Python module pytorch
2018-12-23
python pytorch 1
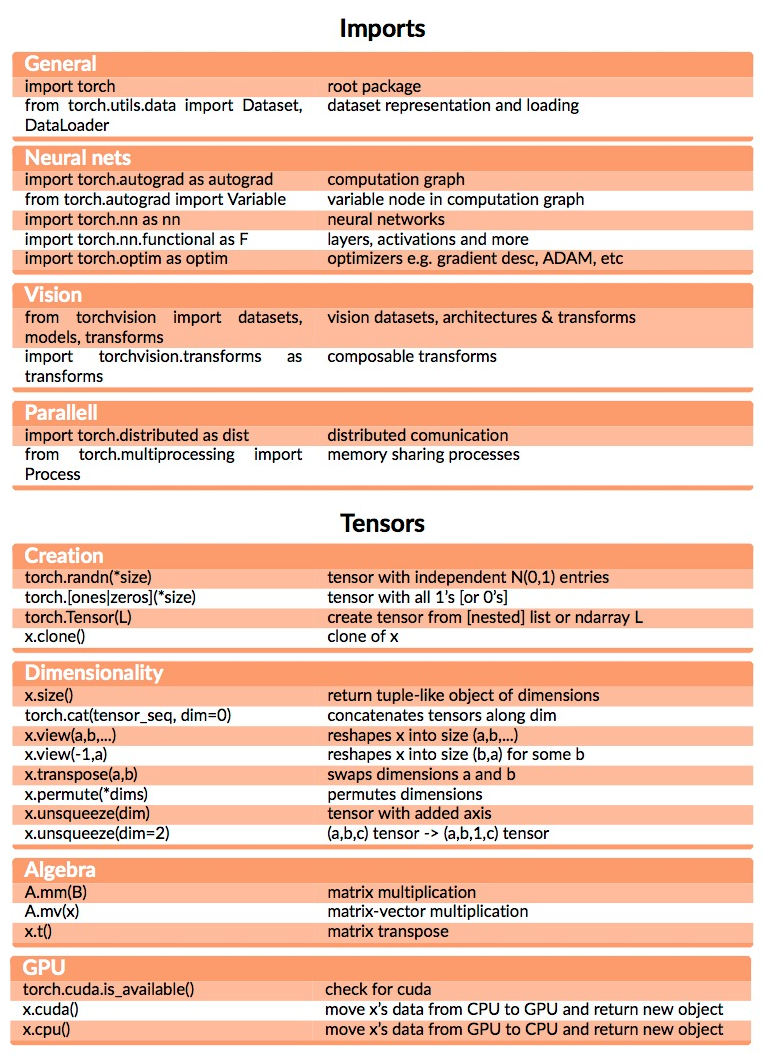
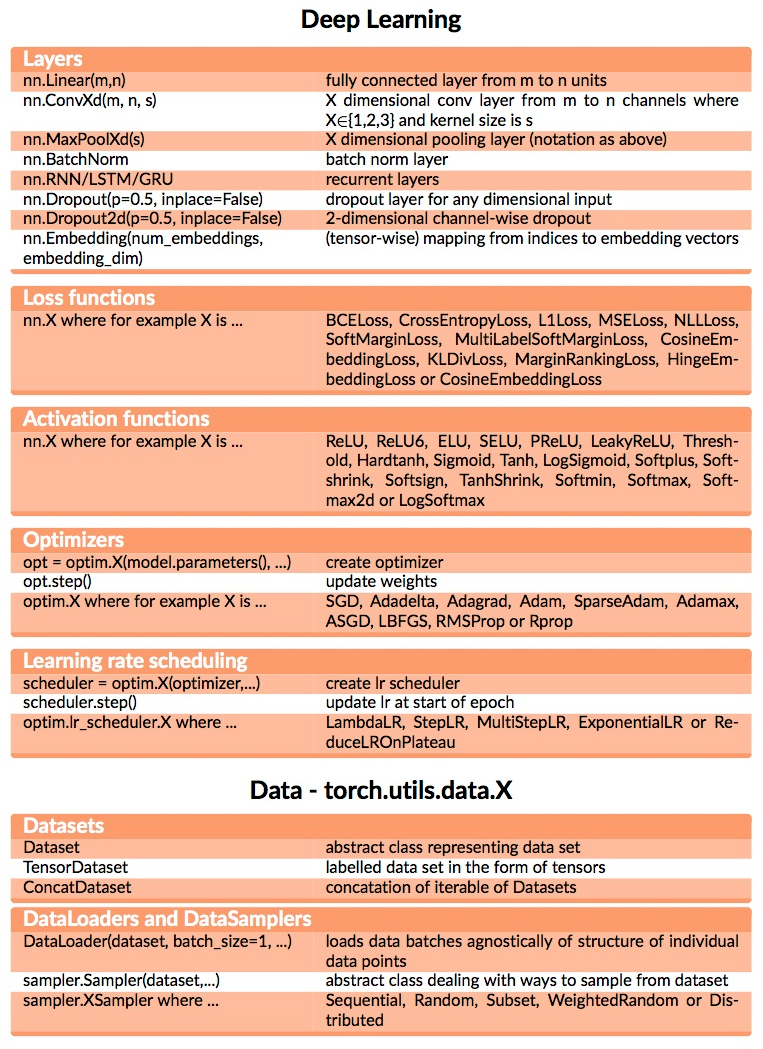
python pytorch 2





参考
Read full-text »
[CS229] 18: Application Example OCR
2018-12-23
18: Application Example OCR
- photo OCR:图片光学字符识别
- 让计算机识别图片中的文字
- OCR流程:
- 1)文字检测
- 2)字符分割
- 3)字符分类
- 4)拼写检查(可选)

- 流程(pipeline):多个不同的模块组成的,每个模块可以是单独的机器学习单元或者数据处理单元:
- 流程设计是一个很重要的问题
- 每个模块对于整体的性能都有影响
- 不同的工程师着力于不同的模块
- 滑动窗口图片分析:
- 文本检测:用特定长宽比的长方形在图片中滑动,以检测潜在的文字
- 行人识别:类似的例子。给定一个图片,找到里面的行人。同样的是特定长宽比(82x36)的长方形滑动检测。收集正负样本,构建神经网络模型,进行训练:

- 训练完后,就得到了模型。对于新的图片,一个个的滑框进行扫描,看预测的结果是否坚定道行人。
- 每次滑动的距离:步长(step size或者叫stride)通常为5-8个像素。
- 文本检测:类似于行人检测。
- 收集正负样本,训练模型

- 得到黑白图片:表征是否有图片的概率,黑(没有文字)和白(有文字):

- 接下来对上面的黑白结果进行扩展(expansion algorithm):就是对于白色(有文字)的像素,给定阈值,如果超过这个阈值(概率更大),就直接标记为白色,得到单存的黑白图片:

- 然后将图片中的白色区域用长方形框起来。
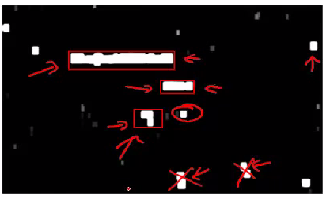
- 收集正负样本,训练模型
- 字符分割:
- 是否在字符之间存在分隔?
- 收集正负样本:

- 分类器训练:如果预测存在分隔,就插入一个分隔符。

- 字符分类:
- MNIST问题,识别数字或者字母
- 人工数据合成:
- 两个原则:1)随机生成,2)基于小训练集进行扩充。
- 比如对于字符,【1】可以从其他字体的库里选取,作为合成的数据:

- 【2】对原始数据进行变化,增加噪音(扭曲),如下是一个样本变为16个新样本:
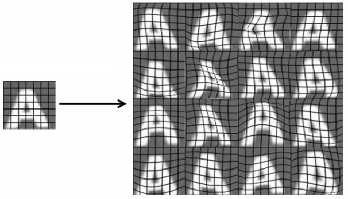
- 获取更多数据:
- 在创建新数据之前,确保模型是low bias的,通过学习曲线判断。如果不是的,应该先增加特征,再想着增加训练数据。
- 多久能获得10倍的数据?
- ceiling analysis瓶颈分析:确定整个流程的哪一个模块是对于整个模型的效果最有影响的。
- 对于每一个模块,每次只优化一个部分,使其准确性达到最高(比如100%),然后看现在的整体效果是否有提升:

