):把输入数据进行一个压缩和解压缩的过程,对高维数据的一个低维表示,同时最大限度的保留原始数据信息。
1、框架(包含3个部分):

- Encoding Architecture :包含一些列的层,层里的节点数目是减少的,最后得到一个隐藏特征的表示。
- Latent View Repersentation : 隐藏特征的视图,最小的特征空间,保留原始的数据信息。
- Decoding Architecture : 编码结构的镜像,包含一些列的层,层里的节点数目是减少的,通过对隐藏特征空间的变换,恢复到(近似)原始的数据。
2、例子:这里通过一个二维线性分布的数据点,进行编码转换到一维,从而实现自编码过程,可以参考一下。
3、优缺点:
- 大数据降维
-
解决非线性问题
- 训练是计算消耗大
- 解释性差
- 低层的数学模型较复杂
- 容易过拟合
4、可视化:通过可视化,可以看到不同的神经元是学习到图像不同的位置和角度的特征。下图是100个神经元的隐藏层可视化:

实现
keras版本
这里有个简单的实现版本。使用keras构建了一个自编码解码器,其有四个编码层,分别把图像特征从原始的784(28x28)维降至128、64、10、2维,然后进行解码。同时,提取了仅编码后的结果(2维)进行可视化(相当于看编码的效果好不好)。
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Dense, Input
import matplotlib.pyplot as plt
# download the mnist to the path '~/.keras/datasets/' if it is the first time to be called
# X shape (60,000 28x28), y shape (10,000, )
(x_train, _), (x_test, y_test) = mnist.load_data()
# data pre-processing
x_train = x_train.astype('float32') / 255. - 0.5 # minmax_normalized
x_test = x_test.astype('float32') / 255. - 0.5 # minmax_normalized
x_train = x_train.reshape((x_train.shape[0], -1))
x_test = x_test.reshape((x_test.shape[0], -1))
print(x_train.shape)
print(x_test.shape)
"""
(60000, 784)
(10000, 784)
"""
# in order to plot in a 2D figure
encoding_dim = 2
# this is our input placeholder
# define input layer
input_img = Input(shape=(784,))
# encoder layers
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(10, activation='relu')(encoded)
encoder_output = Dense(encoding_dim)(encoded)
# decoder layers
decoded = Dense(10, activation='relu')(encoder_output)
decoded = Dense(64, activation='relu')(decoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='tanh')(decoded)
# construct the autoencoder model
autoencoder = Model(input=input_img, output=decoded)
# construct the encoder model for plotting
# 这里的encoder就是整个AE的一部分,不需要在重新compile和fit,可直接提取
encoder = Model(input=input_img, output=encoder_output)
# compile autoencoder
autoencoder.compile(optimizer='adam', loss='mse')
# training
autoencoder.fit(x_train, x_train,
nb_epoch=20,
batch_size=256,
shuffle=True)
# plotting
# dot color by y_test (label, already known)
encoded_imgs = encoder.predict(x_test)
plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c=y_test)
plt.colorbar()
plt.show()
pytorch版本
这里给出了一个pytorch的版本,编码部分是4个网络层,最后降至3维,因为要想在3维空间进行可视化。
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
# 超参数
EPOCH = 10
BATCH_SIZE = 64
LR = 0.005
DOWNLOAD_MNIST = True # 下过数据的话, 就可以设置成 False
N_TEST_IMG = 5 # 到时候显示 5张图片看效果, 如上图一
# Mnist digits dataset
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST, # download it if you don't have it
)
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# 压缩
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.Tanh(), # 这里使用的是tanh作为激活函数,不是relu函数
nn.Linear(128, 64),
nn.Tanh(),
nn.Linear(64, 12),
nn.Tanh(),
nn.Linear(12, 3), # 压缩成3个特征, 进行 3D 图像可视化
)
# 解压
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(),
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128),
nn.Tanh(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # 激励函数让输出值在 (0, 1)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
autoencoder = AutoEncoder()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
loss_func = nn.MSELoss()
for epoch in range(EPOCH):
for step, (x, b_label) in enumerate(train_loader):
b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28)
b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28)
encoded, decoded = autoencoder(b_x)
loss = loss_func(decoded, b_y) # mean square error
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
tensorflow版本
# Parameter
learning_rate = 0.01
training_epochs = 5 # 五组训练
batch_size = 256
display_step = 1
examples_to_show = 10
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
# hidden layer settings
n_hidden_1 = 256 # 1st layer num features
n_hidden_2 = 128 # 2nd layer num features
weights = {
'encoder_h1':tf.Variable(tf.random_normal([n_input,n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2,n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
# Building the encoder
def encoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# Building the decoder
def decoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
# Construct model
encoder_op = encoder(X) # 128 Features
decoder_op = decoder(encoder_op) # 784 Features
# Prediction
y_pred = decoder_op # After
# Targets (Labels) are the input data.
y_true = X # Before
# Define loss and optimizer, minimize the squared error
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
# Launch the graph
with tf.Session() as sess:
# tf 马上就要废弃tf.initialize_all_variables()这种写法
# 替换成下面:
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples/batch_size)
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# # Applying encode and decode over test set
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
参考
- An Introduction to Neural Networks and Autoencoders
- PCA & Autoencoders: Algorithms Everyone Can Understand
- How Autoencoders work - Understanding the math and implementation
- Autoencoder 自编码
- AutoEncoder (自编码/非监督学习)
Read full-text »
【5-3】序列模型和注意力机制
2019-03-23
目录
基础模型
- seq2seq模型:
- sequence to sequence
- 机器翻译
- 语音识别
- 例子:机器翻译【seq2seq】
- 输入:法语句子
- 输出:英语句子
- 模型:
- 编码网络:RNN结构,可向其中输入法语句子,接收完法语之后,会输出一个向量表示这个输入的法语句子
- 解码网络:编码的输出作为输入,训练输出一个个的词,每个预测的词作为下一个的输入进行预测