- 比如在OCR的例子中,现在的准确性是72%,文本检测最高使模型达到89%,接着优化字符分割,使模型最高到89%,最后是字符识别,使模型最高到100%。
- 那么,完美文本识别提升17%,完美字符分割提升1%,完美字符识别提升10%,所以得知第一部分【文本识别】是最值得去提高的。
- 【ceiling】:is that each module has a ceiling by which making it perfect would improve the system overall
- 对于每一个模块,每次只优化一个部分,使其准确性达到最高(比如100%),然后看现在的整体效果是否有提升:
- 这个问题比较成熟,可调用python包
pytesser完成这个任务,参考这里,也有其他的包可以直接使用(tesserocr, pytesseract):
from PIL import Image
from pytesser import *
image_file = 'my_image.png'
im = Image.open(image_file)
text = image_to_string(im)
text = image_file_to_string(image_file)
text = image_file_to_string(image_file, graceful_errors=True)
print "=====output=======\n"
print text
- Keras OCR example @ here: 训练了一个卷积+循环网络+CTC logloss来进行OCR,可以参考一下
import os
import itertools
import codecs
import re
import datetime
import cairocffi as cairo
import editdistance
import numpy as np
from scipy import ndimage
import pylab
from keras import backend as K
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers import Input, Dense, Activation
from keras.layers import Reshape, Lambda
from keras.layers.merge import add, concatenate
from keras.models import Model
from keras.layers.recurrent import GRU
from keras.optimizers import SGD
from keras.utils.data_utils import get_file
from keras.preprocessing import image
import keras.callbacks
OUTPUT_DIR = 'image_ocr'
# character classes and matching regex filter
regex = r'^[a-z ]+$'
alphabet = u'abcdefghijklmnopqrstuvwxyz '
np.random.seed(55)
# this creates larger "blotches" of noise which look
# more realistic than just adding gaussian noise
# assumes greyscale with pixels ranging from 0 to 1
def speckle(img):
severity = np.random.uniform(0, 0.6)
blur = ndimage.gaussian_filter(np.random.randn(*img.shape) * severity, 1)
img_speck = (img + blur)
img_speck[img_speck > 1] = 1
img_speck[img_speck <= 0] = 0
return img_speck
# paints the string in a random location the bounding box
# also uses a random font, a slight random rotation,
# and a random amount of speckle noise
def paint_text(text, w, h, rotate=False, ud=False, multi_fonts=False):
surface = cairo.ImageSurface(cairo.FORMAT_RGB24, w, h)
with cairo.Context(surface) as context:
context.set_source_rgb(1, 1, 1) # White
context.paint()
# this font list works in CentOS 7
if multi_fonts:
fonts = [
'Century Schoolbook', 'Courier', 'STIX',
'URW Chancery L', 'FreeMono']
context.select_font_face(
np.random.choice(fonts),
cairo.FONT_SLANT_NORMAL,
np.random.choice([cairo.FONT_WEIGHT_BOLD, cairo.FONT_WEIGHT_NORMAL]))
else:
context.select_font_face('Courier',
cairo.FONT_SLANT_NORMAL,
cairo.FONT_WEIGHT_BOLD)
context.set_font_size(25)
box = context.text_extents(text)
border_w_h = (4, 4)
if box[2] > (w - 2 * border_w_h[1]) or box[3] > (h - 2 * border_w_h[0]):
raise IOError(('Could not fit string into image.'
'Max char count is too large for given image width.'))
# teach the RNN translational invariance by
# fitting text box randomly on canvas, with some room to rotate
max_shift_x = w - box[2] - border_w_h[0]
max_shift_y = h - box[3] - border_w_h[1]
top_left_x = np.random.randint(0, int(max_shift_x))
if ud:
top_left_y = np.random.randint(0, int(max_shift_y))
else:
top_left_y = h // 2
context.move_to(top_left_x - int(box[0]), top_left_y - int(box[1]))
context.set_source_rgb(0, 0, 0)
context.show_text(text)
buf = surface.get_data()
a = np.frombuffer(buf, np.uint8)
a.shape = (h, w, 4)
a = a[:, :, 0] # grab single channel
a = a.astype(np.float32) / 255
a = np.expand_dims(a, 0)
if rotate:
a = image.random_rotation(a, 3 * (w - top_left_x) / w + 1)
a = speckle(a)
return a
def shuffle_mats_or_lists(matrix_list, stop_ind=None):
ret = []
assert all([len(i) == len(matrix_list[0]) for i in matrix_list])
len_val = len(matrix_list[0])
if stop_ind is None:
stop_ind = len_val
assert stop_ind <= len_val
a = list(range(stop_ind))
np.random.shuffle(a)
a += list(range(stop_ind, len_val))
for mat in matrix_list:
if isinstance(mat, np.ndarray):
ret.append(mat[a])
elif isinstance(mat, list):
ret.append([mat[i] for i in a])
else:
raise TypeError('`shuffle_mats_or_lists` only supports '
'numpy.array and list objects.')
return ret
# Translation of characters to unique integer values
def text_to_labels(text):
ret = []
for char in text:
ret.append(alphabet.find(char))
return ret
# Reverse translation of numerical classes back to characters
def labels_to_text(labels):
ret = []
for c in labels:
if c == len(alphabet): # CTC Blank
ret.append("")
else:
ret.append(alphabet[c])
return "".join(ret)
# only a-z and space..probably not to difficult
# to expand to uppercase and symbols
def is_valid_str(in_str):
search = re.compile(regex, re.UNICODE).search
return bool(search(in_str))
# Uses generator functions to supply train/test with
# data. Image renderings and text are created on the fly
# each time with random perturbations
class TextImageGenerator(keras.callbacks.Callback):
def __init__(self, monogram_file, bigram_file, minibatch_size,
img_w, img_h, downsample_factor, val_split,
absolute_max_string_len=16):
self.minibatch_size = minibatch_size
self.img_w = img_w
self.img_h = img_h
self.monogram_file = monogram_file
self.bigram_file = bigram_file
self.downsample_factor = downsample_factor
self.val_split = val_split
self.blank_label = self.get_output_size() - 1
self.absolute_max_string_len = absolute_max_string_len
def get_output_size(self):
return len(alphabet) + 1
# num_words can be independent of the epoch size due to the use of generators
# as max_string_len grows, num_words can grow
def build_word_list(self, num_words, max_string_len=None, mono_fraction=0.5):
assert max_string_len <= self.absolute_max_string_len
assert num_words % self.minibatch_size == 0
assert (self.val_split * num_words) % self.minibatch_size == 0
self.num_words = num_words
self.string_list = [''] * self.num_words
tmp_string_list = []
self.max_string_len = max_string_len
self.Y_data = np.ones([self.num_words, self.absolute_max_string_len]) * -1
self.X_text = []
self.Y_len = [0] * self.num_words
def _is_length_of_word_valid(word):
return (max_string_len == -1 or
max_string_len is None or
len(word) <= max_string_len)
# monogram file is sorted by frequency in english speech
with codecs.open(self.monogram_file, mode='r', encoding='utf-8') as f:
for line in f:
if len(tmp_string_list) == int(self.num_words * mono_fraction):
break
word = line.rstrip()
if _is_length_of_word_valid(word):
tmp_string_list.append(word)
# bigram file contains common word pairings in english speech
with codecs.open(self.bigram_file, mode='r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
if len(tmp_string_list) == self.num_words:
break
columns = line.lower().split()
word = columns[0] + ' ' + columns[1]
if is_valid_str(word) and _is_length_of_word_valid(word):
tmp_string_list.append(word)
if len(tmp_string_list) != self.num_words:
raise IOError('Could not pull enough words'
'from supplied monogram and bigram files.')
# interlace to mix up the easy and hard words
self.string_list[::2] = tmp_string_list[:self.num_words // 2]
self.string_list[1::2] = tmp_string_list[self.num_words // 2:]
for i, word in enumerate(self.string_list):
self.Y_len[i] = len(word)
self.Y_data[i, 0:len(word)] = text_to_labels(word)
self.X_text.append(word)
self.Y_len = np.expand_dims(np.array(self.Y_len), 1)
self.cur_val_index = self.val_split
self.cur_train_index = 0
# each time an image is requested from train/val/test, a new random
# painting of the text is performed
def get_batch(self, index, size, train):
# width and height are backwards from typical Keras convention
# because width is the time dimension when it gets fed into the RNN
if K.image_data_format() == 'channels_first':
X_data = np.ones([size, 1, self.img_w, self.img_h])
else:
X_data = np.ones([size, self.img_w, self.img_h, 1])
labels = np.ones([size, self.absolute_max_string_len])
input_length = np.zeros([size, 1])
label_length = np.zeros([size, 1])
source_str = []
for i in range(size):
# Mix in some blank inputs. This seems to be important for
# achieving translational invariance
if train and i > size - 4:
if K.image_data_format() == 'channels_first':
X_data[i, 0, 0:self.img_w, :] = self.paint_func('')[0, :, :].T
else:
X_data[i, 0:self.img_w, :, 0] = self.paint_func('',)[0, :, :].T
labels[i, 0] = self.blank_label
input_length[i] = self.img_w // self.downsample_factor - 2
label_length[i] = 1
source_str.append('')
else:
if K.image_data_format() == 'channels_first':
X_data[i, 0, 0:self.img_w, :] = (
self.paint_func(self.X_text[index + i])[0, :, :].T)
else:
X_data[i, 0:self.img_w, :, 0] = (
self.paint_func(self.X_text[index + i])[0, :, :].T)
labels[i, :] = self.Y_data[index + i]
input_length[i] = self.img_w // self.downsample_factor - 2
label_length[i] = self.Y_len[index + i]
source_str.append(self.X_text[index + i])
inputs = {'the_input': X_data,
'the_labels': labels,
'input_length': input_length,
'label_length': label_length,
'source_str': source_str # used for visualization only
}
outputs = {'ctc': np.zeros([size])} # dummy data for dummy loss function
return (inputs, outputs)
def next_train(self):
while 1:
ret = self.get_batch(self.cur_train_index,
self.minibatch_size, train=True)
self.cur_train_index += self.minibatch_size
if self.cur_train_index >= self.val_split:
self.cur_train_index = self.cur_train_index % 32
(self.X_text, self.Y_data, self.Y_len) = shuffle_mats_or_lists(
[self.X_text, self.Y_data, self.Y_len], self.val_split)
yield ret
def next_val(self):
while 1:
ret = self.get_batch(self.cur_val_index,
self.minibatch_size, train=False)
self.cur_val_index += self.minibatch_size
if self.cur_val_index >= self.num_words:
self.cur_val_index = self.val_split + self.cur_val_index % 32
yield ret
def on_train_begin(self, logs={}):
self.build_word_list(16000, 4, 1)
self.paint_func = lambda text: paint_text(
text, self.img_w, self.img_h,
rotate=False, ud=False, multi_fonts=False)
def on_epoch_begin(self, epoch, logs={}):
# rebind the paint function to implement curriculum learning
if 3 <= epoch < 6:
self.paint_func = lambda text: paint_text(
text, self.img_w, self.img_h,
rotate=False, ud=True, multi_fonts=False)
elif 6 <= epoch < 9:
self.paint_func = lambda text: paint_text(
text, self.img_w, self.img_h,
rotate=False, ud=True, multi_fonts=True)
elif epoch >= 9:
self.paint_func = lambda text: paint_text(
text, self.img_w, self.img_h,
rotate=True, ud=True, multi_fonts=True)
if epoch >= 21 and self.max_string_len < 12:
self.build_word_list(32000, 12, 0.5)
# the actual loss calc occurs here despite it not being
# an internal Keras loss function
def ctc_lambda_func(args):
y_pred, labels, input_length, label_length = args
# the 2 is critical here since the first couple outputs of the RNN
# tend to be garbage:
y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
# For a real OCR application, this should be beam search with a dictionary
# and language model. For this example, best path is sufficient.
def decode_batch(test_func, word_batch):
out = test_func([word_batch])[0]
ret = []
for j in range(out.shape[0]):
out_best = list(np.argmax(out[j, 2:], 1))
out_best = [k for k, g in itertools.groupby(out_best)]
outstr = labels_to_text(out_best)
ret.append(outstr)
return ret
class VizCallback(keras.callbacks.Callback):
def __init__(self, run_name, test_func, text_img_gen, num_display_words=6):
self.test_func = test_func
self.output_dir = os.path.join(
OUTPUT_DIR, run_name)
self.text_img_gen = text_img_gen
self.num_display_words = num_display_words
if not os.path.exists(self.output_dir):
os.makedirs(self.output_dir)
def show_edit_distance(self, num):
num_left = num
mean_norm_ed = 0.0
mean_ed = 0.0
while num_left > 0:
word_batch = next(self.text_img_gen)[0]
num_proc = min(word_batch['the_input'].shape[0], num_left)
decoded_res = decode_batch(self.test_func,
word_batch['the_input'][0:num_proc])
for j in range(num_proc):
edit_dist = editdistance.eval(decoded_res[j],
word_batch['source_str'][j])
mean_ed += float(edit_dist)
mean_norm_ed += float(edit_dist) / len(word_batch['source_str'][j])
num_left -= num_proc
mean_norm_ed = mean_norm_ed / num
mean_ed = mean_ed / num
print('\nOut of %d samples: Mean edit distance:'
'%.3f Mean normalized edit distance: %0.3f'
% (num, mean_ed, mean_norm_ed))
def on_epoch_end(self, epoch, logs={}):
self.model.save_weights(
os.path.join(self.output_dir, 'weights%02d.h5' % (epoch)))
self.show_edit_distance(256)
word_batch = next(self.text_img_gen)[0]
res = decode_batch(self.test_func,
word_batch['the_input'][0:self.num_display_words])
if word_batch['the_input'][0].shape[0] < 256:
cols = 2
else:
cols = 1
for i in range(self.num_display_words):
pylab.subplot(self.num_display_words // cols, cols, i + 1)
if K.image_data_format() == 'channels_first':
the_input = word_batch['the_input'][i, 0, :, :]
else:
the_input = word_batch['the_input'][i, :, :, 0]
pylab.imshow(the_input.T, cmap='Greys_r')
pylab.xlabel(
'Truth = \'%s\'\nDecoded = \'%s\'' %
(word_batch['source_str'][i], res[i]))
fig = pylab.gcf()
fig.set_size_inches(10, 13)
pylab.savefig(os.path.join(self.output_dir, 'e%02d.png' % (epoch)))
pylab.close()
def train(run_name, start_epoch, stop_epoch, img_w):
# Input Parameters
img_h = 64
words_per_epoch = 16000
val_split = 0.2
val_words = int(words_per_epoch * (val_split))
# Network parameters
conv_filters = 16
kernel_size = (3, 3)
pool_size = 2
time_dense_size = 32
rnn_size = 512
minibatch_size = 32
if K.image_data_format() == 'channels_first':
input_shape = (1, img_w, img_h)
else:
input_shape = (img_w, img_h, 1)
fdir = os.path.dirname(
get_file('wordlists.tgz',
origin='http://www.mythic-ai.com/datasets/wordlists.tgz',
untar=True))
img_gen = TextImageGenerator(
monogram_file=os.path.join(fdir, 'wordlist_mono_clean.txt'),
bigram_file=os.path.join(fdir, 'wordlist_bi_clean.txt'),
minibatch_size=minibatch_size,
img_w=img_w,
img_h=img_h,
downsample_factor=(pool_size ** 2),
val_split=words_per_epoch - val_words)
act = 'relu'
input_data = Input(name='the_input', shape=input_shape, dtype='float32')
inner = Conv2D(conv_filters, kernel_size, padding='same',
activation=act, kernel_initializer='he_normal',
name='conv1')(input_data)
inner = MaxPooling2D(pool_size=(pool_size, pool_size), name='max1')(inner)
inner = Conv2D(conv_filters, kernel_size, padding='same',
activation=act, kernel_initializer='he_normal',
name='conv2')(inner)
inner = MaxPooling2D(pool_size=(pool_size, pool_size), name='max2')(inner)
conv_to_rnn_dims = (img_w // (pool_size ** 2),
(img_h // (pool_size ** 2)) * conv_filters)
inner = Reshape(target_shape=conv_to_rnn_dims, name='reshape')(inner)
# cuts down input size going into RNN:
inner = Dense(time_dense_size, activation=act, name='dense1')(inner)
# Two layers of bidirectional GRUs
# GRU seems to work as well, if not better than LSTM:
gru_1 = GRU(rnn_size, return_sequences=True,
kernel_initializer='he_normal', name='gru1')(inner)
gru_1b = GRU(rnn_size, return_sequences=True,
go_backwards=True, kernel_initializer='he_normal',
name='gru1_b')(inner)
gru1_merged = add([gru_1, gru_1b])
gru_2 = GRU(rnn_size, return_sequences=True,
kernel_initializer='he_normal', name='gru2')(gru1_merged)
gru_2b = GRU(rnn_size, return_sequences=True, go_backwards=True,
kernel_initializer='he_normal', name='gru2_b')(gru1_merged)
# transforms RNN output to character activations:
inner = Dense(img_gen.get_output_size(), kernel_initializer='he_normal',
name='dense2')(concatenate([gru_2, gru_2b]))
y_pred = Activation('softmax', name='softmax')(inner)
Model(inputs=input_data, outputs=y_pred).summary()
labels = Input(name='the_labels',
shape=[img_gen.absolute_max_string_len], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
# Keras doesn't currently support loss funcs with extra parameters
# so CTC loss is implemented in a lambda layer
loss_out = Lambda(
ctc_lambda_func, output_shape=(1,),
name='ctc')([y_pred, labels, input_length, label_length])
# clipnorm seems to speeds up convergence
sgd = SGD(lr=0.02, decay=1e-6, momentum=0.9, nesterov=True, clipnorm=5)
model = Model(inputs=[input_data, labels, input_length, label_length],
outputs=loss_out)
# the loss calc occurs elsewhere, so use a dummy lambda func for the loss
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=sgd)
if start_epoch > 0:
weight_file = os.path.join(
OUTPUT_DIR,
os.path.join(run_name, 'weights%02d.h5' % (start_epoch - 1)))
model.load_weights(weight_file)
# captures output of softmax so we can decode the output during visualization
test_func = K.function([input_data], [y_pred])
viz_cb = VizCallback(run_name, test_func, img_gen.next_val())
model.fit_generator(
generator=img_gen.next_train(),
steps_per_epoch=(words_per_epoch - val_words) // minibatch_size,
epochs=stop_epoch,
validation_data=img_gen.next_val(),
validation_steps=val_words // minibatch_size,
callbacks=[viz_cb, img_gen],
initial_epoch=start_epoch)
if __name__ == '__main__':
run_name = datetime.datetime.now().strftime('%Y:%m:%d:%H:%M:%S')
train(run_name, 0, 20, 128)
# increase to wider images and start at epoch 20.
# The learned weights are reloaded
train(run_name, 20, 25, 512)
Read full-text »
[CS229] 17: Large Scale Machine Learning
2018-12-19
17: Large Scale Machine Learning
- 为什么需要大的数据集?
- 模型取的好效果的最佳途径:小偏差的算法,在大数据上训练
- 当数据集足够大时,不同的算法,效果相当
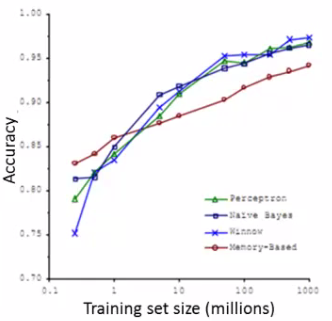
- 问题:大数据集带来的计算问题,计算资源消耗巨大
- 大数据集的学习:
- 训练是需要优化参数,计算误差,下图是逻辑回归单个样本的误差,如果是大数据集(比如样本数m=1000000),需要计算1000000次。这个计算加和的过程本身就很耗计算资源:

- 可能解决方案:1)使用其他的方法,2)优化避免加和操作
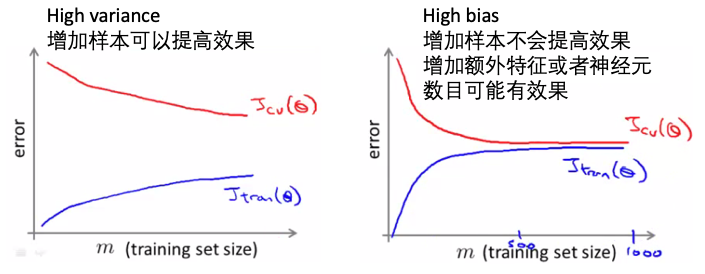
- 优先考虑:小数据集训练。通常可能效果不好,有的能到达跟大数据集相当的效果。如何评估小数据集是否足够,可以看学习曲线(训练集数量 vs 误差):
- 训练是需要优化参数,计算误差,下图是逻辑回归单个样本的误差,如果是大数据集(比如样本数m=1000000),需要计算1000000次。这个计算加和的过程本身就很耗计算资源:
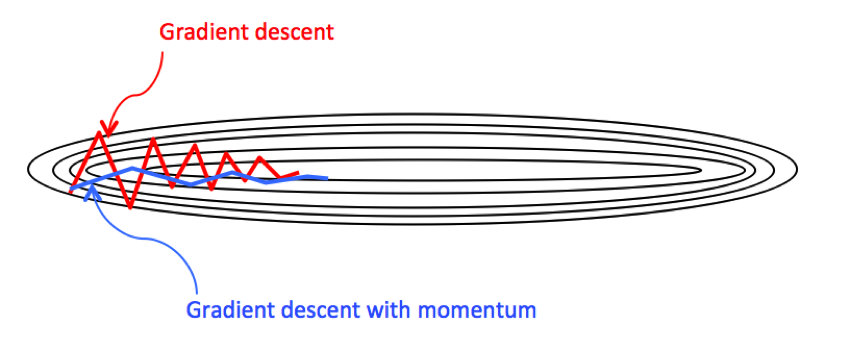
- batch梯度下降:
- 损失函数(这里以线性回归为例):
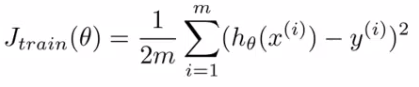
- 在优化时,梯度下降要应用于每一个参数\(\theta\),而其更新的大小,根据下面的公式,是要依赖于所有的样本的(每个样本都要贡献于这个梯度的更新):
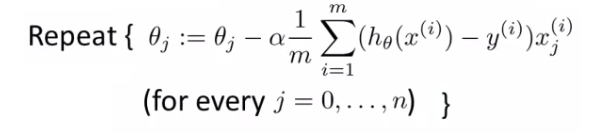
- 优点:能够达到全局最小
- 缺点:同时要看所有的样本,计算消耗大
- 损失函数(这里以线性回归为例):
- 随机梯度下降:
- 单个样本的损失(只看\(\theta\)在单个样本上的损失表示):