- 例子:图片描述【image to sequence】
- 输入:一张图片
- 输出:图像描述
- 模型:
- 编码网络;预训练的图像表示网络,用于提取图片的特征
- 预测网络:基于图片特征向量,生成描述,可用RNN模型,最后会输出一个序列

选择最可能的句子
- 语言模型:
- 估计句子的可能性
- 比如给定中间的词,预测上下文的词
- 比如给定上下文的词,预测中间的词
- 机器翻译:
- 条件语言模型
- 输入法语句子
- 输出英语句子,估计一个英文翻译的概率。这个英语句子是相对于输入的法语句子的可能性,所以是一个条件语言模型。

- 翻译概率最大化:
- 输入:一个法语句子
- 输出:一个翻译的英文句子
- 目的:不是想随机的输出,想输出一个很好的翻译。你会有很多的翻译可能性,那么就是要找到最合适的翻译y,使得这个条件概率(在给定法语句子时英语翻译的概率)最大化。
- 做法:集束搜索(beam search)

- 为什么不用贪心算法?
- 如果这里用贪心算法,做法就是这样的:生成第一个词的分布,选择最可能的一个;挑选了第一个后,继续挑选第2个最有可能的,如此继续。每一步都是挑选最优的一个。
- 翻译本质:挑选一个整体最优的,而这个最优的可能不是第一步最最优的,或者不是第二步是最优的。
- 例子:看下面的两个翻译
- 贪心:选择了”Jane is“之后,贪心会选择”going“,因为这个词是更常见的,概率是更大的。
- 但是显然第1个翻译比第2个是更好的,所以根据贪心的算法,最后可能选择了一个欠佳的翻译。

- 另外,每一步词的可选数量就是整个词典的大小,那么所有的都要进行计算的话,是不现实的。
- 近似搜索算法:尽力挑选出句子y使得条件概率最大,但不能保证找到的y值一定可以使得概率最大化。
集束搜索
- 核心:每一步都是选出B个最可能的单词,而不是一个
- 参数B:集束宽,beam width,考虑多少个选择
- 例子:
- 【挑选第1个单词】
- 在给定输入的情况下,获得了输入的表示向量。词向量输入到解码网络中,预测第1个词是什么。解码网络有一个softmax层,会得到10000个单词的概率值,那么取前B个(比如这里是3个)单词存下来便于后面使用。

- 【挑选第2个单词】
- 比如第1步选出来最有可能的3个词:in、jane、september
- 接下来选择第2个词,怎么选?对于第一步选的3个词,分别作为y2的输入,预测此时对应的y2,选取其对应的概率值最大的3个。这样就得到了,输入法语句子+输出一个词特定的条件下,第二个词应该选择什么。

- 【挑选第3个单词】
- 类似的,对于上面的情况,分别进行讨论,看在对应的第1、第2个词的情况下,保留第3个最大的情况
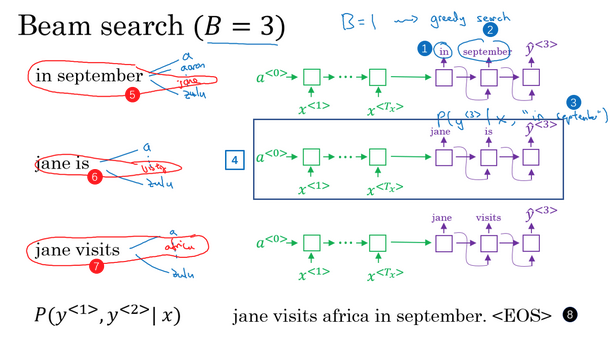
- 不断进行搜索,一次增加一个单词,直到句尾终止。
- 集束搜索 vs 贪心算法:
- 束宽的值可以选取不同的
- 当束宽=1时,每次就只考虑一个可能结果 =》贪婪搜索算法
改进集束搜索
- 乘积概率 =》对数概率和:
- 最大化的概率:乘积概率
- 概率值小于1,且通常远小于1。很多数相乘,会造成数值下溢(数值太小,电脑的浮点表示不能准确存储)。
- 乘积概率转为对数概率和:便于存储和计算
- 长度归一化:
- 原来:长句子 =》概率值低,短句子 =》概率值高。
- 缺点:可能不自然的倾向于简短的翻译结果,更偏向于短的输出,因为短句子的概率是由更少数目的小于1的数字乘积得到,所以不会那么小。
- 归一化:除以翻译结果的单词数量,就是取每个单词的概率对数值的平均,可明显的减少对输出长的结果的惩罚。