- 总的损失(和上面的batch梯度递减的损失函数是一样的,最终的目的是一样的):

- 算法步骤1:训练集数据随机打乱。保证\(\theta\)的移动是不存在bias的。
- 算法步骤2:从1到m(样本数),每次更新所有的\(\theta\),但是这里的\(\theta\)是只与一个样本有关的【update the parameters on EVERY step through data】。\(\theta\)值在不断的优化,但是每次都是对于一个样本最优,不是对全部样本最优:

- 下面是批梯度下降和随机梯度下降的比较:
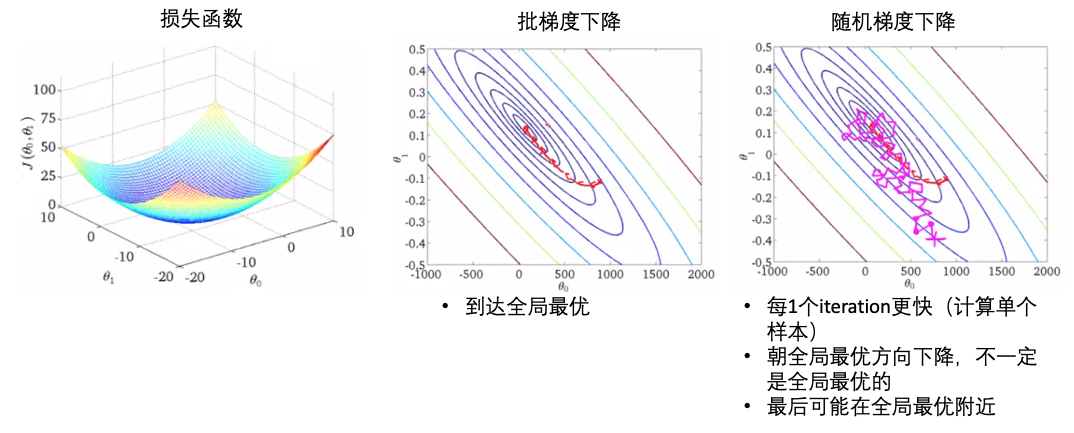
- SGD不一定能到达全局最优,可以运行多次在整个数据集上。
- 单个样本的损失(只看\(\theta\)在单个样本上的损失表示):
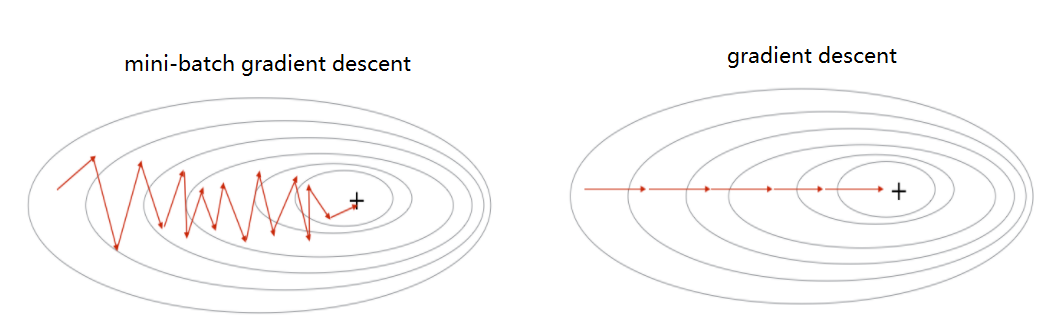
- 小批量梯度下降(mini-batch):
- 小批量 vs 随机梯度下降:
- 向量化计算,实现更高效,并行计算
- 需要优化参数b(batch size)
- 随机梯度和批量梯度下降都是小批量梯度下降的特例
- 随机梯度下降的收敛:
- 【批量梯度下降】:直接看每一次的迭代
- 【随机梯度下降】:比如可以看每1000次的迭代的损失变化
- 检查学习曲线:迭代次数 vs loss,看模型随迭代次数的收敛情况:
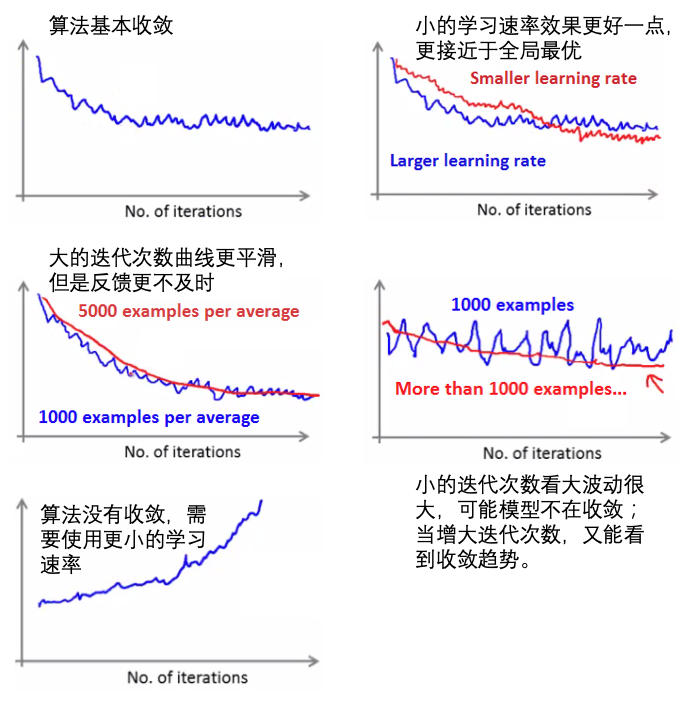
- 学习速率:
- SGD中的学习速率通常比批地图下降更小,因为SGD的梯度更新的差异性(variance)更大(每次都是随机选取一个样本?)。
- 通常学习速率是常量,但是为了达到全局最优,可以缓慢的减小学习速率
- 通常:α = const1/(iterationNumber + const2)
- 在线学习(online learning):
- 持续的数据流
- 例子1:物流价格的确定。有一个在线的服务,记录什么样的价格,物品等(作为特征)可以保证交易的成果。不断有新的订单,作为新的数据更新模型。
- 例子2:商品搜索。根据搜索关键词呈现10个商品,是否继续点击(click through rate,CTR),从而收集数据和标签,更新训练模型。
- Map reduce:
- 基本框架:

- 在梯度下降的计算中:

- Hadoop:a good open source Map Reduce implementation
- 基本框架:
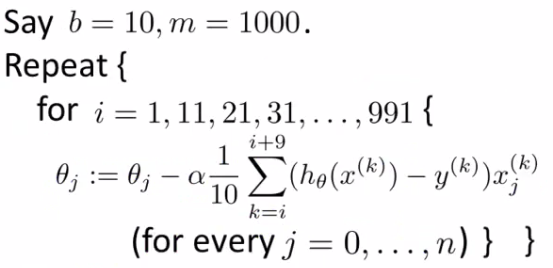
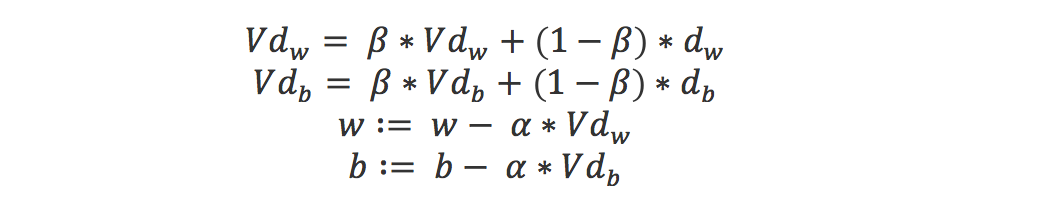
Read full-text »
Stanford deep learning
2018-12-17
课程信息
- Official UFLDL Tutorial @ Stanford: http://deeplearning.stanford.edu/tutorial
- Code for all the exercises: forked from amaas @ github
Read full-text »
[CS229] 16: Recommender Systems
2018-12-15
16: Recommender Systems
- 推荐系统:尝试鉴定重要而相关的特征
- 重要的机器学习应用,在工业界其很大的作用
- 其思想很重要,说明了通过模型学习能知道哪些特征的重要性
- 例子:预测对电影的评分
- 不同用户(用户数目:\(n_u\))对不同电影(电影数目\(\begin{align} n_m \end{align}\))的评价(\(\begin{align} y^{ij} \end{align}\)),评价与否:\(r(i,j)\)评价即为1.
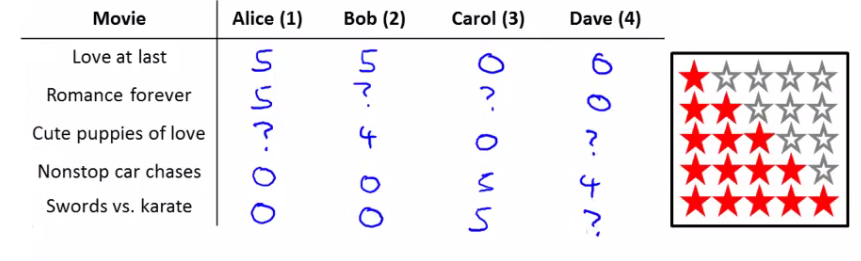
- 问题描述:对于给定的\(r(i,j)\)和\(\begin{align} y^{ij} \end{align}\),预测表格中的缺失值(用户对电影的评价值)。
- 不同用户(用户数目:\(n_u\))对不同电影(电影数目\(\begin{align} n_m \end{align}\))的评价(\(\begin{align} y^{ij} \end{align}\)),评价与否:\(r(i,j)\)评价即为1.
- 基于(电影)内容的推荐(content-based approach):
- 假如电影是有内容标签的,那么每个电影可用一个特征向量表示:
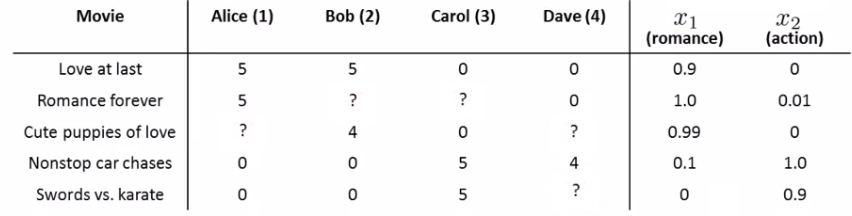
- 单独对待每一位用户,因为不同的用户评价是不同的,所以推荐也是不同的
- 对于每个用户\(j\),需要学习一个参数向量,有了参数向量之后,就可以预测这个用户对某个其未评价过的电影的评价:评价=\({(\theta^j)}^T X^i\) 【特征向量和参数向量的內积】
- 假如电影是有内容标签的,那么每个电影可用一个特征向量表示:
- 如何学习参数向量(\(\theta^j\)):
- 关于\(\theta\)的目标优化函数(使得预测的评价和真实的评价尽可能接近):
- 对于某个用户,对其所参与评价的电影,计算预测误差(类似于线性回归的最小平方差),同时添加一个正则项:

- 这就是基于内容的,因为有X特征向量,基于这个向用户推荐其他可能感兴趣的电影。
- 协同过滤(collaborative filtering):
- 特性:自行学习什么样的特征是需要学习的
- 基于内容的假设:电影的特征标签是已知的
- 这里的协同过滤:对于电影的任何特征标签是不知道的
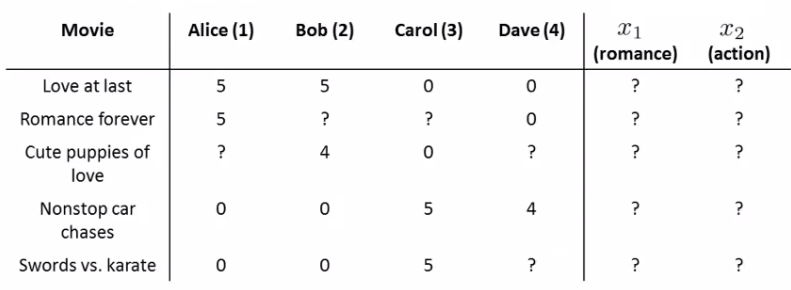
- 协同过滤的假设:调查了用户,获得了用户的喜好 。比如几位用户的喜好特征向量([爱情片,动作片,其他])如下:
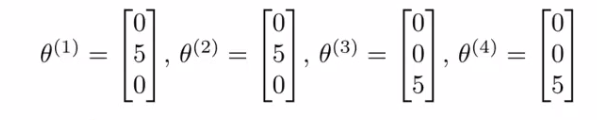
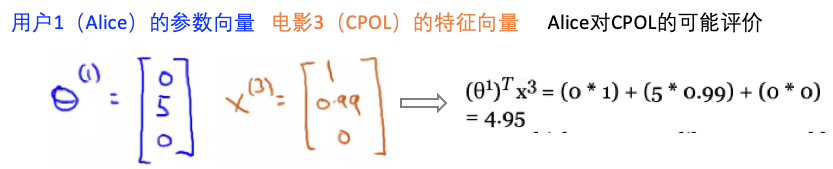
- 【直观】从这里可知,用户1、2喜好爱情片,同时从表中看到用户1、2也喜欢第一个电影(评价很高5颗星),所以推测第一个电影”Love at Last“是一个爱情片。
- 【目标】找到电影1的特征向量\(x^1\),使得\((\theta^1)^T x^1=5\), \((\theta^2)^T x^1=5\), \((\theta^3)^T x^1=0\), \((\theta^4)^T x^1=0\).
- 同理,可以求得其他电影对应的特征向量
- 协同过滤公式化:
- 给定用户的喜好(参数)向量,求解每个电影对应的特征向量,最小化下面的损失函数(这里的损失函数和上面的基于内容的是一样的,都是为了最小化预测偏差,只是这里我们知道的是用户的参数偏好向量,要求得电影的特征向量):
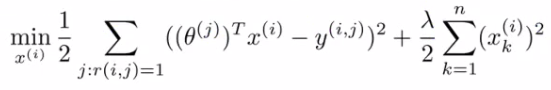
- 给定用户的喜好(参数)向量,求解每个电影对应的特征向量,最小化下面的损失函数(这里的损失函数和上面的基于内容的是一样的,都是为了最小化预测偏差,只是这里我们知道的是用户的参数偏好向量,要求得电影的特征向量):
- 结合起来:
- 基于内容:已知电影的特征向量,学习用户的喜好
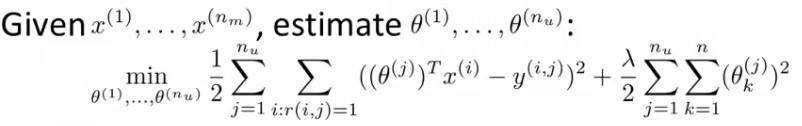
- 协同过滤:已知用户的喜好,学习电影的特征向量
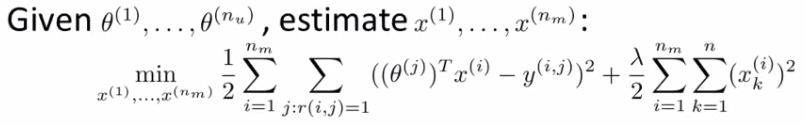
- 实际操作:1)随机初始化用户的喜好向量\(\theta\),2)使用协同过滤的方式学习电影的特征向量 \(X\),3)使用基于内容的方式提高\(\theta\),4)然后再提高\(X\),如此反复。
- 为啥叫协同过滤:用户参与进来,一起帮助学习算法更好的学习特征
- 基于内容:已知电影的特征向量,学习用户的喜好
- 协同过滤的一步化:
- 上面的实际操作是\(\theta\)和\(X\)分别交替学习优化的,有没有一步化的方式更高效的可以同时学习的方式?
- 如下,同时优化\(\theta\)和\(X\):
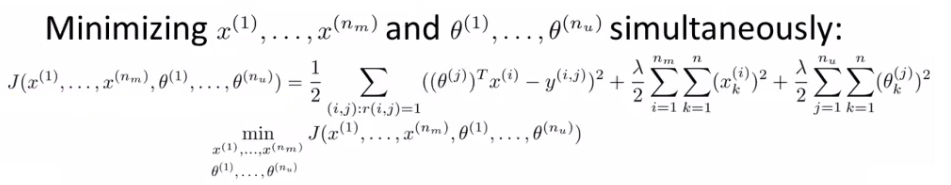
- 协同过滤的一步化的算法结构:
- 1)用较小的值随机初始化用户的喜好向量\(\theta\)和电影的特征向量\(X\)(类似于神经网络)
- 2)使用梯度下降法优化上面的损失函数(同时优化\(\theta\)和\(X\))
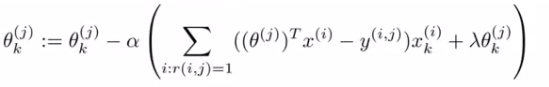
- 3)当达到最小损失时,就求得了用户的喜好向量和电影的特征向量。
- 4)对于某个用户对某个某个电影的评价,就可以通过公式求得:评价=\({(\theta^j)}^T X^i\)
- 以向量的形式求解偏好向量和特征向量:
- 用户对于电影的评价是知道的,所有Y向量已知,然后构建用户的偏好向量和电影的特征向量,其內积就是预测的评价,最小化预测评价与真实评价之间的损失:
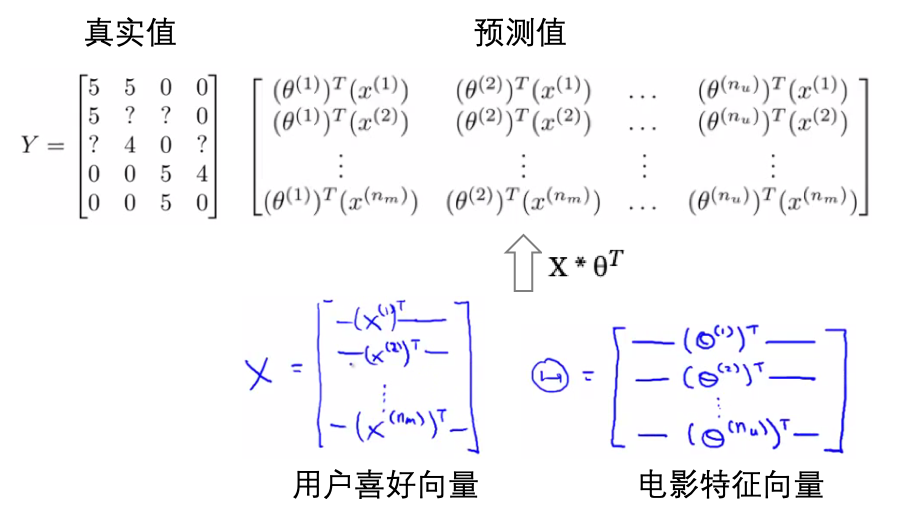
- 用户对于电影的评价是知道的,所有Y向量已知,然后构建用户的偏好向量和电影的特征向量,其內积就是预测的评价,最小化预测评价与真实评价之间的损失:
- 如何推荐电影:
- 通过上面的协同过滤算法,我们可以得到用户的偏好向量和电影的特征向量,但是还没有实现向用户推荐电影,如何推荐?
- 计算电影的相似性:现在每个电影的特征是知道的,对于某用户评价高的电影,计算其他电影与这个电影的相似性,相似性高的就推荐。
- 两个电影的特征向量:\(x^i\), \(x^j\), 最小化:\(x^i-x^j\),即两个电影之间的距离
- 均值归一化(为什么需要):

- 这里用户5Eve没有做任何的评价
- 假如n=2,我们要学习用户5Eve的喜好向量\(\theta5\)。下面是其损失函数,这里没有做任何评价,所以r(i,j)=1的是没有的,第一项可以忽略。优化最后的正则项,这里假设的是两个电影,所以损失是:\(\lambda/2[{\theta^5_1}^2 + {\theta^5_2}^2]\),要使得这个最小,那么\(\theta5=[0,0]\)