- 归一化的对数似然目标函数
- 探索性:在长度Ty上加一个指数a,a可以取0.7,1.0之类的。如果a=1.0,就是完全长度归一化,如果a=0,那么就是没有归一化。设置适当的值,可以获得不同的效果。
- 如何选取束宽值B?
- B越大,考虑的选择越多,找到的句子可能越好,但是计算代价越大
- B越小,考虑的选择越少,找到的句子可能不好,但是计算代价越小
- 例子中使用的是3,实践中是偏小的
- 在产品中可设置到10,100可能是偏大的
- 束宽1变为3,模型的效果可能有所提升;束宽1000变为3000,模型的效果可能没有太多提升。
集束搜索的误差分析
- 误差分析:通过分析错误样本,定位模型的性能瓶颈,指导下一步应该从哪里进行改进
- 翻译模型:
- 组成:seq2seq模型(RNN的编码和解码器) + 集束搜索模型(寻找可能最优的翻译)
-
要么是RNN出错,要么是集束搜索出错,如何定位?
- 输入:法语句子
- 真实翻译:人的翻译\(y^*\)
-
算法翻译:算法的输出\(\overline{y}\)
- 做法:使用RNN模型计算两个概率,一个是在给定x下,人的翻译的条件概率:\(P(y^*\|x)\);一个是在给定x下,算法的翻译的条件概率:\(P(\overline{y}\|x)\)
- 判断:如果\(P(y^*\|x)\)大于\(P(\overline{y}\|x)\),真实的人的翻译比算法选择的更好,但是最后搜索算法选择了现在的\(\overline{y}\),说明是集束搜索算法出现了问题。
- 判断:如果\(P(y^*\|x)\)小于\(P(\overline{y}\|x)\),真实的情况是真实的人的翻译比算法选择的更好,但是算法却计算出前者概率更小,算法也确实是输出了基于RNN的更好的\(P(\overline{y}\|x)\),所以算法没有问题,是RNN模型本身不够好。

- 误差分析:
- 遍历数据集或者挑选一些例子
- 对于每个例子,用RNN模型计算上面提到的概率值
- 根据上面的判断原则,确定每个样本中是哪一个部分出现了问题:RNN还是beam搜索?
- 最后统计一下两者的比例,就知道接下来应该优化哪一部分了

Bleu得分
- 问题:当有同样好的多个答案时,怎样评估一个机器翻译系统?
- BLEU得分:
- 给定一个机器生成的翻译,自动计算一个分数来衡量机器翻译的好坏
- bilingual evaluation understudy:双语评估替补
- 相当于一个候选者,代替人类来评估机器翻译的每一个输出结果
- 评估:
- 机器翻译的精确度:输出的结果中的每一个词是否出现在参考中
- 下面例子:MT(机器翻译)输出,输出长度为7,每个词the都出现在参考中,所以精确度=7/7。
- 显然不是一个好的翻译
- 引入计分上限:这个词在参考句子中出现的最多次数,比如这里the在参考中出现最多的是2次,所以其上限是2.
- 改良后的精确度评估:2/7。分母:单词总的出现次数,分子:单词出现的计数,考虑上限。

- 二元词组的BLEU得分:
- 上面的其实是考虑的单个单词
- 其实句子还可考虑二元或者三元的词组得分
- 列出机器翻译中所有的二元词组
- 统计每个二元词组在机器翻译中出现的次数(count)
- 统计每个二元词组在参考中出现的考虑上限的计数(the clipped count)。比如这里的the cat在参考中最多出现1次,所以其截取计数是1而不是2.
- 改良后的精度:截取计数和/计数和

- 任意元词组的BLEU得分公式化:
- 一元、二元、三元词组等
- 每一个,就可以计算其改良后的精度:n元词组的countclip之和除以n元词组的出现次数之和

- 最终BLEU得分:
- 把不同元词组的得分加起来
- 不是直接相加,是进行指数的乘方运算翻译
- 引入了一个惩罚因子BP:因为短的翻译可能会更容易得到一个更高精度的,但是我们不想要那么短的翻译

- 有用的单一实数评估指标,用于评估生成文本的算法,判断输出的结果是否与人工写出的参考文本的含义相似
注意力模型直观理解
- 长句的问题:
- 基本模型:编码解码模型,读完一整个句子,再翻译
- 对短句子效果好,有比较高的Bleu分数
- 对长的句子表现变差,记忆长句子比较困难
- 人的翻译过程:看一部分,翻译一部分,一直这样下去
- 所以在基本的RNN中,对于长句会有一个巨大的下倾
- 下倾:衡量了神经网络记忆一个长句子的能力
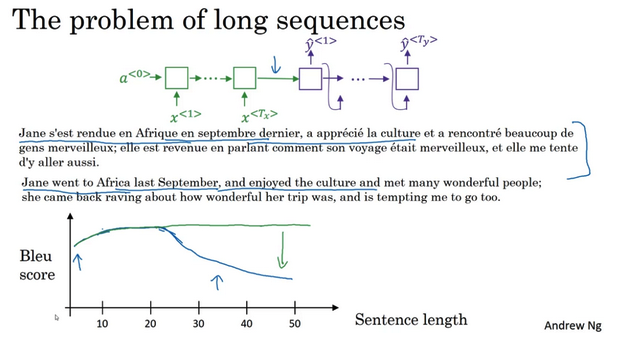
- 基本模型:编码解码模型,读完一整个句子,再翻译
- 注意力模型:
- 在生成第t个英文词时,计算要花多少注意力在第t个发语词上面

- 在生成第t个英文词时,计算要花多少注意力在第t个发语词上面
注意力模型
- 注意力模型:让神经网络只注意到一部分的输入句子,所以当生成句子的时候,更像人类翻译。
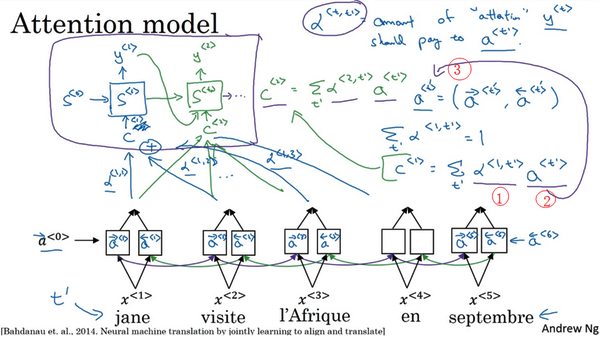
- 计算注意力:
- 使用对数形式,保证值的加和为1