- 【问题】这样一来,对于任何电影,所有的预测值都是0(不喜欢任何电影)。
- 均值归一化:
- 首先计算每个电影的平均评价,然后对于原始的评价进行均值归一化
- 预测评价=\({(\theta^j)}^T X^ + u_i\)
- 同样的求得\(\theta5=[0,0]\),所以对任何电影,其评价得分(=0+\(u_i\))就是该电影的平均评价得分(这个是基于其他人对这个电影的评价)。
Read full-text »
Outliner Detection
2018-12-13
不同的方法
参考:
数字异常值(Numeric Outlier)
原理:计算1、3分位值Q1、Q3,位于四分位范围之外的[Q1-k*IQR, Q3+k*IQR]就是异常值,其中IQR=Q3-Q1。
特点:
- 一维特征空间中最简单的非参数异常值检测
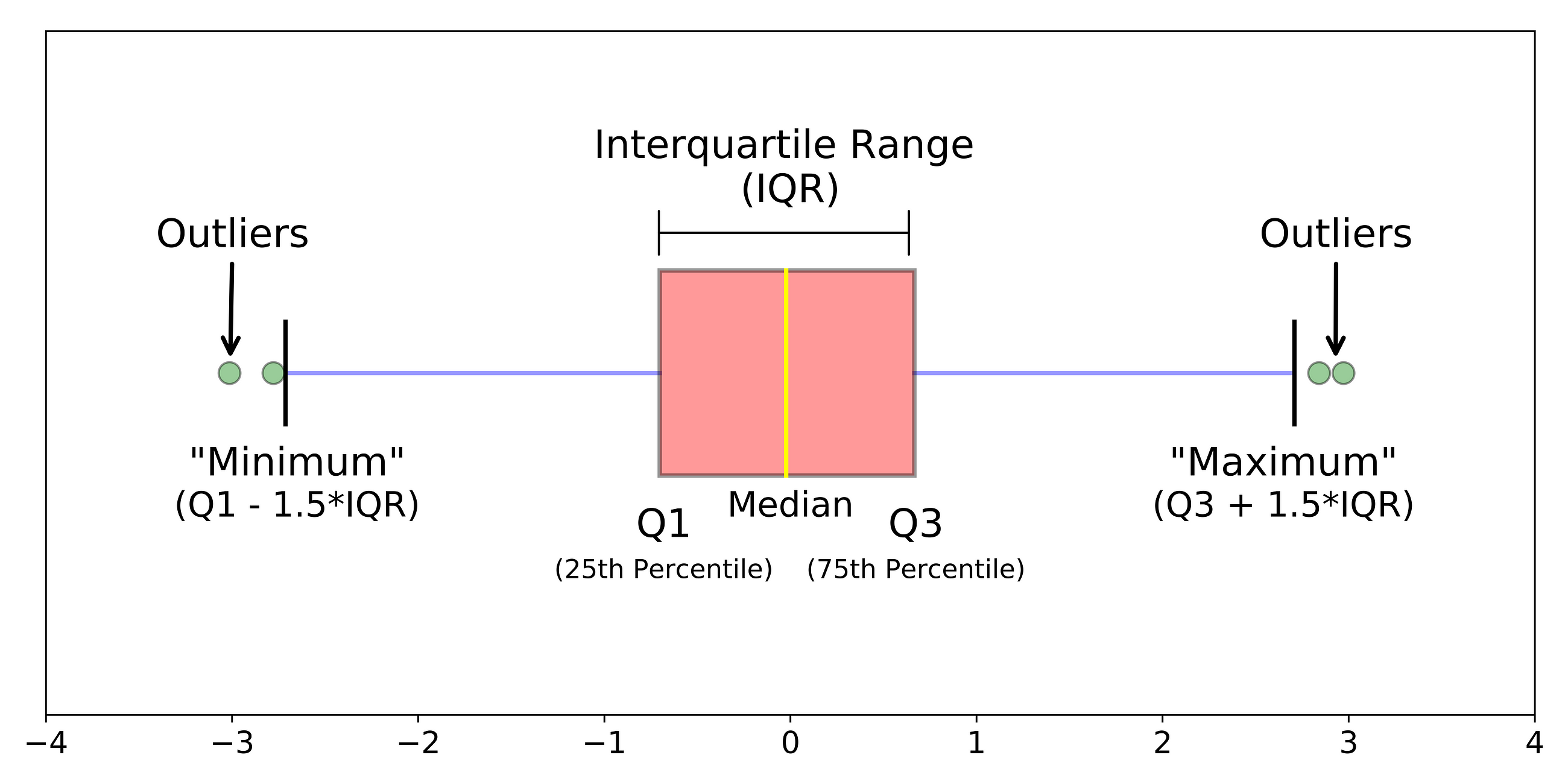
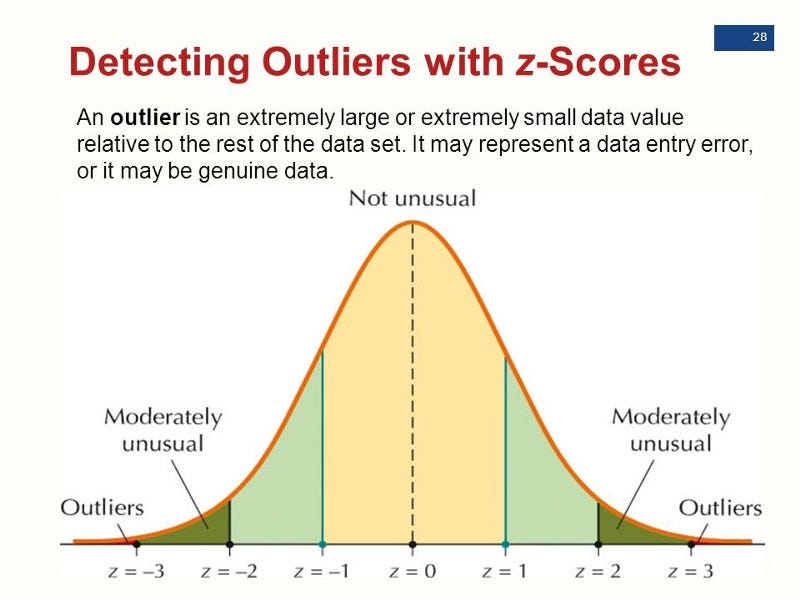
Z-score(统计假设检验)
原理:假定数据是服从高斯分布的,那么在分布尾端的就是异常值。
特点:
- 一维或者低维空间
- 维度灾难:随着维度越来越高,数据点的距离会越来越近。
- 特征服从高斯分布
DBSCAN
原理:根据给定的参数(最小包含点数、距离度量),计算不同点之间的距离,将点分为3类:核心点、边界点、噪声点
- 核心点(core points):在距离ℇ内至少具有最小包含点数个其他店的数据点
- 边界点(border points):核心点的距离ℇ内邻近点,但包含的点数小于最小包含点数个
- 噪声点:所有不属于上述的其他数据点,也是异常值
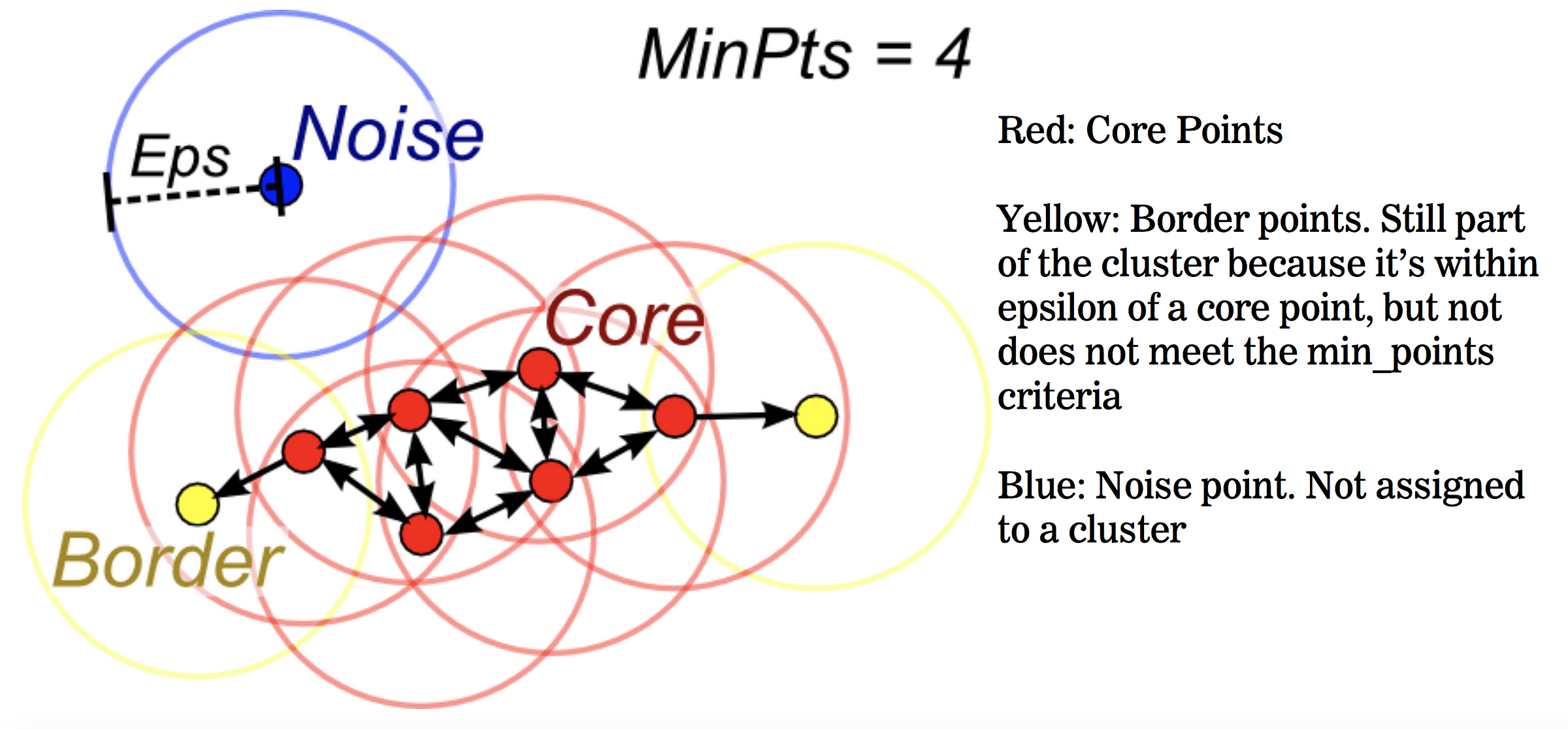
特点:
- 一维或者高维空间
- 基于密度的非参数检测
- 属于一种聚类方法
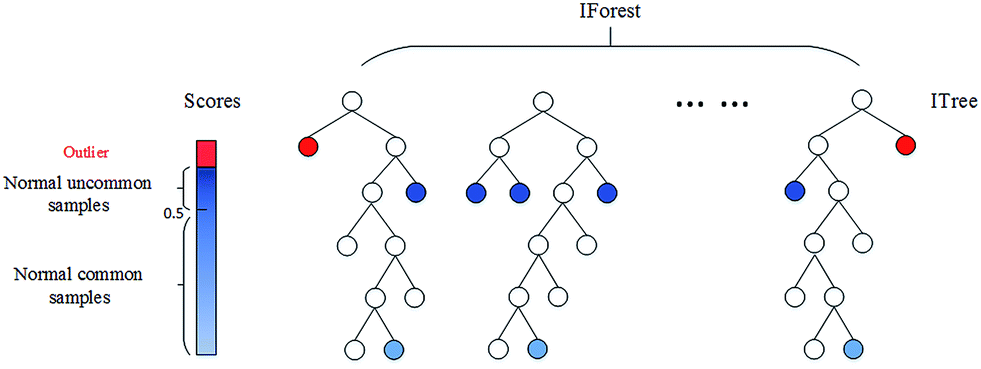
孤立森林(Isolation Forest)
原理: 通过计算每个数据点的孤立数,孤立数低于阈值的点确定异常点。
- 孤立数:孤立数据点所需的拆分数
- 选取一个点A
- 在【最小值,最大值】间选取随机点B
- 如果B值<A值,则B值变为新的下限
- 如果B值>A值,则B值变为新的上限
- 在上下限之间存在除了A之外的其他数据点,就重复该过程,直到A点完全孤立
- 异常值:孤立数更小(更少的次数即可被分隔出来)
- 算法步骤(参考):
- 1、训练:从训练集中采样,构建iTree数。
- 【1】从n个样本中不放回的随机选取m个样本,作为树的训练样本。
- 【2】从此样本中,随机选取一个特征,并随机选取一个值,对样本进行二叉划分。小于该值的在树左边,大于该值的在树右边。树的终止条件:1)数据不可再分;2)树的高度达到log2(m)。
- 2、测试:对于测试样本,用构建的每颗iTree树进行测试,记录path长度,然后基于所有的path长度计算测试样本的异常分数:\(s(x,n) = 2^{(-\frac{E( { h(x) })} { c(n) } )}\), \(c(n) = 2H(n − 1) − (2(n − 1)/n)\) 是二叉搜索树的平均路径长度,\(H(k) = ln(k) + \xi\),\(\xi\)是欧拉常数,其值为0.5772156649。
- 1、训练:从训练集中采样,构建iTree数。
特点:
- 一维或者多维、大数据集、非参数检测
- 基于相似性
- 无需计算基于点的距离
- 基于数据点,构建一堆随机树,通常异常点位于更靠近根节点(具有最短平均路径)的地方
PCA
原理:假设数据在低维空间上有嵌入,那么无法、或者在低维空间投射后表现不好的数据可以认为是离群点。
- 【方法1】:找k个特征向量,计算投射后的重建误差,正常点的重建误差应该小于异常点
- 【方法2】:找k个特征向量,计算每个样本到这k个选特征向量所构成的超空间的加权欧氏距离,正常点的这个距离应该是小于异常点的
- 【方法3】:直接分析协方差矩阵,计算每个样本的马氏距离(样本到分布中心的距离),正常点的距离小于异常点。【soft PCA】
特点:
- 线性模型
MCD(Minimum Covariance Determinant)
原理:用椭圆去包含一半的数据点,使得方差最小。
特点:
- 基于线性

OCSVM(One-Class Support Vector Machines)
原理:训练集中只有一类样本,学习一个边界,包含所有的数据点。
特点:
- 学习的是边界,不同于SVM学习的分隔超平面
- 基于线性

LOF(Local Outlier Factor)
原理:通过局部的密度分布进行检测,异常点的局部密度值低于正常点。
特点:
- 基于相似性
- 局部数据密度(跟其最近邻的点的平均局部数据密度)

kNN(k Nearest Neighbors)
原理:样本与其k近邻的数据点的距离可以作为异常值,异常点的这个距离值更大。
特点:
- 基于相似性

HBOS(Histogram-based Outlier Score)
原理:计算每个数据点,各个特征的值所在的特征所在bin的总和。
特点:
- 基于概率
- 假设特征之间是相互独立的

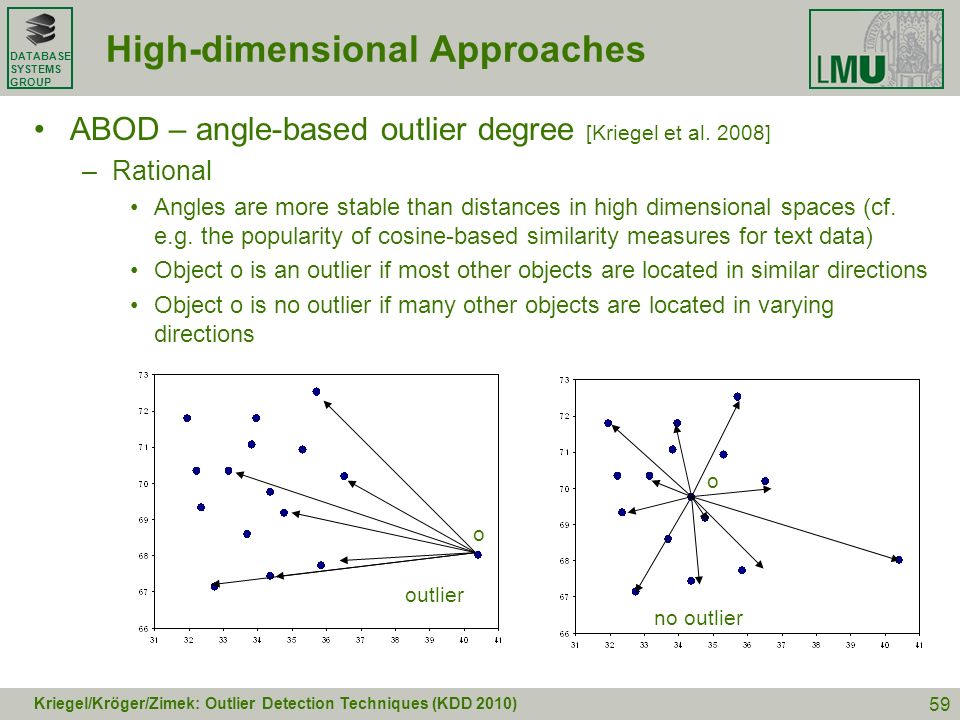
FastABOD(Fast Angle-Based Outlier Detection using approximation)
原理:计算每个样本与其他所有样本所形成夹角的方差,异常点的方差小(因为距离其他点都比较远)
特点:
- 基于相似性
Feature Bagging
原理:随机选择特征子集来构建n个子样本,在数据集的各个子样本上安装多个基本检测器,使用平均或其他组合方法来提高预测精度。
特点:
- 可以使用不同的基本检测模型
- 集成型的算法
- “对feature和data进行bagging之后再利用多种模型输出异常分值,或加权或平均,或者干脆加入到原始特征里,都是比较有效的方法,在实际应用中,模型的精度和召回都提高了五个百分点以上”
Read full-text »
Python module sklearn
2018-12-11
python scikit-learn

Read full-text »
[CS229] 15: Anomaly Detection
2018-12-11
15: Anomaly Detection
- 异常检测:主要用于非监督学习问题。根据很多样本及其特征,鉴定可能异常的样本,比如产品出厂前进行质量控制测试(QA)。
- 对于给定的正常数据集,想知道一个新的数据是不是异常的,即这个测试数据不属于该组数据的几率,比如在某个范围内概率很大(正常样本),范围之外的几率很小(异常样本),这种属于密度估计。
- 高斯分布:常见的一个分布,刻画特征的情况:
- 两个参数:期望和方差
- 两个参数:期望和方差
- 利用高斯分布进行异常检测:
- 对于给定数据集,对每一个特征计算高斯分布的期望和方差(知道了每个特征的密度分布函数)
- 对新数据集,基于所有特征的密度分布,计算属于此数据集的概率
- 当计算的P小于ε时,为异常。(这个ε怎么定?)
- 开发和评估:
- 异常检测系统,先从带标记的数据选取部分构建训练集,获得概率分布模型;然后用剩下的正样本和异常数据构建交叉检验集和测试集。
- 测试集:估计每个特征的平均值和方差,构建概率计算函数
- 检验集:使用不同的ε作为阈值,看模型的效果。主要用来确定模型的效果,具体就是ε值大小。
- 测试集:用选定的ε阈值,针对测试集,计算异常检验系统的F1值等。
- 注意1:数据。训练集只有正常样本(label为0),但是为了评估系统性能,需要异常样本(label为1)。所以需要一批label的样本。
- 注意2:评估。正负样本严重不均衡,不能使用简单的错误率来评估(skewed class),需要用precision、recal、F-measure等度量。
- 异常检测 vs 监督学习:
- 数据量:前者负样本(异常的)很多
- 数据分布:异常检测的负样本(正常样本)分布很均匀,认为服从高斯分布,但是正样本是各种各样的(不正常的各有各的奇葩之处)
- 模型训练:鉴于异常样本的数量少,且不均匀,所以不能用于算法学习。所以异常样本:不参与训练,没有参与高斯模型拟合,只是在验证集和测试集中进行模型的评估。
- 特征选择(转换):
- 特征不服从高斯分布,异常检测算法也可以工作
- 最好转换为高斯分布:比如对数函数变换 =》x=log(x+c)
- 比如在某一维度时,某个样本对应的概率处于正常和异常的附近,很可能判断错误,可以通过查看其在其他维度(特征)的信息,以确定其是否异常。
- 误差分析:
- 问题:异常的数据有较高的P(x)值,被认为是正常的
- 只看被错误检测为正常的异常样本,看是否需要增加其他的特征,以检测这部分异常
- 多元高斯分布:
- 一般高斯计算P(x): 分别计算每个特征对应的几率然后将其累乘起来
- 多元高斯计算P(x): 构建特征的协方差矩阵,用所有的特征一起来计算
- 问题:一般高斯的判定边界比较大,有时候会把样本中的异常分布判定为正常样本
- 协方差矩阵对高斯分布的影响:
- 一般高斯 vs 多元高斯:
- 应用多元高斯构建异常检测系统:
- 原始模型 vs 多元高斯模型:
- 原始模型 vs 多元高斯模型:
- 以上参考这里的学习笔记
Read full-text »
Latest articles
Links
- ZhangLab , RISE database , THU life , THU info
- Data analysis: pandas , numpy , scipy
- ML/DL: sklearn , sklearn(中文) , pytorch
- Visualization: seaborn , matplotlib , gallery
- Github: me