- 缺点:花费三次方的时间
- 一般输出的句子不会太长,三次方也许是可以接受的
- 使用对数形式,保证值的加和为1
语音识别
- 语音视频问题:
- 输入:一个音频片段x
- 输出:自动生成文本y
- 处理步骤:原始音频片段 =》 生成一个声谱图 =》识别系统

- 音位模型:
- 曾经是通过音位来构建
- 音位:人工设计的基本单元
- 用音位表示音频数据
- 端到端的模型:
- 现在使用的
- 输入音频片段
-
直接输出音频的文本
- 需要很大的数据集:可能长达300小时
- 学术界:甚至达到3000小时
- 商业系统:超过1万小时的也有
- 注意力模型:
- 在输入音频的不同时间帧上,可以用一个注意力模型

- 在输入音频的不同时间帧上,可以用一个注意力模型
- CTC损失函数模型:
- CTC:connectionist temporal classification
- 比如输入一个10秒的音频,特征是100赫兹(每秒有100个样本),那么这个音频就有1000个输入
- 当有1000个输入时,对应的文本输出应该是没有1000个的。那怎么办?
- 引入空白符,用下划线”“表示,比如”h_eee“,”__qqq”等。
- CTC基本规则:将空白符之间的重复的字符折叠起来。
- CTC输出:可以强制输出1000个字符,但是包含空白符,它们是可以折叠的,最后uniq的字符会很少。

触发字检测
- 触发字检测系统:
- 通过声音来唤醒
- 不同的设备厂商有不同的触发字

- 检测算法:
- 处于发展阶段,最好的算法是什么尚无定论
- RNN结构:
- 计算音频片段的声谱图特征,得到特征向量
- 特征向量输入到RNN中
- 定义目标标签:在某个触发字的位置设为标签为1,说到触发字之前的位置设置标签为0。一段时间后,又说了触发字,此点设为标签1.
- 缺点:构建的是一个很不平衡的训练集,因为0比1的数量多很多。

- 解决:简单粗暴的,在固定的一段时间内输出多个1,而不是仅在一个时间步上输出1。可稍微提高1与0的比例。
参考
Read full-text »
【5-2】自然语言处理与词嵌入
2019-03-17
目录
词汇表征?
- 词嵌入:自动理解一些类似的词
- 比如男人对女人
- 国王对王后等
- 词语表示:独热编码
- 最常见的是one-hot方式
- 用词典来表示
- 缺点:把每个词孤立起来,算法对于相关词的泛化能力不强
- 为什么不好?因为这样的表示任意两个词都是相同长度的向量表示,但是只在其对应的位置为1,其他位置均为0.那么任意两个词向量的內积是0,所以相互之间没有任何区分性,比如king和apple相对于orange来说都是一样的。但是我们知道apple应该是更相似的。
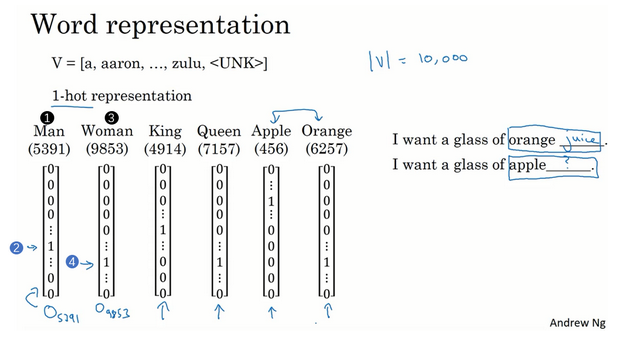
- 词语表示:特征化
- 使用不同的特征:比如性别,食物等
- 比如几百个特征,对于每个特征,看每个词在这个特征里面的取值
- 这样每个词都是一个特征向量来表示的
- 此时对于orange和apple可能就很相似了
- 从而对于不同的单词其泛化能力会更好

- 词嵌入可视化:
- 把特征向量(比如300维的)嵌入到一个二维空间中,进行可视化
- 常见算法:t-SNE
- 对于相近的概念,学到的特征也比较类似,在可视化的时候,概念比较相似,最终也会映射为相似的特征向量

使用词嵌入
- 例子:命名实体识别
- 找出人名
- 比如下面例子中的两句:一个说是橘子农民,一个是苹果农民,那么如果学到第一个句子中Sally是人名,同样应该可以学到下面的Robert也是农民。
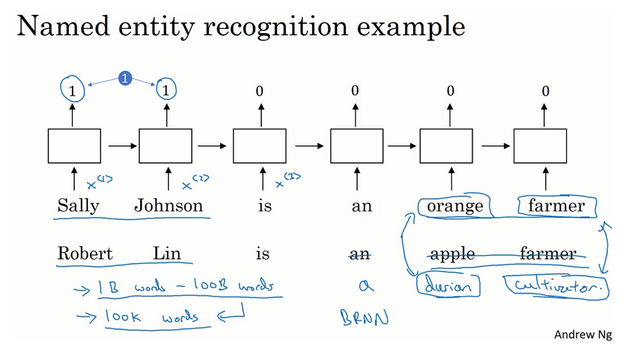
- 为什么有这个效果?
- 学习词嵌入的算法会考察非常大的文本集
- 词嵌入做迁移学习:
- 基于大量的文本集中学习词嵌入。下载文本集或者训练好的模型。
- 把词模型迁移到新的只有少量标注训练集的任务中。比如下载的训练好的模型对每个词是300维向量表示,那么就可以用这个来表示自己的数据集,而摒弃比如说one-hot编码的方式。
- 自行选择是否微调模型。如果上一步中自己有很多的数据,可以微调,如果数据很少,不必微调。
- 应用:命名实体识别、文本摘要、文本解析、指代消解,非常标准的NLP任务中
- 在语言模型、机器翻译用的少,因为这种任务中数据集很大。迁移学习在任务数据量很少的时候比较适用。

- 词嵌入 vs 人脸编码:
- 词嵌入:只有固定的词汇表,一些没出现过的单词记为未知
- 人脸编码:用向量表示人脸,未来涉及到海量的人脸照片
词嵌入的特性
- 实现类比推理
- 问题形式如:如果man对应woman,那么king对应什么?
- 对应问题转换为向量表示
- 每个单词都有词特征向量表示
- man对应woman,可得到这两个特征向量的差值
- king和什么对应?其实是:找一个词的特征向量,使得其和king的差值与man、woman的差值是近似相等的,即: \(e_{man} - e_{woman} = e_{king} - e_{?}\)

- 算法表示:
- 找一个向量,使得两组差异近似
- 转换:找到单词w使得\(e_w\)与\(e_{king} - e_{man} + e_{woman}\)的相似度最大化
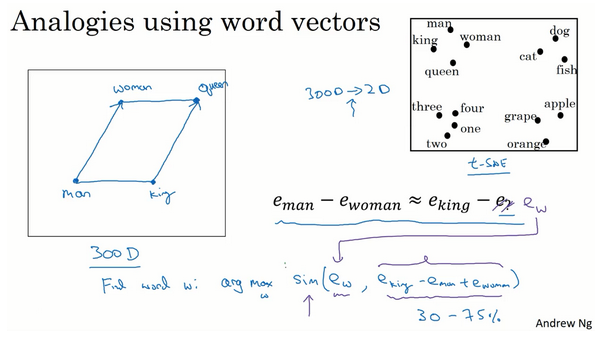
- 类比推理准确率很难到100%,一般是30%-75%
- 相似度:
- 余弦相似度:其实就是两个向量夹角(角度越小,越相似)的余弦值
- 如果夹角=0,两个很相似,相似度=1
- 如果夹角=90,两个很不相似,相似度=0
- 如果夹角=180,两个呈现完全相反的方向,相似度=-1

嵌入矩阵
- 算法:学习词嵌入 =》学习一个嵌入矩阵
- 嵌入矩阵E x 独热编码 = 词向量e
- 词典是:10000
- 词特征是:300
- 嵌入矩阵:300x10000
- 某一个词的独热编码是:10000x1
- 这个词的词特征矩阵:嵌入矩阵(300x10000)与独热编码(10000x1)的內积,最后得到一个300维的向量,正好也是嵌入矩阵E下,这个词对应的300维向量

- 实际中:矩阵相乘效率低下,会有专门的函数查找矩阵E的某列。因为这个时候E是已经求解出来的,不用再通过相乘的方式去获得某个词的特征表示,而是直接索引获取。
学习词嵌入
- 学习词嵌入:有难的算法,也有简单的算法
- 模型流程:
- 输入一个句子,预测接下来的词是什么
- 每个词可以独热编码,求一个矩阵E,使用独热编码和矩阵E表示这个词的特征向量
- 把这些个词的特征向量(这里是300维x6个词=1800)输入到神经网络
- 最后输出到softmax进行预测,预测这个句子接下来是什么词语
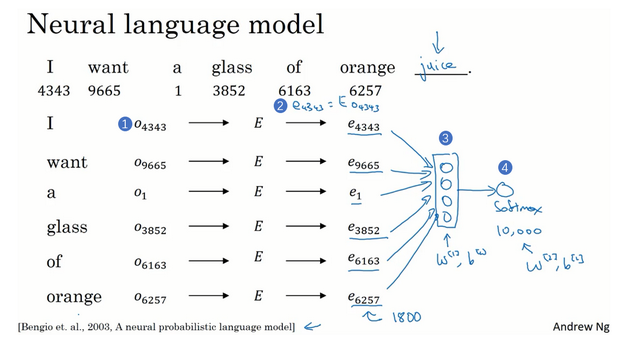
- 当有了训练集之后,就可以训练从而求得模型中的参数了,包括嵌入矩阵E的全部数值
- 问题?输入的句子长度是不一样的怎么办
- 输入不一样长?
- 常见:使用一个固定的历史窗口
- 比如总是输入4个词,预测接下来的一个词
- 那么此时输入到网络的是:300维x4个词=1200
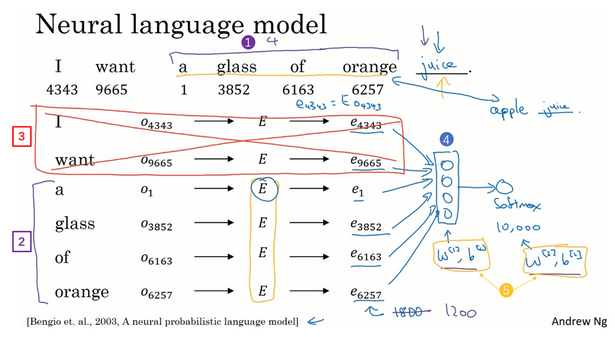
- 其他算法:
- 要预测的词:叫目标词,比如上面输入一句话,预测接下来的一个词,这个词就是目标词
- 问题:左边4个词+右边4个词,预测中间是什么词?
- 问题:一个词,预测接下来是什么词?
- 问题:前两位的一个词,当前词是什么?

Word2Vec
- Skip-Gram:
- 抽取上下文和目标配对,来构造一个监督学习问题
- 随机选取一个词作为上下文词(context)
- 在一定词距内选另一个词,比如前后5或者10个词,在这个范围内随机选取词(目标词,Target)
- 构造监督学习问题:根据上下文词,预测一定词距内随机选择的某个目标词

- 模型:
- 词汇表:10000
- 上下文词:独热向量*嵌入矩阵E得到其嵌入向量
- 嵌入向量输入softmax单元,预测不同目标词的概率:\(p(t\|c)=\frac{e^{ {\theta}_t^T e_c}}{\sum_{j=1}^{10000}e^{ {\theta}_t^T e_c}}\)
- 参数:\({\theta}_t\),与输出t有关的参数,即某个词t与标签相符的概率
- 这里的输入是x(上下文词),预测的是y(目标词):这里y是一个10000的向量,所有可能目标词的概率。
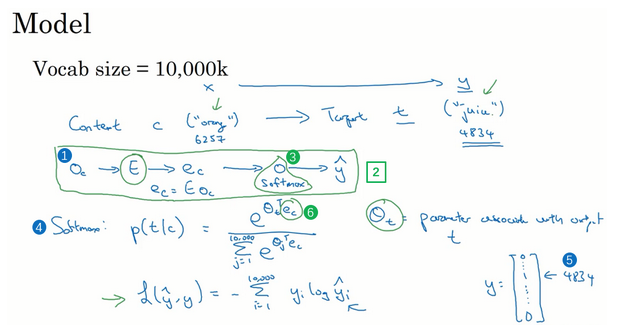
- 理解:输入一个词,预测其前面或者后面是什么词
- 问题:
- 计算速度慢
- 要对比如10000个概率进行计算并求和
- 解决:分级的softmax和负采样
- 分级的softmax:不是一下子就确定词语属于哪一类,而是类似二分,告诉你是属于前5000还是后5000,是前2500还是后2500.形成一个树形结构 =》计算成本与词汇表大小的对数成正比,而不是与词汇表的大小成正比。

- 上下文c进行采样?
- 为什么要采样?构建训练集
- 一旦上下文c确定了,目标词t就是c正负10词距内进行采样了
- 方案1:对语料库均匀且随机采样。有些词比如the、an等会出现得很频繁。
- 方案2:不同的分级来平衡更常见的词和不那么常见的词。
- Skip-Gram vs CBOW:
- skip-gram:输入一个词,预测其前面或者后面是什么词。从目标字词推测出原始语句。【造句】
- CBOW:continuous bag-of-words model,获得中间词两边的上下文,然后预测中间的词。从原始语句推测目标字词。【完形填空】
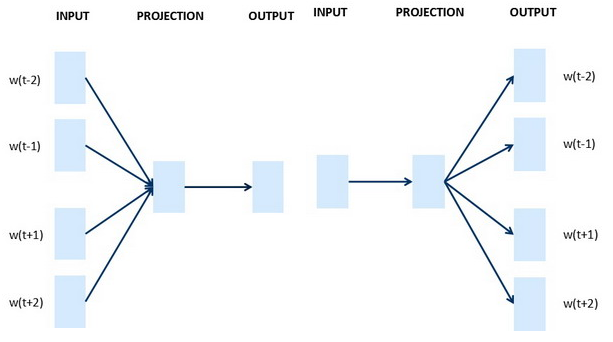
- 参考这里word2vec-pytorch/word2vec.ipynb看两种模型的具体实现
定义的模型:
class CBOW(nn.Module):
def __init__(self, vocab_size, embd_size, context_size, hidden_size):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embd_size)
self.linear1 = nn.Linear(2*context_size*embd_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, vocab_size)
def forward(self, inputs):
embedded = self.embeddings(inputs).view((1, -1))
hid = F.relu(self.linear1(embedded))
out = self.linear2(hid)
log_probs = F.log_softmax(out)
return log_probs
class SkipGram(nn.Module):
def __init__(self, vocab_size, embd_size):
super(SkipGram, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embd_size)
def forward(self, focus, context):
embed_focus = self.embeddings(focus).view((1, -1))
embed_ctx = self.embeddings(context).view((1, -1))
score = torch.mm(embed_focus, torch.t(embed_ctx))
log_probs = F.logsigmoid(score)
return log_probs
负采样
- 新监督学习问题:给定一对单词,预测这是否是一对上下文词-目标词(context-target)
- 样本:
- 正样本:采样得到一个上下文词和一个目标词,此对词标记为1(正样本)
- 负样本:使用上面相同的上下文词,在在字典中随机选取一个词,此对词标记为0(负样本)。随机选取的一个词如果在上下文词的一定词距之内,也没关系。
- 一般负样本给定k次:就是对每个正样本的相同上下文词,重复k次随机选取词,作为负样本。

- 训练:
- 监督学习算法
- 输入:x,一对对的词
- 预测:y,这对词会不会一起出现,还是随机取到的,算法就是要区分这两种采样方式。
- K值大小:小数据集取5-20,大数据集取小一点,更大的数据集取2-5,这里k=4
- 模型:
- softmax模型
- 输入x,输出y(0、1),是否是一对上下文-目标词。在给定的上下文词和目标词情况下,输出y=1的概率:\(P(y=1\|c,t)=\sigma(\theta_t^Te_c)\)
- 1一个正样本+K个负样本训练一个类似逻辑回归的模型
- 基于逻辑回归:将sigmoid函数作用于\(\theta_t^Te_c\)
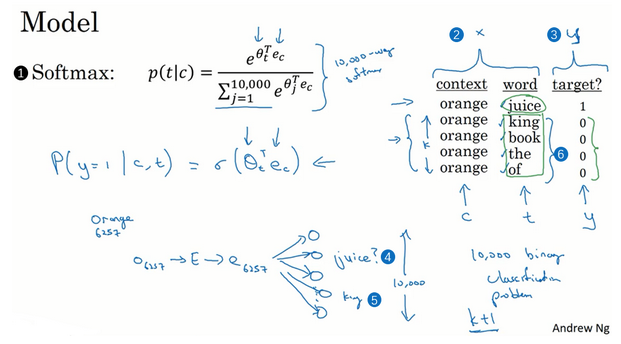
- 每次迭代做k+1个分类问题,所以计算成本比更新10000维的softmax分类器成本低
- 如何选取负样本?
- 上面说了:从字典里面随机选取?
- 方案1:根据词出现的频率进行采样。the、an这类词会很高频。
- 方案2:均匀随机抽样,对于英文单词的分布非常没有代表性。
- 方案3:根据这个频率值来选取,\(P(w_i)=\frac{f(w_i)^{\frac{3}{4}}}{\sum_{j=1}^{100000}f(w_i)^{\frac{3}{4}}}\)。通过词频的3/4次方的计算,使其处于完全独立的分布和训练集的观测分布两个极端之间。
对于skim-gram和CBOW两种模型,根据给定的text数据生成训练数据的方式:
# context window size is two
def create_cbow_dataset(text):
data = []
for i in range(2, len(text) - 2):
context = [text[i - 2], text[i - 1],
text[i + 1], text[i + 2]]
target = text[i]
data.append((context, target))
return data
def create_skipgram_dataset(text):
import random
data = []
for i in range(2, len(text) - 2):
data.append((text[i], text[i-2], 1))
data.append((text[i], text[i-1], 1))
data.append((text[i], text[i+1], 1))
data.append((text[i], text[i+2], 1))
# negative sampling
for _ in range(4):
if random.random() < 0.5 or i >= len(text) - 3:
rand_id = random.randint(0, i-1)
else:
rand_id = random.randint(i+3, len(text)-1)
data.append((text[i], text[rand_id], 0))
return data
cbow_train = create_cbow_dataset(text)
skipgram_train = create_skipgram_dataset(text)
print('cbow sample', cbow_train[0])
print('skipgram sample', skipgram_train[0])
GloVe词向量
- GloVe:
- global vectors for word representation
- 用词表示的全局变量
- 对两个词的关系明确化
- 任意两个位置相近的词,比如上下文词和目标词,他们出现的频率应该是接近的

- 模型:
- 评估同时出现的频率是多少
- 对于任意的一对词,都可以得到这个
- 将差距最小化

- 额外的加权项f(Xij):能使得出现更频繁的词更大但不至于过分的权重
情感分类
- 情感分类任务:
- 看一段文本,分辨这个人是否喜欢他们在讨论的这个东西
- 挑战:标记的训练集没有那么多
- 例子:
- 餐馆评价
- x:评价的一段话,y:给出的几颗星(评价等级)

- 简单模型:
- 某一个评价作为例子
- 对于此评价的每个单词,通过独热编码向量和嵌入矩阵转换为嵌入向量
- 嵌入向量相加取平均。这个能保证最后取得维度是一样的,比如次特征向量是300维的,那么取平均之后还是300维的,且不受输入句子长度的影响。
- 平均后的向量输入softmax分类器
- 输出y:5个可能的结果的概率值
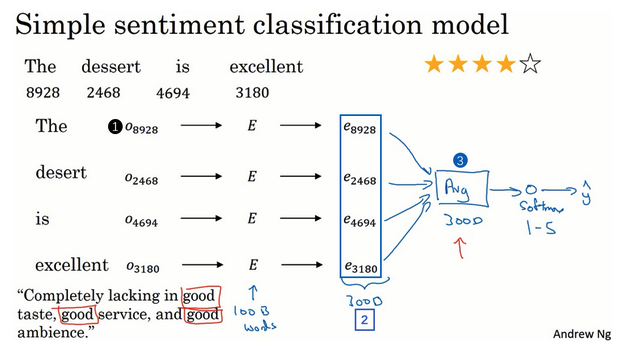
- 此处:【平均值运算单元】,把所有单词的意思给平均起来使用
- 问题:没有考虑词序,也就是一句话如果打乱顺序,最后的词向量平均表示是一样的,但是可能意思是不同的
- RNN版本模型:
- 每个单词通过独热编码向量和嵌入矩阵转换为嵌入向量
- 嵌入向量作为时序序列传到RNN模型中
- 属于多对一的模型,在最后一步才计算一个特征表示,用于预测输出
- 此时就考虑了句子的具体含义,效果更好

词嵌入除偏
- bias:是指学习到的东西存在性别、种族、性取向等方面的偏见。因为现在这些模型越来越多的参与到决策,所以需要排除这些偏见的影响。
- 例子:
- 可能学到man是程序员,但是woman是家庭主妇,这就是带有性别偏见的

- 可能学到man是程序员,但是woman是家庭主妇,这就是带有性别偏见的
- 消除偏见:
- 鉴定bias:比如有一些SUV算法,对一些词语进行聚类,不同的维度(偏见、不偏见)。如果在偏见轴大的,就是属于有偏见的。
- 中和:对于不确切的词可以处理一下,避免偏见。
- 均衡:有一些词保证它们只在一个维度是有差异的,比如grandmothers和grandfathers只在性别有差异,其他特征保证相等(在坐标抽上的距离是相当的)。

参考
Read full-text »
爬虫抓取微博内容
2019-03-12
抓取关键字搜索
现在有很多的工具和已成型的代码,用于在网络上爬虫抓取内容,进行情感分析或者趋势分析。这里的代码是参考的这里gaussic/weibo_wordcloud @github,尝试着抓取数据并对内容进行分词分析。
抓取:
# coding: utf-8
import re
import json
import requests
# 基于 m.weibo.cn 抓取少量数据,无需登陆验证
url_template = "https://m.weibo.cn/api/container/getIndex?type=wb&queryVal={}&containerid=100103type=2%26q%3D{}&page={}"
def clean_text(text):
"""清除文本中的标签等信息"""
dr = re.compile(r'(<)[^>]+>', re.S)
dd = dr.sub('', text)
dr = re.compile(r'#[^#]+#', re.S)
dd = dr.sub('', dd)
dr = re.compile(r'@[^ ]+ ', re.S)
dd = dr.sub('', dd)
return dd.strip()
def fetch_data(query_val, page_id):
"""抓取关键词某一页的数据"""
resp = requests.get(url_template.format(query_val, query_val, page_id))
card_group = json.loads(resp.text)['data']['cards'][0]['card_group']
print('url:', resp.url, ' --- 条数:', len(card_group))
mblogs = [] # 保存处理过的微博
for card in card_group:
mblog = card['mblog']
blog = {'mid': mblog['id'], # 微博id
'text': clean_text(mblog['text']), # 文本
'userid': str(mblog['user']['id']), # 用户id
'username': mblog['user']['screen_name'], # 用户名
'reposts_count': mblog['reposts_count'], # 转发
'comments_count': mblog['comments_count'], # 评论
'attitudes_count': mblog['attitudes_count'] # 点赞
}
mblogs.append(blog)
return mblogs
def remove_duplication(mblogs):
"""根据微博的id对微博进行去重"""
mid_set = {mblogs[0]['mid']}
new_blogs = []
for blog in mblogs[1:]:
if blog['mid'] not in mid_set:
new_blogs.append(blog)
mid_set.add(blog['mid'])
return new_blogs
def fetch_pages(query_val, page_num):
"""抓取关键词多页的数据"""
mblogs = []
for page_id in range(1 + page_num + 1):
try:
mblogs.extend(fetch_data(query_val, page_id))
except Exception as e:
print(e)
print("去重前:", len(mblogs))
mblogs = remove_duplication(mblogs)
print("去重后:", len(mblogs))
# 保存到 result.json 文件中
fp = open('result_{}.json'.format(query_val), 'w', encoding='utf-8')
json.dump(mblogs, fp, ensure_ascii=False, indent=4)
print("已保存至 result_{}.json".format(query_val))
if __name__ == '__main__':
fetch_pages('颜宁', 50)
抓取搜索颜宁的结果:
% /Users/gongjing/anaconda3/bin/python weibo_search.py
去重前: 454
去重后: 443
已保存至 result_颜宁.json
使用jieba分词,并画出词云图:
# coding: utf-8
import json
import jieba.analyse
import matplotlib as mpl
# from scipy.misc import imread
from imageio import imread
from wordcloud import WordCloud
# mpl.use('TkAgg')
import matplotlib.pyplot as plt
def keywords(mblogs):
text = []
for blog in mblogs:
keyword = jieba.analyse.extract_tags(blog['text'])
text.extend(keyword)
return text
def gen_img(texts, img_file):
data = ' '.join(text for text in texts)
image_coloring = imread(img_file)
wc = WordCloud(
background_color='white',
mask=image_coloring,
font_path='/Library/Fonts/STHeiti Light.ttc'
)
wc.generate(data)
# plt.figure()
# plt.imshow(wc, interpolation="bilinear")
# plt.axis("off")
# plt.show()
wc.to_file(img_file.split('.')[0] + '_wc.png')
if __name__ == '__main__':
keyword = '颜宁'
mblogs = json.loads(open('result_{}.json'.format(keyword), 'r', encoding='utf-8').read())
print('微博总数:', len(mblogs))
words = []
for blog in mblogs:
words.extend(jieba.analyse.extract_tags(blog['text']))
print("总词数:", len(words))
gen_img(words, 'yanning.jpg')
% /Users/gongjing/anaconda3/bin/python weibo_cloud.py
微博总数: 443
Building prefix dict from the default dictionary ...
Dumping model to file cache /var/folders/1c/bxl334sx7797nfp66vmrphxc0000gn/T/jieba.cache
Loading model cost 1.174 seconds.
Prefix dict has been built succesfully.
总词数: 6862
/Users/gongjing/anaconda3/bin/python weibo_cloud.py 4.07s user 0.98s system 80% cpu 6.305 total
生成的词云和颜宁老师的日常很像(尤其是朱一龙这个),但是因为给出的背景图辨识度不高,所以从词云里面不能一眼看不出就是她:

Read full-text »
AI application in life science
2019-03-12
目录
Review articles
- Machine Learning in Medicine
- A primer on deep learning in genomics
- A guide to deep learning in healthcare
参考
- Awesome Machine Learning for Healthcare @github
- Deep Learning in Healthcare and Computational Biology
- A curated list of ML,NLP resources for healthcare
Read full-text »
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me